
Building the Lexer — Turning Text into Tokens
Character by character, our language takes its first breath. A lexer in C# that reads raw source code and produces a stream of meaningful tokens.

var x = 10 + 20;Nineteen characters. Spaces, letters, digits, symbols. To you, it's a variable declaration. To the computer, it's just bytes. Something has to bridge that gap — something that reads raw text character by character and decides where one meaningful unit ends and the next begins.
That something is a lexer.
As we defined in the grammar chapter, our language's formal rules describe what's valid. But the grammar operates on tokens, not characters. Before we can parse var x = 10 + 20;, we need to break it into seven pieces: var, x, =, 10, +, 20, ;. Each piece carries a type — keyword, identifier, operator, number, punctuation — and together they form the raw material the parser will consume.
Today we build the lexer. By the end of this chapter, we'll have working C# code that reads a source string and produces a List<Token>.
The Token
Before scanning anything, we need to define what we're producing. A token is a type, a lexeme (the actual text), and optionally a literal value:
public enum TokenType
{
// Single-character tokens
LeftParen, RightParen, LeftBrace, RightBrace,
Comma, Dot, Minus, Plus, Semicolon, Slash, Star,
// One or two character tokens
Bang, BangEqual, Equal, EqualEqual,
Greater, GreaterEqual, Less, LessEqual,
// Literals
Identifier, String, Number,
// Keywords
And, Else, False, If, Nil, Or, Print, True, Var, While,
// End
Eof
}
public record Token(TokenType Type, string Lexeme, object? Literal, int Line);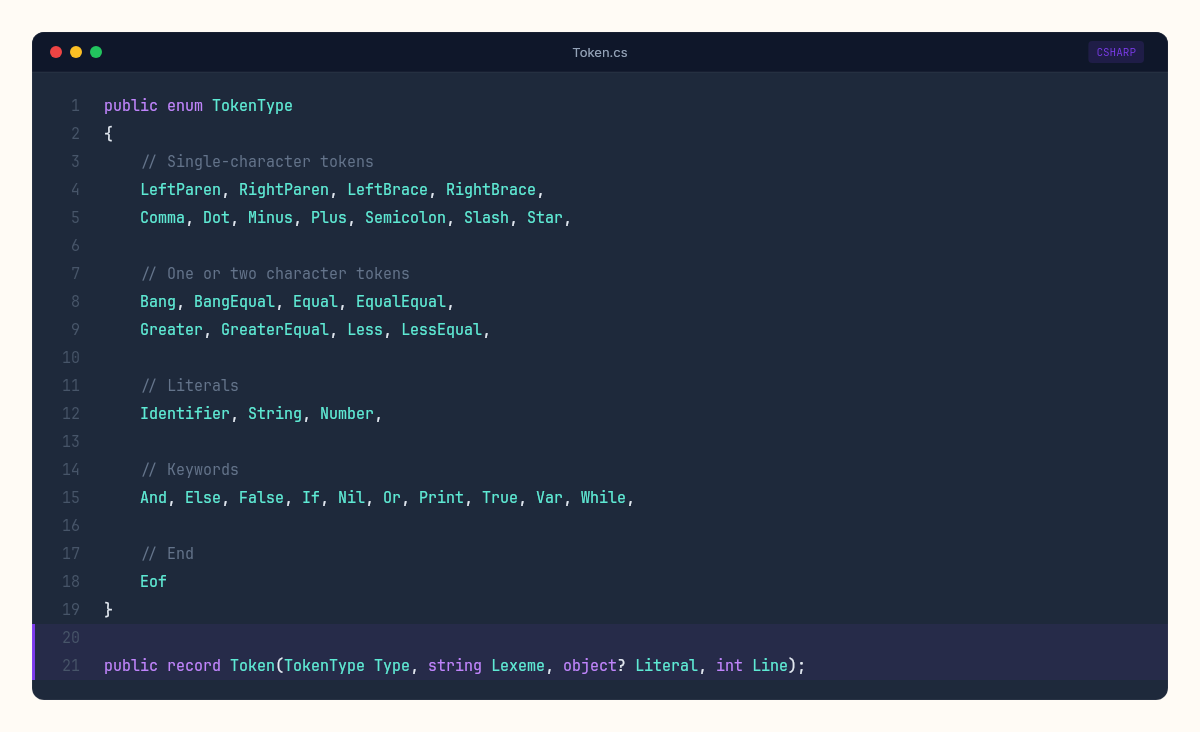
The record type is perfect here — tokens are immutable value objects. The Line field will make error messages useful when things go wrong (and they will).
The keyword list is deliberately small: var, if, else, while, print, true, false, nil, and, or. No for, no func, no return — yet. We'll add functions later in the series. For now, this is enough to write real programs with variables, conditions, and loops.
The Scanner: a finite automaton in disguise
A lexer is a loop with a cursor. It starts at position zero, examines the current character, decides what token it's looking at, advances past it, and repeats until it hits the end of the source.
This is, mathematically, a deterministic finite automaton (DFA). The scanner has a current state (determined by the characters it has consumed so far), it reads one character of input, and it transitions to a new state. When it reaches an accepting state, it emits a token and resets.
The difference between writing a lexer by hand and generating one from a regular expression (like flex or ANTLR do) is that the hand-written version is the DFA, just expressed as if statements and switch cases instead of a transition table. The computational model is identical.
Here's the skeleton:
public class Scanner
{
private readonly string _source;
private readonly List<Token> _tokens = new();
private int _start = 0;
private int _current = 0;
private int _line = 1;
private static readonly Dictionary<string, TokenType> Keywords = new()
{
["and"] = TokenType.And, ["else"] = TokenType.Else,
["false"] = TokenType.False, ["if"] = TokenType.If,
["nil"] = TokenType.Nil, ["or"] = TokenType.Or,
["print"] = TokenType.Print, ["true"] = TokenType.True,
["var"] = TokenType.Var, ["while"] = TokenType.While,
};
public Scanner(string source) => _source = source;
public List<Token> ScanTokens()
{
while (!IsAtEnd())
{
_start = _current;
ScanToken();
}
_tokens.Add(new Token(TokenType.Eof, "", null, _line));
return _tokens;
}
private bool IsAtEnd() => _current >= _source.Length;
private char Advance() => _source[_current++];
private char Peek() => IsAtEnd() ? '\0' : _source[_current];
private char PeekNext() => _current + 1 >= _source.Length
? '\0' : _source[_current + 1];
}Two pointers: _start marks the beginning of the current lexeme, _current is the read head. Think of it like a measuring tape — _start is where you put the end of the tape down, _current is where you're reading the measurement. The gap between them is the token being assembled. Every time we emit a token, _start catches up to _current.
Two pointers and a character-at-a-time loop. That's all a lexer is — the rest is deciding what each character means.
The scanning loop
The core of the lexer is a single switch statement that dispatches on the current character:
private void ScanToken()
{
char c = Advance();
switch (c)
{
// Single-character tokens
case '(': AddToken(TokenType.LeftParen); break;
case ')': AddToken(TokenType.RightParen); break;
case '{': AddToken(TokenType.LeftBrace); break;
case '}': AddToken(TokenType.RightBrace); break;
case ',': AddToken(TokenType.Comma); break;
case '.': AddToken(TokenType.Dot); break;
case '-': AddToken(TokenType.Minus); break;
case '+': AddToken(TokenType.Plus); break;
case ';': AddToken(TokenType.Semicolon); break;
case '*': AddToken(TokenType.Star); break;
// One or two character tokens
case '!': AddToken(Match('=') ? TokenType.BangEqual : TokenType.Bang); break;
case '=': AddToken(Match('=') ? TokenType.EqualEqual : TokenType.Equal); break;
case '<': AddToken(Match('=') ? TokenType.LessEqual : TokenType.Less); break;
case '>': AddToken(Match('=') ? TokenType.GreaterEqual : TokenType.Greater); break;
// Slash or comment
case '/':
if (Match('/'))
while (Peek() != '\n' && !IsAtEnd()) Advance();
else
AddToken(TokenType.Slash);
break;
// Whitespace
case ' ': case '\r': case '\t': break;
case '\n': _line++; break;
// Literals
case '"': ScanString(); break;
default:
if (char.IsDigit(c)) ScanNumber();
else if (char.IsLetter(c) || c == '_') ScanIdentifier();
else ReportError(_line, $"Unexpected character: {c}");
break;
}
}The Match method is the one-character lookahead that distinguishes = from ==:
private bool Match(char expected)
{
if (IsAtEnd() || _source[_current] != expected) return false;
_current++;
return true;
}The first time I wrote a lexer, I expected something more... exotic. Some mathematical machinery I'd need to study before touching. It's a switch statement. The most powerful text-processing tool in compiler design is a switch statement with a cursor.
The DFA metaphor becomes concrete right here. The ! character puts us in a state where we need one more character to decide: if the next character is =, emit BangEqual and advance; otherwise, emit Bang and stay put. Two states, one transition, one decision. That's a finite automaton.
Scanning multi-character tokens
Single characters and two-character operators are straightforward. The interesting cases are strings, numbers, and identifiers — tokens whose length varies.
Strings consume everything between two " delimiters:
private void ScanString()
{
while (Peek() != '"' && !IsAtEnd())
{
if (Peek() == '\n') _line++;
Advance();
}
if (IsAtEnd())
{
ReportError(_line, "Unterminated string.");
return;
}
Advance(); // closing "
var value = _source[(_start + 1)..(_current - 1)];
AddToken(TokenType.String, value);
}
Numbers consume digits, with an optional decimal point:
private void ScanNumber()
{
while (char.IsDigit(Peek())) Advance();
if (Peek() == '.' && char.IsDigit(PeekNext()))
{
Advance(); // consume the '.'
while (char.IsDigit(Peek())) Advance();
}
var value = double.Parse(_source[_start.._current],
System.Globalization.CultureInfo.InvariantCulture);
AddToken(TokenType.Number, value);
}The PeekNext() call in the number scanner is crucial — and I got this wrong the first time. My original lexer consumed the dot in 123.toString() and I spent twenty minutes wondering why method calls on numbers produced parse errors. The fix was one extra lookahead character. Without it, 123.toString() would consume the . as part of the number. We need to see two characters ahead — the dot and whatever follows — before committing. This is the one place where our lexer needs more than single-character lookahead.
Identifiers and keywords share the same scanning logic. The lexer reads a word, then checks if it's in the keyword dictionary:
private void ScanIdentifier()
{
while (char.IsLetterOrDigit(Peek()) || Peek() == '_') Advance();
var text = _source[_start.._current];
var type = Keywords.GetValueOrDefault(text, TokenType.Identifier);
AddToken(type);
}This is called maximal munch — the lexer always consumes the longest possible token. variable is one identifier, not the keyword var followed by iable. The greedy loop handles this automatically.
The helper that ties it together
Every scanning path ends at AddToken:
private void AddToken(TokenType type, object? literal = null)
{
var text = _source[_start.._current];
_tokens.Add(new Token(type, text, literal, _line));
}The lexeme is always the substring between _start and _current. The literal is only populated for strings and numbers — tokens that carry a runtime value beyond their textual representation.
Running it
Let's feed our lexer a real program:
var scanner = new Scanner("""
var x = 10;
var y = 20;
print x + y;
""");
var tokens = scanner.ScanTokens();
foreach (var token in tokens)
Console.WriteLine($"{token.Type,-15} '{token.Lexeme}'");Output:
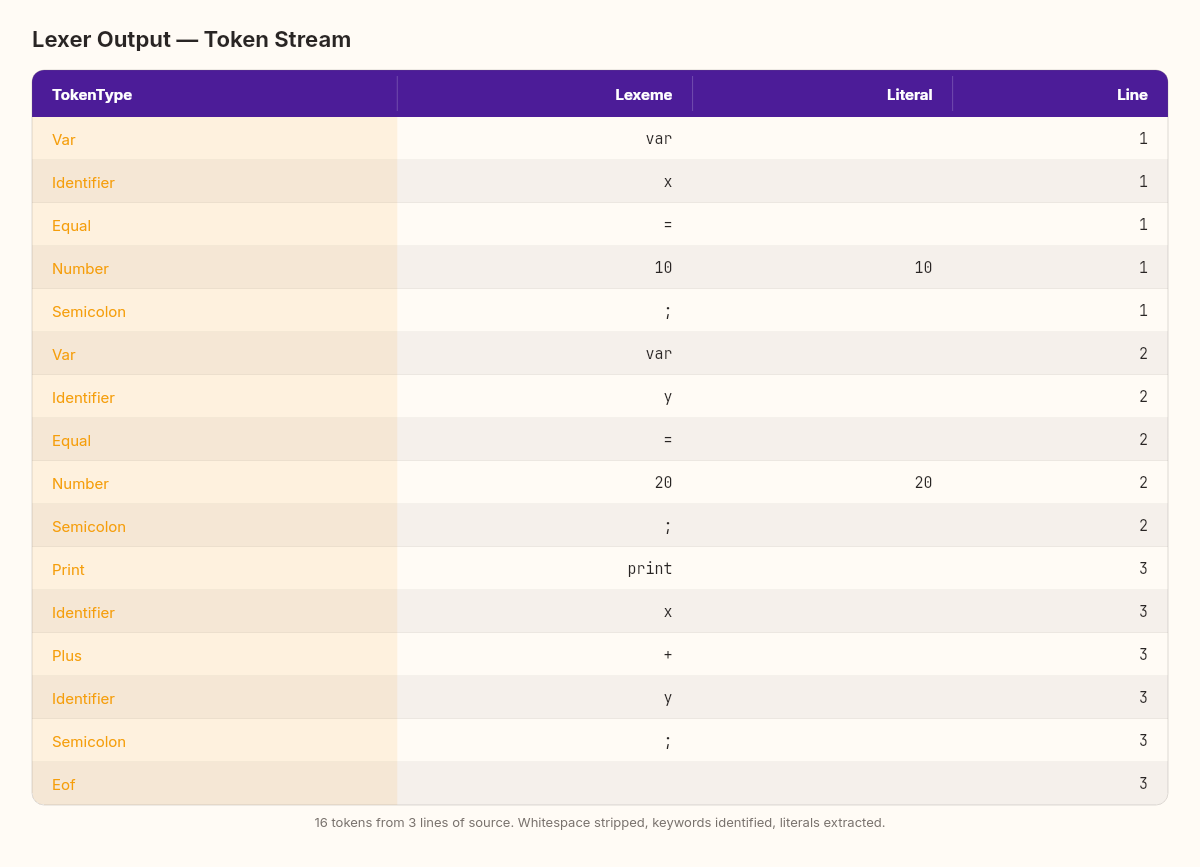
Thirteen tokens from three lines of code. The whitespace is gone. The comments (if there were any) are gone. What remains is a clean stream of typed tokens that the parser can consume without thinking about characters, spacing, or line breaks.
What the lexer doesn't do
The lexer doesn't understand structure. It doesn't know that var x = 10 is a variable declaration. It doesn't know that + is an operator that takes two operands. It doesn't check whether x has been declared before it's used. It just produces tokens.
This separation matters. The lexer handles the lexical grammar — regular language rules that describe what a valid token looks like. The parser handles the syntactic grammar — context-free rules that describe how tokens combine into statements and expressions. Mixing them produces a system that's harder to debug, harder to extend, and harder to reason about.
In compiler theory, this is the principle of separation of concerns applied to language processing. The Chomsky hierarchy we explored in the formal language structure chapter isn't just a classification — it's an architectural guide. Regular rules (Type 3) go in the lexer. Context-free rules (Type 2) go in the parser. Each component operates at exactly the level of power it needs.
What's next
We have tokens. Nineteen characters became seven meaningful pieces. The raw text that meant nothing to the machine now has structure — types, boundaries, intent.
In the next chapter, we give that stream a shape. The parser will take this flat list and build a tree — an abstract syntax tree — that captures the nested structure of the program. 10 + 20 * 3 isn't three tokens in sequence; it's a tree where * binds before +, and the tree's shape encodes that precedence.
The grammar we wrote in the formal language structure chapter will become the parser's blueprint. Each grammar rule becomes a method. Each method consumes tokens and returns a node. The recursive descent is where our language starts to feel like a language.
Today, our language reads.