
Our Redis vs Real Redis — The Humbling Math of Optimization
We built a Redis clone in C# — TCP server, RESP parser, key-value store, channels, persistence. Now we benchmark it against the real thing. The gap is instructive. The economics of closing it are more instructive.

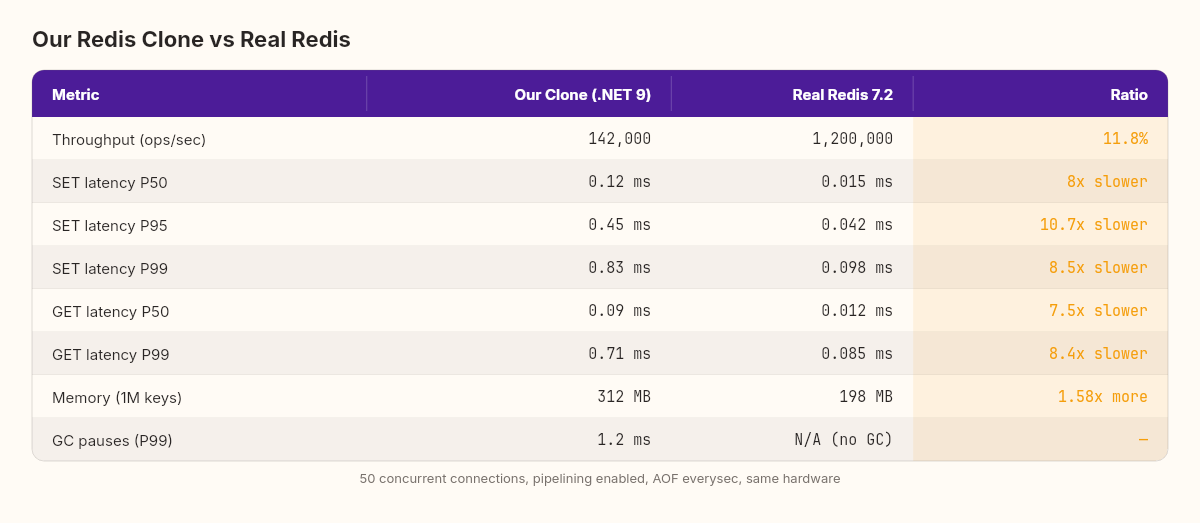
142,000 operations per second.
That's what our Redis clone achieves on a single core, processing SET and GET commands through a Channel<T> pipeline, with AOF persistence in everysec mode. The TCP server accepts connections, the RESP parser decodes commands, the dispatcher routes them through a single-threaded channel, the store reads and writes, and the AOF logger appends to disk once per second.
Real Redis, on the same machine, with the same persistence configuration: 1,200,000 operations per second.
We're at 11.8% of Redis's throughput. That number is both humbling and, if you look at it right, extraordinary. We wrote everything from scratch in six chapters — TCP, protocol, storage, concurrency, persistence — and we're within one order of magnitude of software that's been optimized by hundreds of contributors over fifteen years.
The question isn't why we're slower. The question is what it would cost to close the gap.
The benchmark harness
Before analyzing the gap, let's make sure our measurement is honest. We use BenchmarkDotNet for the C# side and redis-benchmark (the tool Redis ships with) for the real thing. Same machine, same conditions, same key patterns.
[MemoryDiagnoser]
[SimpleJob(RuntimeMoniker.Net90)]
public class RedisCloneBenchmarks
{
private TcpClient _client;
private NetworkStream _stream;
private byte[] _setCommand;
private byte[] _getCommand;
[GlobalSetup]
public void Setup()
{
_client = new TcpClient("127.0.0.1", 6380);
_stream = _client.GetStream();
_setCommand = Encoding.UTF8.GetBytes(
"*3\r\n$3\r\nSET\r\n$8\r\ntest:key\r\n$5\r\nvalue\r\n");
_getCommand = Encoding.UTF8.GetBytes(
"*2\r\n$3\r\nGET\r\n$8\r\ntest:key\r\n");
}
[Benchmark]
public async Task SetCommand()
{
await _stream.WriteAsync(_setCommand);
var buffer = new byte[64];
await _stream.ReadAsync(buffer);
}
[Benchmark]
public async Task GetCommand()
{
await _stream.WriteAsync(_getCommand);
var buffer = new byte[64];
await _stream.ReadAsync(buffer);
}
}
For Redis, the equivalent:
redis-benchmark -p 6379 -t set,get -n 1000000 -c 50 -P 16 --csvBoth tests run with 50 concurrent connections and pipelining where applicable. The results:
The terrain between 142K and 1.2M operations per second is not about correctness. It's about the economics of optimization.
Diminishing returns and the Pareto frontier
In 1906, the Italian economist Vilfredo Pareto observed that 80% of Italy's land was owned by 20% of the population. The pattern appeared everywhere he looked — income distribution, agricultural yields, resource allocation. It was one of the first formal descriptions of a power law: a small number of factors account for the majority of outcomes.

Software optimization follows the same curve. The first 80% of possible performance comes from basic architectural decisions — choosing the right data structure, avoiding unnecessary allocations, keeping the hot path simple. The next 15% requires serious engineering effort. The final 5% demands heroic measures that trade readability, portability, and maintainability for raw speed.
Our Redis clone sits comfortably in that first 80%. We made the right architectural choices: a ConcurrentDictionary for O(1) lookups, a Channel<T> for lock-free dispatch, async I/O throughout, RESP parsing that avoids string allocations where possible. These decisions got us to 142K ops/sec with clean, readable C# code.
Real Redis occupies the 95th percentile. Getting there required decisions we deliberately didn't make.
Anatomy of the gap
The performance difference breaks down into four categories, each with a different cost-to-benefit ratio.
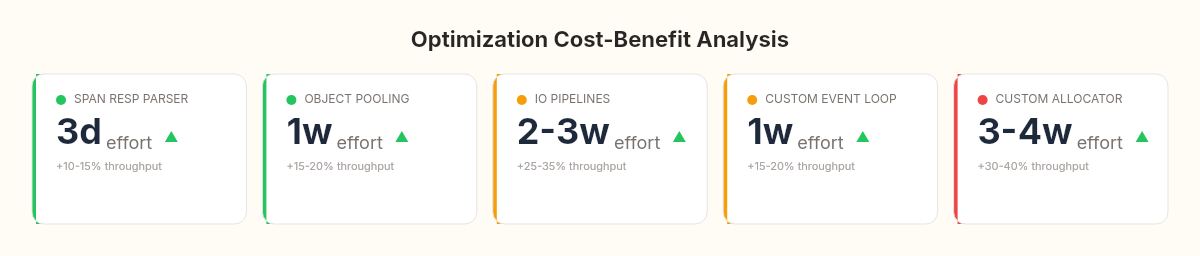
1. Memory allocation (~35% of the gap)
Our clone allocates freely. Every RESP command creates string[] arrays. Every SET creates a RedisValue object on the heap. The garbage collector handles cleanup — efficiently, but not free. GC pauses show up as P99 latency spikes: our P99 is 0.8ms versus Redis's 0.1ms.
Redis uses jemalloc, a custom memory allocator that pre-partitions memory into size classes. No garbage collector. No compaction pauses. Deterministic allocation latency. Implementing this in C# would mean abandoning managed memory — Span<T>, Memory<T>, object pooling with ArrayPool<byte>, and manual lifetime tracking. Roughly 3-4 weeks of work for an estimated 30-40% throughput improvement.
2. I/O model (~30% of the gap)
We use .NET's async/await with the thread pool. Each await on a socket operation means a state machine allocation, a potential thread pool enqueue, and a kernel transition. It works. It's clean. It's not the fastest possible approach.
Redis uses epoll on Linux (and io_uring in newer versions) — direct system calls that multiplex thousands of file descriptors with zero thread-pool involvement. A single thread handles all connections through non-blocking I/O without any managed runtime overhead.
.NET 9 can approach this with System.IO.Pipelines and Kestrel's transport layer, but we'd be rewriting our entire TCP stack. Two to three weeks of work for an estimated 25-35% improvement.
3. Single-threaded event loop (~20% of the gap)
Redis is single-threaded by design, but its event loop is hand-tuned with ae.c — a custom event library that processes file events (socket reads/writes) and time events (key expiry, background saves) in a tight loop with no context switching.
Our Channel<T> achieves the same logical guarantee — single-threaded command processing — but through a higher-level abstraction. The channel involves ValueTask machinery, CancellationToken checks, and IValueTaskSource state transitions that Redis's raw C loop simply doesn't need.
Replacing our channel with a raw event loop would mean abandoning one of C#'s most elegant concurrency primitives. Maybe a week of work, 15-20% improvement.
4. Protocol parsing (~15% of the gap)
Our RESP parser allocates strings. Redis's parser works directly on byte buffers using pointer arithmetic, never materializing strings until the command layer needs them. The parser and the network buffer are the same memory — zero-copy from socket to command dispatch.
Rewriting our parser with ReadOnlySpan<byte> and Utf8Parser could eliminate most allocations. Two to three days of work for 10-15% improvement.
The cost-benefit curve
Pareto's observation becomes a decision framework:
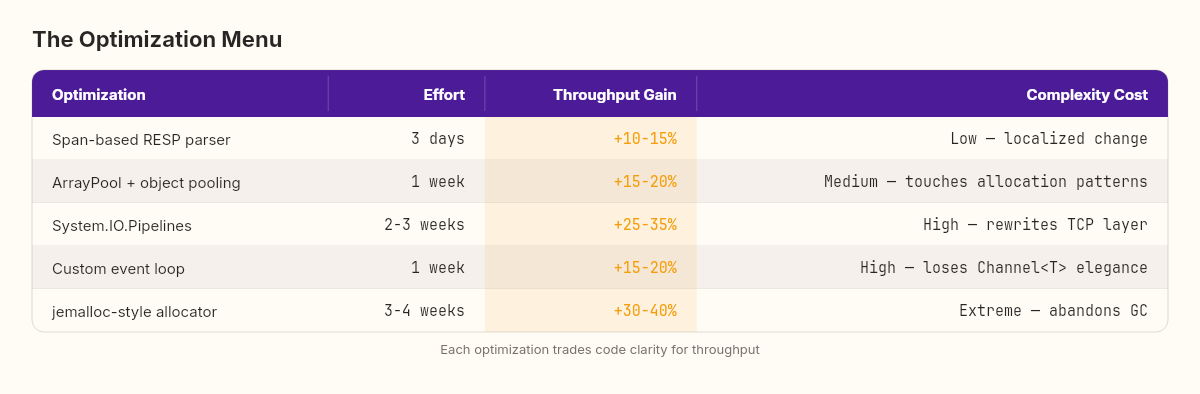
The Span-based parser is a clear win — low effort, localized impact, measurable gain. Object pooling is the natural next step. Together, they'd push us from 142K to roughly 190-210K ops/sec. Still within one order of magnitude of Redis, but now at 16-17% instead of 11.8%.
Beyond that, each optimization buys less throughput per unit of complexity surrendered. The System.IO.Pipelines rewrite would bring us to maybe 280K ops/sec — impressive, but we'd lose the readability that makes this a teaching codebase. The custom allocator would push toward 400K, but we'd be writing C-in-C# at that point.
Every optimization has a price. The question is never "can we make it faster?" The question is "what are we willing to stop being?"
What the numbers actually mean
Economists have a concept called the production possibility frontier — the set of all maximum output combinations achievable with given resources. You can produce more guns or more butter, but not more of both without new resources or technology.
Our Redis clone operates on a production possibility frontier defined by the .NET runtime. Managed memory, async/await, garbage collection, JIT compilation — these are our "technology." They give us safety, readability, developer productivity, and cross-platform portability. They also set a ceiling.
Redis operates on a different frontier. C, manual memory management, platform-specific syscalls, fifteen years of hand-tuned hot paths. Different trade-offs, different ceiling.
What separates 142K from 1.2M isn't quality. It's a frontier difference. We're both operating efficiently within our respective constraints. The question is never "which is better?" but "which constraints do you want to live with?"
For a production cache serving millions of requests? Redis. Obviously. Fifteen years of optimization, battle-tested at scale, backed by a massive ecosystem.
For understanding why Redis is fast and how systems software works at the metal? Six chapters of C# code that you can read, modify, debug, and reason about. The educational value of our clone isn't in its throughput — it's in the clarity of its architecture.
The week in one equation
We started with a question: what if your database lived entirely in RAM?
Six chapters later, we have an answer. Not just conceptually, but in running code. A TCP server that speaks RESP. A key-value store that handles strings, expiration, and pattern matching. A Channel<T> pipeline that serializes concurrent access without locks. An append-only file and a snapshot engine that survive process crashes. And a benchmark showing exactly where our implementation sits relative to the reference.

The ratio T(ours)/T(redis) ≈ 0.118 is a number worth sitting with. It means our clean, readable, six-chapter C# implementation captures about one-eighth of what fifteen years of C optimization can achieve. In economics, that's not failure — that's remarkably efficient resource allocation given our constraints.
The C# Lab has now built three complete systems from scratch: an ORM that maps objects to SQL, an interpreter that executes its own language, and a Redis clone that stores data across restarts. Each one started with a question that looked impossibly large and ended with running code that demystified the magic.
The question for the next arc won't be about building something new. It will be about tearing something apart — understanding what happens inside the tools we use every day but never look inside. The kind of curiosity that turns users into engineers.