
One Thread, Many Clients — Channels and the Art of Not Blocking
Our Redis clone handles GET and SET. But one slow client freezes everyone. A Channel<T>, a dispatcher loop, and the queuing theory that explains why this was always the answer.

The server was handling 200 connections beautifully. Then connection 201 sent a SET with a 4MB value over a 2G mobile link — and every other client stalled for eleven seconds.
The store wasn't slow. The CPU wasn't overloaded. The problem was simpler and worse: the reading task for that one sluggish connection was holding a lock inside ConcurrentDictionary while it waited for bytes to trickle in from the network. One client's bandwidth problem became everyone's latency problem.
This is the failure mode that real Redis solved thirty years ago with a single-threaded event loop. And it's the problem we're going to solve today with Channel<T> — .NET's built-in primitive for producer-consumer pipelines.
The three concurrency models
When we built the TCP server, we spawned one Task per client connection. Each task read commands from its socket and executed them directly against the store. It was simple, it worked, and it has a fundamental flaw.
Let's compare three approaches to handling concurrent clients, because the differences aren't just architectural — they're mathematical.
Model 1: Thread-per-connection
// What we built in the TCP chapter
while (true)
{
var client = await listener.AcceptTcpClientAsync();
_ = Task.Run(() => HandleClientAsync(client, store));
}
async Task HandleClientAsync(TcpClient client, RedisStore store)
{
var stream = client.GetStream();
while (true)
{
var command = await ReadCommandAsync(stream); // blocks this task
var result = store.Execute(command); // touches shared state
await stream.WriteAsync(Encoding.UTF8.GetBytes(result));
}
}Each connection gets its own task. Each task reads from the network, executes against the store, writes back. The problem: store.Execute() runs on whichever thread the task scheduler assigns. Multiple tasks hit the store concurrently. ConcurrentDictionary handles that safely, but now imagine Execute needs to do something more complex — check a key's type, read its value, modify it, update expiration. That sequence isn't atomic across ConcurrentDictionary calls. You need either locks or a different architecture.
Model 2: Lock everything
private readonly object _lock = new();
string Execute(string[] command, RedisStore store)
{
lock (_lock)
{
return ProcessCommand(command, store);
}
}Safe. Correct. And it serializes every single operation through one lock. Under contention, tasks queue on the lock, the thread pool grows, context switches multiply. You've traded a data race for a performance cliff.
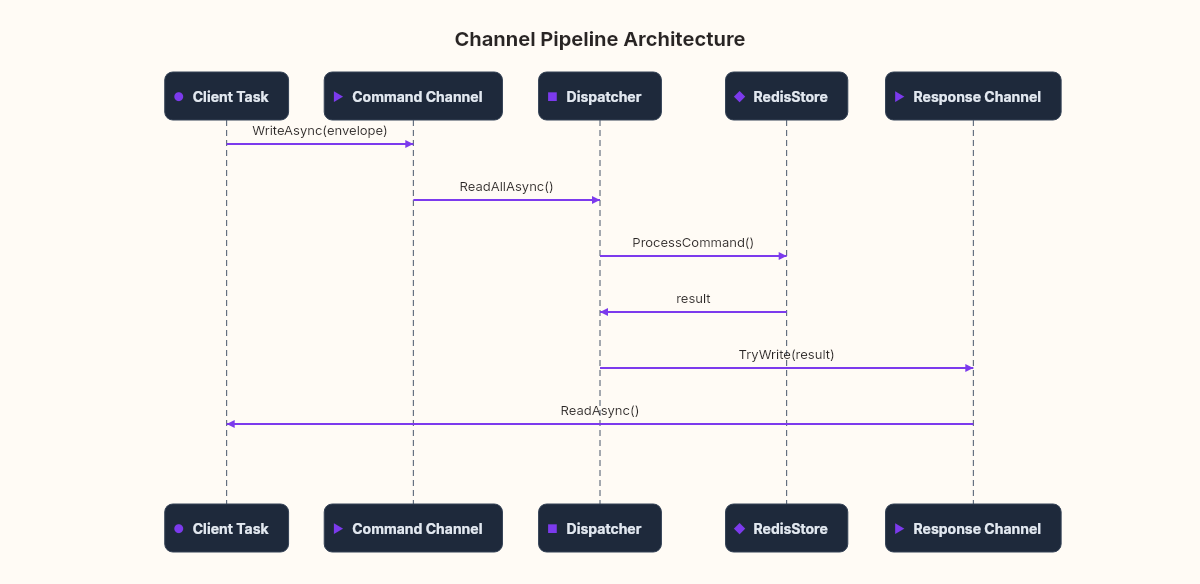
Model 3: Channel pipeline
var commandChannel = Channel.CreateUnbounded<CommandEnvelope>();
// Single consumer — processes commands one at a time
_ = Task.Run(async () =>
{
await foreach (var envelope in commandChannel.Reader.ReadAllAsync())
{
var result = ProcessCommand(envelope.Command, store);
envelope.ResponseChannel.Writer.TryWrite(result);
}
});
// Each client task just writes to the channel
async Task HandleClientAsync(TcpClient client,
ChannelWriter<CommandEnvelope> writer)
{
var stream = client.GetStream();
while (true)
{
var command = await ReadCommandAsync(stream);
var responseChannel = Channel.CreateUnbounded<string>();
await writer.WriteAsync(new CommandEnvelope
{
Command = command,
ResponseChannel = responseChannel
});
var result = await responseChannel.Reader.ReadAsync();
await stream.WriteAsync(Encoding.UTF8.GetBytes(result));
}
}Now the client tasks do one thing: read from the network, package the command, drop it into the channel, wait for a response. The store is touched by exactly one task — the dispatcher loop. No locks needed. No concurrent dictionary required. The store could be a plain Dictionary<string, RedisValue>.
The Channel doesn't just solve the concurrency problem. It eliminates it. When only one consumer touches the data, there is no concurrency.
The queuing theory underneath
This architecture has a name in mathematics. It's an M/M/1 queue — a single-server queuing system where arrivals are random and service times are random. The foundational result is Little's Law: L = λW
Where L is the average number of items in the system, λ is the arrival rate (commands per second), and W is the average time each command spends in the system (wait + service).

If our dispatcher processes commands in 1 microsecond (realistic for in-memory operations), the service rate μ = 1,000,000 commands/second. As long as λ < μ — as long as commands arrive slower than we can process them — the queue stays short and latency stays low.
The occupancy ratio ρ = λ/μ tells the whole story. At ρ = 0.5 (half capacity), average queue depth is 1 command. At ρ = 0.9, it's 9. At ρ = 0.99, it's 99. The curve is a hyperbola — latency rises gently at moderate load, then explodes as you approach capacity.
This is why real Redis is single-threaded and still fast. The service time for in-memory operations is so small that one thread can handle hundreds of thousands of commands per second. The bottleneck isn't CPU — it's network I/O. And by separating network reading (many tasks) from command execution (one task), the Channel architecture puts the parallelism exactly where it belongs.
The envelope pattern
The key to making this work is the CommandEnvelope — a struct that carries both the command and a way to send the response back:
public record CommandEnvelope
{
public required string[] Command { get; init; }
public required Channel<string> ResponseChannel { get; init; }
public required string ClientId { get; init; }
}
Each client creates a per-request response channel. The dispatcher processes the command, writes the result to that channel, and the client reads it. This is a rendezvous — a one-to-one communication between the dispatcher and a specific client.
The pattern looks like overhead — creating a channel per request? — but Channel.CreateUnbounded<T>() is allocation-light. The channel is backed by a ConcurrentQueue internally, and for a single-write/single-read scenario, the cost is negligible compared to the network I/O that surrounds it.
Wiring it into the server
Here's how the full architecture connects:
public class RedisServer
{
private readonly RedisStore _store = new();
private readonly Channel<CommandEnvelope> _commands =
Channel.CreateUnbounded<CommandEnvelope>(
new UnboundedChannelOptions
{
SingleReader = true, // only the dispatcher reads
SingleWriter = false // many client tasks write
});
public async Task StartAsync(int port, CancellationToken ct)
{
var listener = new TcpListener(IPAddress.Any, port);
listener.Start();
// Start the single dispatcher
_ = RunDispatcherAsync(ct);
while (!ct.IsCancellationRequested)
{
var client = await listener.AcceptTcpClientAsync(ct);
_ = HandleClientAsync(client, ct);
}
}
private async Task RunDispatcherAsync(CancellationToken ct)
{
await foreach (var env in _commands.Reader.ReadAllAsync(ct))
{
var result = ProcessCommand(env.Command, _store);
env.ResponseChannel.Writer.TryWrite(result);
env.ResponseChannel.Writer.Complete();
}
}
private async Task HandleClientAsync(TcpClient client,
CancellationToken ct)
{
using var stream = client.GetStream();
var clientId = client.Client.RemoteEndPoint?.ToString() ?? "unknown";
try
{
while (!ct.IsCancellationRequested)
{
var command = await ReadCommandAsync(stream, ct);
var response = Channel.CreateUnbounded<string>();
await _commands.Writer.WriteAsync(new CommandEnvelope
{
Command = command,
ResponseChannel = response,
ClientId = clientId
}, ct);
var result = await response.Reader.ReadAsync(ct);
await stream.WriteAsync(
Encoding.UTF8.GetBytes(result), ct);
}
}
catch (OperationCanceledException) { }
catch (IOException) { } // client disconnected
}
}The SingleReader = true hint on the channel options lets the runtime optimize the internal queue — it can skip certain synchronization since it knows only one consumer exists. It's a small detail, but it compounds. Real Redis gets its single-thread guarantee from the OS event loop. We get ours from a Channel option.
What we traded
The Channel pipeline is elegant, but it has costs.
Latency under low load: With thread-per-connection, a command from a single client goes directly to the store — no queue, no context switch. With the Channel, it goes through a write, a read, a process, a write, and a read. Under light load, the direct model is actually faster.
Bounded vs unbounded: We're using CreateUnbounded, which means a burst of commands can fill memory. In production, you'd use CreateBounded with a capacity limit, accepting that WriteAsync will back-pressure slow clients when the queue is full. That's a conscious trade-off: reject work vs accumulate debt.
Debugging complexity: When something goes wrong in the dispatcher loop, the stack trace doesn't show which client caused the problem. The ClientId in the envelope helps, but it's metadata you have to carry manually. The direct model gives you the stack trace for free.
Every concurrency model is a bet about where you'll hit the wall first. Thread-per-connection bets on low connection counts. Lock-per-operation bets on fast operations. Channels bet on the queue staying short.
The connection to what comes next
Our Redis clone now has the same architecture as real Redis: one thread processes commands sequentially while network I/O happens in parallel across many connections. The store doesn't need ConcurrentDictionary anymore — a plain Dictionary behind the Channel dispatcher would work.
But everything in this store still lives in memory. Kill the process, and every key disappears — exactly the limitation we flagged when building GET and SET. The Channel gives us something new, though: since every command flows through a single dispatcher, we can intercept that flow. Every write command can be logged to a file before it's executed. An append-only file. A transaction log.
That's persistence — and it's where the trade-offs get genuinely hard. How often do you flush to disk? Every command (safe, slow) or every second (fast, data-loss window)? The answer involves thermodynamics. Literally.
Your challenge: With a service time of 2 microseconds per command and an arrival rate of 400,000 commands per second, calculate the average queue depth using Little's Law. Then calculate what happens when arrival rate hits 495,000. The curve will surprise you.