
Every Language Starts with a Grammar
Week 2 begins. Before we write a lexer, parser, or interpreter, we need to understand what a language actually is — and a linguist from 1956 already figured it out.

In 1956, a twenty-eight-year-old linguist named Noam Chomsky published a paper called "Three Models for the Description of Language." He wasn't thinking about computers. He was trying to answer a deceptively simple question about human language: how can a child who has heard a finite number of sentences produce an infinite number of new ones?
His answer was a set of formal rules — a grammar — that could generate all valid sentences in a language without listing them explicitly. The grammar wasn't the language. It was the machinery that produced the language. A finite description of an infinite set.
Fourteen years later, when computer scientists needed a way to describe the syntax of programming languages, they didn't invent something new. They reached for Chomsky's framework. Every programming language you've ever used — C#, Python, JavaScript, SQL — is defined by a formal grammar that traces its lineage directly to that 1956 paper.
This week in The C# Lab, we're building a programming language from scratch. And like every language that has ever existed, ours starts with a grammar.
In the earlier chapters we built a custom ORM — SQL generation, reflection-based mapping, change tracking, benchmarks against EF Core. We learned what sits underneath the tools we use every day. This week, we go deeper. We're building something that sits underneath everything: a language.
Not a production compiler. Not a Roslyn competitor. A tiny, complete language — lexer, parser, interpreter — that runs real programs. Small enough to understand fully. Rich enough to illuminate how C# itself works.
But before we write a single line of code, we need to understand what we're building. And that means understanding grammars.
What is a grammar, formally?
A formal grammar is a four-tuple: G = (N, T, P, S).
N is a set of non-terminal symbols — placeholders that will be expanded. Think of them as categories:
Expression,Statement,Term.T is a set of terminal symbols — the actual characters or tokens that appear in the final string. In a programming language, these are keywords like
if, operators like+, literals like42.P is a set of production rules — instructions for replacing non-terminals with combinations of terminals and other non-terminals.
S is the start symbol — the non-terminal where parsing begins.

That's it. Four elements. Every programming language grammar in existence is an instance of this structure.
Here's a grammar for simple arithmetic:
Expression → Term (('+' | '-') Term)*
Term → Factor (('*' | '/') Factor)*
Factor → NUMBER | '(' Expression ')'Three rules. They define an infinite set of valid arithmetic expressions: 1, 2 + 3, (4 * 5) + 6 / (7 - 8), and every other combination you could construct. The recursion in the third rule — Factor can contain an Expression, which contains Terms, which contain Factors — is what makes the language infinite from finite rules.
This is Chomsky's insight applied to code. A finite description generating infinite possibilities.
The Chomsky hierarchy: four levels of power
Chomsky didn't just describe one kind of grammar. He identified four, arranged in a hierarchy of increasing power — and increasing computational cost.
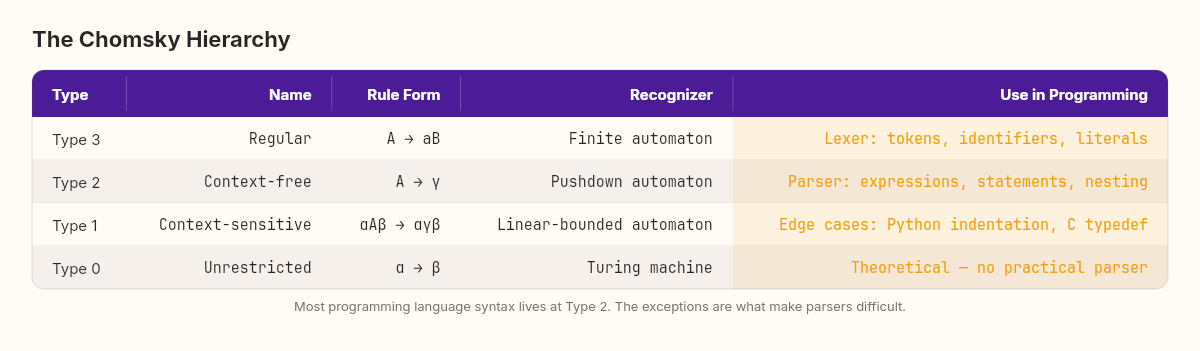
Type 3 — Regular grammars. The simplest. Every rule has the form A → aB or A → a (a single terminal, optionally followed by a single non-terminal). These generate regular languages — the same languages matched by regular expressions. Integer literals, identifiers, whitespace patterns. Your lexer lives here.
Type 2 — Context-free grammars (CFGs). Rules have the form A → γ where γ can be any combination of terminals and non-terminals. The crucial word is context-free: the left side is always a single non-terminal, and it can be expanded regardless of what surrounds it. Most programming language syntax is defined at this level. The arithmetic grammar above is a CFG.
Type 1 — Context-sensitive grammars. Rules can have context on the left side: αAβ → αγβ. The expansion of A depends on what's around it. Some programming language features land here — Python's significant indentation, C's typedef ambiguity where x * y could be a multiplication or a pointer declaration depending on whether x is a type name.
Type 0 — Unrestricted grammars. Any rule of the form α → β. Turing-complete. No practical parser exists for these.
Every programming language is designed to be mostly context-free. The exceptions are the features that make parsers cry.
The practical implication: when we build our language this week, we're aiming for a context-free grammar. This is the sweet spot — powerful enough to express nested structures (function calls inside function calls, blocks inside blocks), simple enough that a recursive descent parser can handle it in a few hundred lines of C#.
BNF: how we actually write grammars down
Chomsky's formalism is mathematically precise but awkward to read. In 1959, John Backus proposed a notation for describing the syntax of ALGOL 60, and Peter Naur refined it. The result — Backus-Naur Form (BNF) — became the standard way to write programming language grammars.
BNF uses ::= instead of →, angle brackets for non-terminals, and vertical bars for alternatives:
<expression> ::= <term> | <expression> "+" <term> | <expression> "-" <term>
<term> ::= <factor> | <term> "*" <factor> | <term> "/" <factor>
<factor> ::= <number> | "(" <expression> ")"Extended BNF (EBNF) adds repetition (*, +), optionality (?), and grouping — bringing it closer to the way we think about patterns:
expression = term { ("+" | "-") term } ;
term = factor { ("*" | "/") factor } ;
factor = number | "(" expression ")" ;This is the notation we'll use to define our language's grammar. Every rule reads like a sentence: "An expression is a term, followed by zero or more additions or subtractions of another term."
Our language's grammar: Lox-lite
For our C# Lab language, I'm defining a minimal grammar — enough to be interesting, small enough to implement in a week. I'm calling it Lox-lite (a nod to Robert Nystrom's Lox language from Crafting Interpreters, which inspired this week's project):
program = { statement } ;
statement = varDecl | exprStmt | printStmt | ifStmt | whileStmt | block ;
varDecl = "var" IDENTIFIER "=" expression ";" ;
exprStmt = expression ";" ;
printStmt = "print" expression ";" ;
ifStmt = "if" "(" expression ")" statement ( "else" statement )? ;
whileStmt = "while" "(" expression ")" statement ;
block = "{" { statement } "}" ;
expression = assignment ;
assignment = IDENTIFIER "=" assignment | equality ;
equality = comparison ( ("==" | "!=") comparison )* ;
comparison = addition ( (">" | ">=" | "<" | "<=") addition )* ;
addition = multiply ( ("+" | "-") multiply )* ;
multiply = unary ( ("*" | "/") unary )* ;
unary = ("!" | "-") unary | primary ;
primary = NUMBER | STRING | "true" | "false" | "nil"
| IDENTIFIER | "(" expression ")" ;Twenty rules. That's the entire language.
It supports variables, arithmetic, comparisons, boolean logic, if/else, while loops, blocks with lexical scoping, and print statements. No functions yet — we'll add those later in the series, and the lambda calculus connection will make the detour worthwhile.
Twenty grammar rules. That's the distance between "a text file" and "a program that runs."
Notice the expression rules are layered by precedence. multiply binds tighter than addition, which binds tighter than comparison, which binds tighter than equality. This isn't an accident — it's how the grammar encodes operator precedence without needing any special mechanism. The parser will follow the grammar's nesting, and the nesting is the precedence.
From grammar to code: the connection
A grammar isn't just documentation. It's a blueprint for the parser we'll build in the next chapter.
Every non-terminal becomes a method. Every rule becomes the body of that method. Every terminal becomes a token check. The grammar literally is the code, written in a different notation.
// The grammar rule: addition = multiply ( ("+" | "-") multiply )* ;
// becomes this method:
private Expression ParseAddition()
{
var left = ParseMultiply();
while (Match(TokenType.Plus, TokenType.Minus))
{
var op = Previous();
var right = ParseMultiply();
left = new BinaryExpression(left, op, right);
}
return left;
}The * in the grammar becomes a while loop. The | becomes checking multiple token types. The recursive reference to multiply becomes a method call. The mapping is mechanical — once you can read the grammar, you can write the parser.
This is why we're spending an entire chapter on grammars before writing a single line of lexer code. The grammar is the architecture. Everything else is implementation.
What the SQL generator taught us
If you followed the ORM chapters earlier in the series, you've already built something that looks suspiciously like a tiny language processor. The SQL generator we built earlier in the series took C# method calls — Where, OrderBy, Select — and translated them into SQL text. It had a vocabulary (SQL keywords), a structure (SELECT ... FROM ... WHERE ...), and rules about what could appear where.
The difference between that and what we're building this week is formality. The SQL generator worked because SQL's structure is rigid and predictable. Our language has nested expressions, variable scoping, control flow — structures that require the full power of a context-free grammar to describe and a proper parser to handle.
But the instinct is the same. Take structured input. Understand its shape. Transform it into something executable. The ORM did it by convention. This week, we do it by formal grammar.
Why this matters beyond this project
You might never build a programming language. But you will, almost certainly, build something that parses structured input. Configuration files. Query languages. DSLs for business rules. Template engines. Command-line argument parsers. Every one of these is a language, whether you call it that or not.
The difference between a robust parser and a fragile mess of string splits and regex patterns is whether the developer understood formal grammars. Not deeply — you don't need to prove theorems about pushdown automata. But enough to know that a grammar is a finite description of an infinite set, that context-free grammars handle nesting, and that precedence is encoded in the grammar's structure, not bolted on after the fact.
Chomsky figured this out about human language in 1956. The insight transfers perfectly to the languages we build for machines. A finite set of rules. An infinite set of valid programs. And the space between them is where the interesting work happens.
The next chapter covers the lexer — the component that reads raw text and produces a stream of tokens. The grammar tells us what the tokens mean. The lexer tells us where they are.