
One Pattern, Six Angles, and the Thing That Actually Changed
Week 1 synthesis. We dissected the outbox pattern from theory to tools. Here's what sticks — and what I wish I'd known before the lost notifications incident.

The outbox pattern is seven lines of SQL and a background loop. Everything important about it lives outside the code.
We spent six chapters on those seven lines — theory, implementation, edge cases, stress testing, decision frameworks, library comparisons. Monday through Saturday, one pattern examined from six angles. And now, sitting with all of it, the question worth answering isn't "how does the outbox work?" It's: what changed in how I think about distributed systems after taking this single pattern apart and reassembling it six different ways?
The thread I didn't see coming
Each chapter this week asked a slightly different question.
Monday asked: why does the problem exist? Two systems, one transaction boundary. The gap between saving and publishing is where messages go to die.
Tuesday asked: what does a solution look like? The outbox table, the polling publisher, idempotency keys. A blueprint with real EF Core code and real RabbitMQ wiring.
Wednesday asked: what goes wrong? Duplicate delivery, ordering guarantees, table growth, cleanup. The five edge cases that tutorials skip because they're uncomfortable.
Thursday asked: how much can it take? Ten thousand messages per second, a dead broker, and a partitioned network. The stress test revealed that our implementation survived chaos — but the recovery time was slower than I wanted.
Friday asked: should you even bother? Twelve messages a day don't justify a transactional outbox. The decision matrix forced me to admit that I've recommended this pattern in situations where a simple try-catch would have been enough.
Saturday asked: who already solved this? MassTransit, NServiceBus, Wolverine, CAP. Four libraries, four philosophies. The sommelier's craft of matching tool to context.
But looking back, there's a thread connecting all six chapters that I only see now. It's not about the outbox pattern. It's about the cost of distributed systems guarantees.
What "at least once" actually costs
Every guarantee in a distributed system has a price. We say "at-least-once delivery" as if it's a feature you toggle on. It isn't. It's a commitment that cascades into every layer of your architecture.
At-least-once delivery means your consumers must be idempotent. Idempotent consumers mean you need either natural idempotency in your domain (rare) or a deduplication mechanism (a processed-events table, a hash check, a version number). Deduplication means another query per message. Another table. Another index. Another thing to monitor, clean up, and explain to the next engineer who inherits your system.
The outbox pattern guarantees that messages leave your service. It does not guarantee that they arrive exactly once, that they arrive in order, or that the consumer handles them correctly. Those are separate problems, each with their own patterns, their own trade-offs, and their own operational costs.
This is what I wish I'd understood before that incident. >> The outbox is one piece in a chain of guarantees, each with a cost. The chain is only as strong as the weakest link you chose not to address.
The three things I'll carry forward
One: the mental model matters more than the code. The implementation of the outbox pattern is straightforward. A table, a publisher, a retry loop. The hard part is understanding where the pattern sits in the reliability chain and what it doesn't cover. Most production incidents I've seen with messaging don't happen because the outbox failed. They happen because someone assumed the outbox handled something it doesn't — ordering, exactly-once delivery, poison message routing.
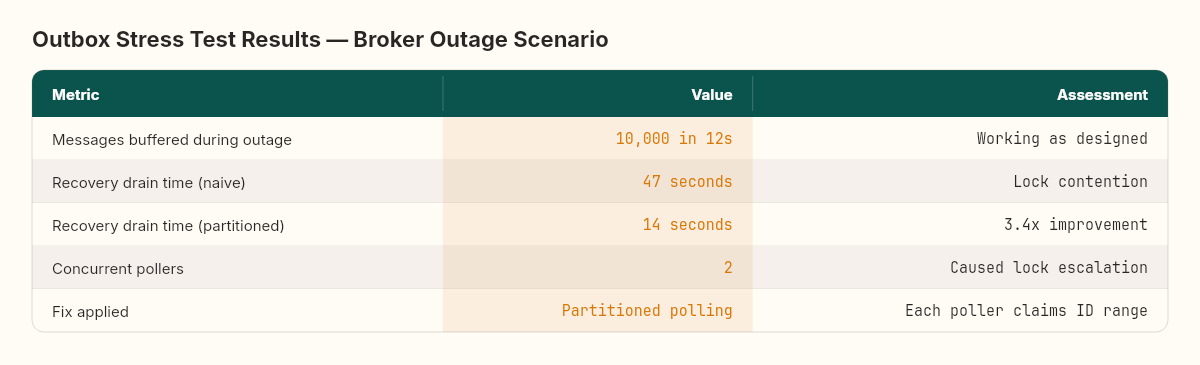
Two: stress testing is not optional. Thursday's stress test was the chapter that revealed the most. Here's a number that stuck: during a simulated broker outage, our outbox buffered 10,000 messages in 12 seconds. That part worked. But when the broker came back, the recovery drain took 47 seconds — nearly four times longer than the accumulation. Why? Lock contention. Two concurrent pollers competing on the same outbox table turned a simple SELECT-and-DELETE into a lock escalation problem. The fix was a partitioned polling strategy — each poller claims a range of message IDs — and recovery time dropped to 14 seconds. I couldn't have predicted either the problem or the fix from reading the code. You have to run the experiment.
Three: the decision framework is the real deliverable. We spent six chapters building expertise about one pattern. But the most valuable output was Friday's decision matrix: the five questions that tell you whether the outbox earns its complexity in your specific system. I've started using a version of this for every architecture pattern. Not "should we use CQRS?" but "do we have the specific conditions under which CQRS earns its overhead?" The framing changes the conversation from advocacy to analysis.
A before and after in my own code
Let me make this concrete with the code transformation that captures the entire week.
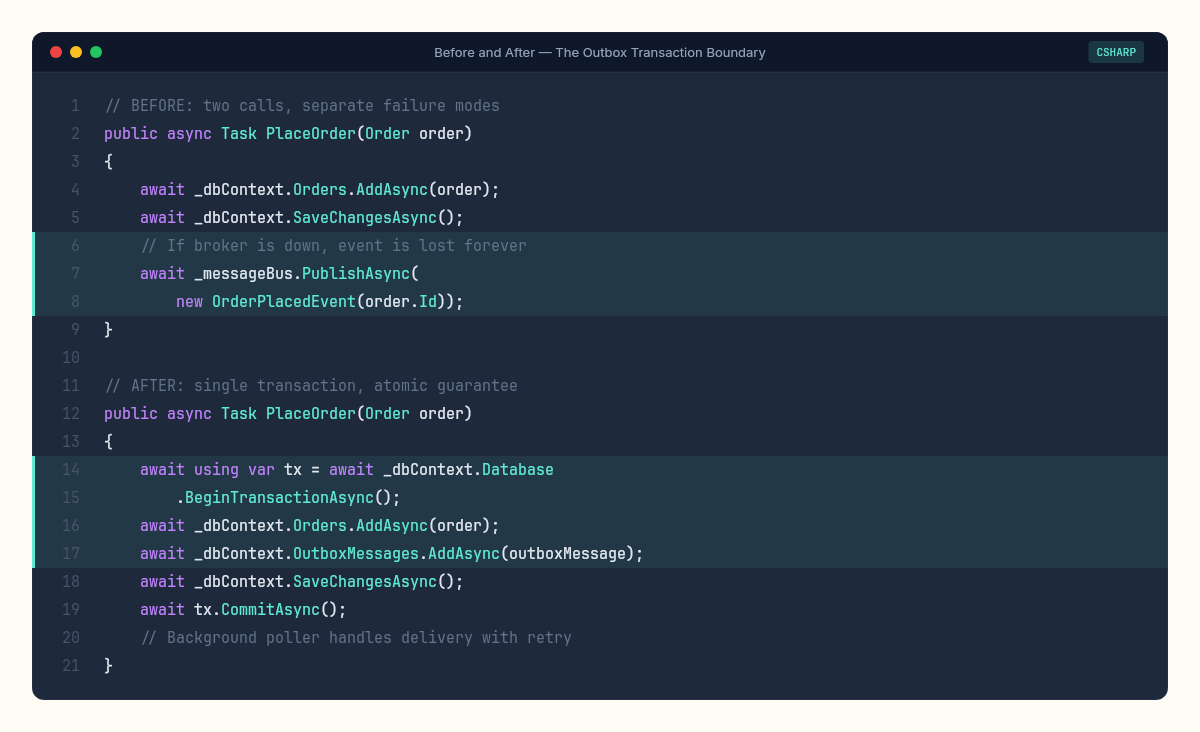
Before this week — the code I've written in at least three production services:
public async Task PlaceOrder(Order order)
{
await _dbContext.Orders.AddAsync(order);
await _dbContext.SaveChangesAsync();
// "This should be fine. SaveChanges succeeded."
await _messageBus.PublishAsync(
new OrderPlacedEvent(order.Id));
}Two calls, one after the other. The transaction boundary ends at SaveChangesAsync(). The publish is a separate operation — a separate network call, to a separate system, with a separate failure mode. If the broker is down, the order is saved but the event is lost.
After this week — the same operation with the outbox:
public async Task PlaceOrder(Order order)
{
var outboxMessage = new OutboxMessage
{
Id = Guid.NewGuid(),
Type = nameof(OrderPlacedEvent),
Payload = JsonSerializer.Serialize(
new OrderPlacedEvent(order.Id)),
CreatedAt = DateTime.UtcNow,
ProcessedAt = null
};
// Single transaction: both succeed or both fail.
await using var tx = await _dbContext.Database
.BeginTransactionAsync();
await _dbContext.Orders.AddAsync(order);
await _dbContext.OutboxMessages.AddAsync(outboxMessage);
await _dbContext.SaveChangesAsync();
await tx.CommitAsync();
// The background poller picks up outboxMessage
// and publishes it. If the broker is down, it retries.
// The message is never lost.
}More code, yes. But notice what moved: the publish is no longer a hope attached to the end of a transaction. It's a row in the same database, committed atomically with the business data. The background poller (Chapter 2's OutboxPublisher) handles the delivery, with retry, idempotency keys, and dead-letter routing.
But here's the shift that matters more than the code. I wouldn't automatically reach for the outbox every time. The real change is that I now ask a question before writing any of this: what's the failure budget?
If this service processes twelve orders a day and a missed event triggers a manual follow-up that takes two minutes — the failure cost is low. A try-catch with a logged warning and a retry queue might be the right answer. No outbox needed.
If this service processes ten thousand orders per hour and a missed event means an invoice never gets generated — the failure cost is high. The outbox earns its complexity. And I'd reach for a library (MassTransit or Wolverine, depending on the transport) rather than hand-rolling it, because Saturday's chapter showed me exactly how much edge-case handling those libraries absorb.
The code I write hasn't changed dramatically. The decision that precedes the code has changed entirely.
What's next
Week 2, we switch patterns entirely.
I've been circling a question that came up at least three times this week: how do you coordinate multiple services when a single business operation spans several of them? The outbox guarantees that a message leaves your service. But what happens when the downstream service receives the message, starts processing, and that processing requires coordinating with a third service?
This is the saga pattern. Orchestration versus choreography. Compensating transactions. State machines that track long-running business processes across service boundaries.
If the outbox pattern is about reliable delivery at the seam between one service and its broker, the saga pattern is about reliable coordination across the entire distributed system. Same philosophy — make guarantees explicit, make failures visible — but at a different scale.
I already have a war story for this one. An order that got stuck between three services, each waiting for the other two to confirm. A distributed deadlock that didn't show up in any single service's logs. It took us a day and a half to find it, and the fix changed how I think about distributed transactions permanently.
But that's Monday.
Before then, a question worth asking yourself — and your team. Pick one service in your current system that saves data and publishes an event. Trace the path between the database write and the message publish. Are they in the same transaction? If not, what happens when the publish fails after the write succeeds?
If you're not sure, you have the same blind spot we had on that operations platform. The outbox won't fix the blind spot. Understanding the transaction boundary will.
The transaction boundary is where every distributed systems guarantee starts — and where most of them quietly break.