
Building the Interpreter — When the Tree Starts Running
We have tokens and a syntax tree. Now we make it do something. Walking the AST, managing environments, and discovering that execution is where meaning actually lives.

Parsing felt like the summit.
Three chapters of grammar rules, token types, recursive descent, precedence climbing. By the time the parser produced a clean abstract syntax tree from raw text, it felt like the mountain had been climbed. The hard thinking was done.
Turns out, that was base camp.
A syntax tree is a beautifully precise description of structure. It tells you what the programmer wrote — the nesting, the grouping, the operator relationships. But it tells you nothing about what any of it means. An expression node that says Binary(Literal(3), Plus, Literal(4)) is just data. It doesn't know that plus means addition. It doesn't know that the result should be 7. That knowledge lives somewhere else entirely.
It lives in the interpreter.
The translation problem
There's a process in molecular biology called translation. After DNA has been transcribed into messenger RNA — a structural copy of the genetic code — the ribosome walks along that mRNA strand, reading it three nucleotides at a time. Each triplet, called a codon, maps to a specific amino acid. The ribosome doesn't understand the mRNA. It doesn't have opinions about it. It just walks the structure, node by node, and produces something that does things in the physical world: a protein.
Our interpreter is the ribosome.
And the parallel runs deeper than you might expect. The ribosome doesn't read mRNA blindly — it uses transfer RNA molecules (tRNAs) that act as adapters, each one matching a specific codon to a specific amino acid. The codon GCU always maps to alanine. The codon UUU always maps to phenylalanine. The tRNA is the switch statement of molecular biology — a lookup from structure to behavior. Our interpreter does exactly this: a switch on the AST node type maps Binary to arithmetic, Literal to a raw value, IfStmt to conditional branching. Different syntax, same principle. A finite set of structural patterns, each bound to a specific operation.
Ribosomes can also stall. When they encounter a rare codon — one that the cell doesn't have many matching tRNAs for — translation slows or pauses. The machinery is correct but the input triggers an exceptional case. Our interpreter has the same failure mode: a variable name that doesn't exist in any environment, a division where the right operand is zero. The structure is valid. The semantics are broken. Execution stalls.
And here's one more layer: after the ribosome finishes, the protein it produced isn't necessarily final. Post-translational modifications — phosphorylation, glycosylation, cleavage — change the protein's behavior after it's been built. The ribosome's output is mutable. So is ours. A variable defined as 10 can be reassigned to "hello" on the very next line. The initial creation is just the beginning of the value's life.
The parser gave us a syntax tree — the structural copy. Now we need something that walks that tree, node by node, and produces behavior. An IfStmt node needs to evaluate a condition and choose a branch. A Binary node needs to perform arithmetic. A VarDecl node needs to store a value somewhere it can be retrieved later.
The syntax tree describes what was written. The interpreter decides what it means.
What separates structure from meaning is what separates syntax from semantics, and it turns out that terrain is where all the interesting problems live.
Where variables live
Before we can evaluate a single expression, we need to answer a deceptively simple question: where do variables go?
When the interpreter encounters var x = 10;, it needs to record that x holds the value 10. When it later encounters print x + 5;, it needs to look up what x means. And when it enters a block like { var x = 20; print x; }, the inner x needs to shadow the outer one without destroying it.
The answer is an Environment — a dictionary of bindings with an optional reference to a parent environment.
public class Environment
{
private readonly Dictionary<string, object?> _values = new();
private readonly Environment? _enclosing;
public Environment(Environment? enclosing = null)
{
_enclosing = enclosing;
}
public void Define(string name, object? value)
{
_values[name] = value;
}
public object? Get(Token name)
{
if (_values.TryGetValue(name.Lexeme, out var value))
return value;
if (_enclosing is not null)
return _enclosing.Get(name);
throw new RuntimeError(name, $"Undefined variable '{name.Lexeme}'.");
}
public void Assign(Token name, object? value)
{
if (_values.ContainsKey(name.Lexeme))
{
_values[name.Lexeme] = value;
return;
}
if (_enclosing is not null)
{
_enclosing.Assign(name, value);
return;
}
throw new RuntimeError(name, $"Undefined variable '{name.Lexeme}'.");
}
}The Get and Assign methods both walk up the environment chain. If the current scope doesn't have the variable, ask the parent. If the parent doesn't have it, ask the grandparent. If nobody has it, that's a runtime error.
This chain is how lexical scoping works. Every block creates a new environment that encloses the current one. When the block ends, the environment is discarded, and the enclosing one becomes current again. Variables defined inside the block vanish. Variables defined outside remain untouched.
It's a linked list of dictionaries, and it's enough to model the scoping rules of most programming languages.
The runtime error
Before we go further, we need a way to signal problems. Parsing errors are syntax problems — the code was malformed. Runtime errors are semantic problems — the code was well-formed but wrong.
public class RuntimeError : Exception
{
public Token Token { get; }
public RuntimeError(Token token, string message) : base(message)
{
Token = token;
}
}Dividing by zero. Adding a number to a string. Using a variable that was never defined. These are all structurally valid — the parser accepts them without complaint. Only the interpreter knows they're broken, because only the interpreter knows what the operations mean.
Walking the tree
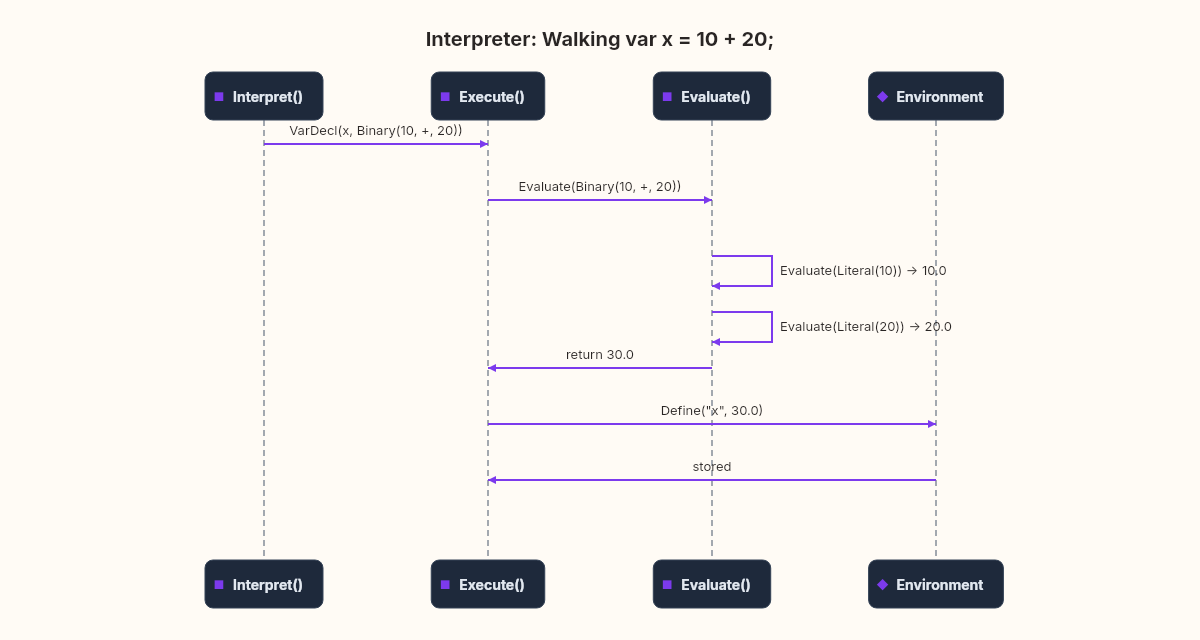
The interpreter itself is a single class with two core methods: one that evaluates expressions (returns a value) and one that executes statements (produces side effects).
public class Interpreter
{
private Environment _environment = new();
public void Interpret(List<Stmt> statements)
{
try
{
foreach (var statement in statements)
Execute(statement);
}
catch (RuntimeError error)
{
Console.Error.WriteLine($"[line {error.Token.Line}] Runtime error: {error.Message}");
}
}The public entry point takes the list of statements from the parser and executes them one by one. If anything goes wrong, we catch the error and report it with a line number. No stack trace, no crash — just a clear message about what went wrong and where.
Evaluating expressions
Expressions are the heart of any language. Every expression evaluates to a value: a number, a string, a boolean, or nil.
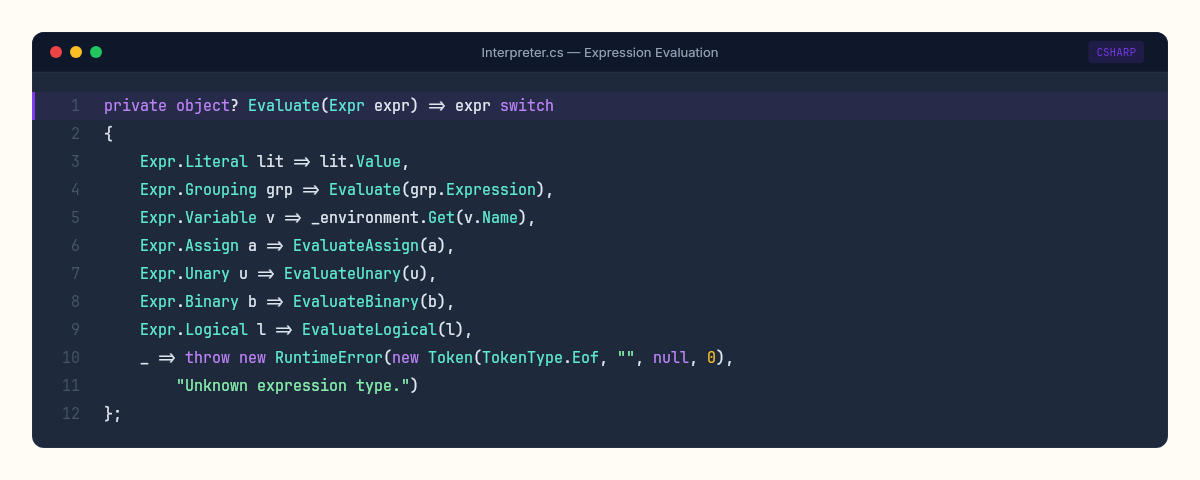
private object? Evaluate(Expr expr) => expr switch
{
Expr.Literal lit => lit.Value,
Expr.Grouping grp => Evaluate(grp.Expression),
Expr.Variable v => _environment.Get(v.Name),
Expr.Assign a => EvaluateAssign(a),
Expr.Unary u => EvaluateUnary(u),
Expr.Binary b => EvaluateBinary(b),
Expr.Logical l => EvaluateLogical(l),
_ => throw new RuntimeError(new Token(TokenType.Eof, "", null, 0),
"Unknown expression type.")
};Pattern matching on the expression type. Each node kind gets its own evaluation logic. The Literal case is almost embarrassingly simple — just return the value. The Grouping case just evaluates the inner expression. These are the leaf nodes and passthrough nodes of our tree.
The interesting ones are Unary, Binary, and Logical.
private object? EvaluateUnary(Expr.Unary expr)
{
var right = Evaluate(expr.Operand);
return expr.Op.Type switch
{
TokenType.Minus => -(double)right!,
TokenType.Bang => !IsTruthy(right),
_ => null
};
}
private object? EvaluateBinary(Expr.Binary expr)
{
var left = Evaluate(expr.Left);
var right = Evaluate(expr.Right);
return expr.Op.Type switch
{
TokenType.Plus when left is double l && right is double r => l + r,
TokenType.Plus when left is string l && right is string r => l + r,
TokenType.Minus => (double)left! - (double)right!,
TokenType.Star => (double)left! * (double)right!,
TokenType.Slash => CheckDivision(expr.Op, (double)left!, (double)right!),
TokenType.Greater => (double)left! > (double)right!,
TokenType.GreaterEqual => (double)left! >= (double)right!,
TokenType.Less => (double)left! < (double)right!,
TokenType.LessEqual => (double)left! <= (double)right!,
TokenType.EqualEqual => IsEqual(left, right),
TokenType.BangEqual => !IsEqual(left, right),
_ => null
};
}Notice the Plus operator handles two cases: number addition and string concatenation. This is dynamic typing in action — the same operator, different behavior depending on the runtime types of the operands. The parser couldn't know which one to use. The grammar doesn't distinguish between 3 + 4 and "hello" + " world". Only the interpreter, at the moment of execution, has enough information to decide.
The logical operators deserve their own method because they short-circuit:
private object? EvaluateLogical(Expr.Logical expr)
{
var left = Evaluate(expr.Left);
if (expr.Op.Type == TokenType.Or)
return IsTruthy(left) ? left : Evaluate(expr.Right);
// And
return !IsTruthy(left) ? left : Evaluate(expr.Right);
}or returns the left value if truthy — it never evaluates the right side. and returns the left value if falsy. This isn't just an optimization. In languages with side effects, short-circuit evaluation is semantic. The expression false and dangerousFunction() must never call dangerousFunction. Our interpreter gets this right because we control when Evaluate is called.
The helper methods
A few small methods that handle truthiness, equality, and division:
private static bool IsTruthy(object? value) => value switch
{
null => false,
bool b => b,
_ => true
};
private static bool IsEqual(object? a, object? b) =>
(a, b) switch
{
(null, null) => true,
(null, _) => false,
_ => a.Equals(b)
};
private static double CheckDivision(Token op, double left, double right)
{
if (right == 0)
throw new RuntimeError(op, "Division by zero.");
return left / right;
}
private object? EvaluateAssign(Expr.Assign expr)
{
var value = Evaluate(expr.Value);
_environment.Assign(expr.Name, value);
return value;
}IsTruthy follows a common convention: nil and false are falsy, everything else is truthy. IsEqual handles null comparisons safely. CheckDivision catches division by zero before .NET turns it into Infinity. And assignment evaluates the right side, stores the result, and returns the value — making a = b = 5 work through right-to-left evaluation.
Executing statements
Statements don't produce values. They produce effects: defining a variable, printing output, choosing a branch, repeating a block.
private void Execute(Stmt stmt)
{
switch (stmt)
{
case Stmt.ExpressionStmt s:
Evaluate(s.Expression);
break;
case Stmt.PrintStmt s:
var value = Evaluate(s.Expression);
Console.WriteLine(Stringify(value));
break;
case Stmt.VarDecl s:
object? initializer = s.Initializer is not null
? Evaluate(s.Initializer)
: null;
_environment.Define(s.Name.Lexeme, initializer);
break;
case Stmt.Block s:
ExecuteBlock(s.Statements, new Environment(_environment));
break;
case Stmt.IfStmt s:
if (IsTruthy(Evaluate(s.Condition)))
Execute(s.ThenBranch);
else if (s.ElseBranch is not null)
Execute(s.ElseBranch);
break;
case Stmt.WhileStmt s:
while (IsTruthy(Evaluate(s.Condition)))
Execute(s.Body);
break;
}
}Each statement type maps to a few lines of C#. The PrintStmt evaluates its expression and writes the result to the console. The VarDecl evaluates the initializer (or defaults to nil) and defines the variable in the current environment. The IfStmt evaluates the condition and picks a branch. The WhileStmt evaluates the condition repeatedly and executes the body until it's falsy.
The Block case is the most important. It creates a new environment that encloses the current one, executes the statements inside that new scope, and then restores the original environment:
private void ExecuteBlock(List<Stmt> statements, Environment environment)
{
var previous = _environment;
try
{
_environment = environment;
foreach (var statement in statements)
Execute(statement);
}
finally
{
_environment = previous;
}
}
private static string Stringify(object? value) => value switch
{
null => "nil",
double d => d.ToString("G"),
bool b => b ? "true" : "false",
_ => value.ToString() ?? "nil"
};
}The finally block is critical. If a runtime error occurs inside a nested scope, the environment must still be restored. Without it, an error in a block would leave the interpreter in the wrong scope — every subsequent variable lookup would search the wrong chain.
What happens on error
Let's trace what happens when a program references a variable that doesn't exist.
var x = 10;
print y + x;The interpreter starts normally. It executes the VarDecl for x, storing 10.0 in the global environment. Then it hits PrintStmt and calls Evaluate on the expression Binary(Variable(y), Plus, Variable(x)).
EvaluateBinary evaluates the left operand first: Variable(y). That calls _environment.Get(y), which searches the current environment's dictionary. No y. It checks the enclosing environment. There is none — we're at the global scope. End of the chain. The Get method throws a RuntimeError, carrying the y token with it — the same token the scanner created back in lexical analysis, still holding its line number.
The RuntimeError unwinds through EvaluateBinary, through Evaluate, through Execute, all the way back to the try/catch in Interpret(). None of those methods catch it. Only the top-level loop does. It prints:
[line 2] Runtime error: Undefined variable 'y'.That line number didn't come from the interpreter. It came from the scanner, preserved through the token, carried by the parser into the AST, and finally surfaced by the runtime error handler. Every phase of the pipeline contributed to this one diagnostic message. The scanner tracked position. The parser preserved the token. The interpreter used it to report the failure.
This is why we attached Token to RuntimeError instead of just a string. Without it, the error message would say "Undefined variable 'y'" with no indication of where. With it, the user gets a precise location. The right operand x is never evaluated — EvaluateBinary asked for the left side first, and the error aborted everything before we got to the right side.
A program, running
Let's trace through a complete program to see everything working together.
var x = 10;
var y = 20;
if (x < y) {
var temp = x + y;
print temp;
}
print x;Here's what happens, step by step:
VarDecl x = 10— evaluatesLiteral(10)→10.0, definesxin global environmentVarDecl y = 20— evaluatesLiteral(20)→20.0, definesyin global environmentIfStmt— evaluatesBinary(Variable(x), Less, Variable(y))Looks up
x→10.0, looks upy→20.010.0 < 20.0→trueIsTruthy(true)→true, so execute the then-branch
Block— creates new environment enclosing globalVarDecl temp = x + y— evaluatesBinary(Variable(x), Plus, Variable(y))Looks up
x→ walks to enclosing global →10.0Looks up
y→ walks to enclosing global →20.010.0 + 20.0→30.0Defines
tempin block's local environment
PrintStmt temp— looks uptempin local environment →30.0, prints30Block ends — local environment discarded,
tempno longer existsPrintStmt x— looks upxin global environment →10.0, prints10
Output:
30
10Two lines of output. The whole pipeline — source text to tokens to syntax tree to runtime behavior — working end to end.
What this doesn't handle
Our interpreter runs programs. It handles variables, arithmetic, comparisons, boolean logic, control flow, and scoping. That's a real programming language, not a toy.
But it has limits worth naming.
There are no functions. You can't define fun add(a, b) { return a + b; } and call it later. Functions require call stacks, parameter binding, return values, and — if you want closures — capturing the environment at the point of definition, not the point of call. That's a substantial extension. It's also where the connection to lambda calculus becomes unavoidable, because functions-as-values force you to think about what a "value" even is.
There's no error recovery. A single runtime error kills the entire program. Production interpreters catch errors at the statement level and continue, reporting as many problems as possible in one pass.
There's no optimization. We evaluate the tree directly, which means while (true) { ... } evaluates the Literal(true) node on every iteration, allocates a new pattern match, and calls IsTruthy — all to determine something that will never change. Real interpreters compile to bytecode first, eliminating this overhead.
That bytecode step is worth understanding, even if we're not building it. CPython compiles Python source to .pyc bytecode before executing it. The JVM compiles Java to .class files. The CLR compiles C# to IL. In all three cases, the syntax tree is an intermediate representation that gets lowered into a flat sequence of instructions — LOAD_CONST 10, STORE_NAME x, BINARY_ADD — and then a virtual machine executes those instructions in a tight loop. No tree traversal. No pattern matching per operation. Just a program counter advancing through a byte array. For a hot loop running millions of iterations, a bytecode VM can be 10 to 100 times faster than tree-walking. But it's also 10 to 100 times more complex to build. We'd need an instruction set, a compiler from AST to bytecode, a virtual stack or register file, and a dispatch loop. Our tree-walker trades performance for clarity — and at this stage of the series, clarity wins.
The distance between "it runs" and "it runs well" is where most of language implementation lives.
These limitations aren't failures. They're design decisions. We built the simplest thing that could correctly execute a program, and we did it in about 150 lines of C#. Every line has a clear purpose. Every method maps to a grammar rule or a semantic operation. That clarity is worth more than optimization at this stage.
The ribosome's lesson
In molecular biology, the ribosome doesn't modify the mRNA it reads. It walks the structure faithfully, producing proteins according to the code. But the proteins — those change the cell. They catalyze reactions, build structures, send signals. The behavior emerges from the reading, not from the code itself.
Our interpreter works the same way. The syntax tree is inert. The Evaluate and Execute methods walk it faithfully, producing behavior according to the rules we defined. The variables, the output, the branching — all of that emerges from the walking, not from the tree.
As we explored in the previous chapter about building the parser, the tree captures structure — precedence, nesting, grouping. The interpreter is what makes that structure do something. And the space where the two meet is the space where syntax becomes semantics, where form becomes meaning, where knowing what someone said becomes understanding what they meant.
Next, we'll add functions. And that's where this language stops being a calculator with variables and becomes something genuinely expressive — because functions are the mechanism that lets a language talk about itself.