
Persistence — When Memory Meets the Disk
Our Redis clone processes commands through a Channel and stores them in RAM. Kill the process and everything vanishes. An append-only file, a snapshot engine, and the thermodynamic cost of making data survive.

store.Set("user:1001", new RedisValue
{
Type = RedisType.String,
StringValue = "Antonello"
});
// Power cut.
// user:1001 is gone.That's the state of our Redis clone after we introduced Channels. It accepts connections, parses RESP, dispatches commands through a single-threaded pipeline, stores data in a dictionary, and expires keys on schedule. A complete in-memory data store — with the emphasis on in-memory. Everything lives on the heap. The heap lives in RAM. RAM lives until the power does.
Today we teach it to remember across restarts.
Two strategies for survival
Real Redis offers two persistence mechanisms, and the trade-off between them is one of the cleanest examples in systems programming of a fundamental physical constraint.
Append-Only File (AOF): Log every write command to a file as it happens. On restart, replay the log to reconstruct the state.
Snapshot (RDB): Periodically serialize the entire dataset to a binary file. On restart, load the snapshot.

Both work. Both have costs. The costs are different in kind, not just degree — and understanding why requires a detour into physics.
The thermodynamics of persistence
Every time you write data to disk, you're doing work against entropy.
This isn't metaphor. The second law of thermodynamics states that the entropy of an isolated system never decreases — disorder always grows unless energy is spent to maintain order. RAM is volatile precisely because maintaining the electric charge in each capacitor cell requires continuous power. Cut the power, the charges dissipate, the bits randomize. Entropy wins.
A disk write is the act of spending energy to create a more ordered physical state — magnetizing a region of a platter, trapping electrons in a flash cell. The data persists because the physical state is stable without continuous power. But creating that state has a cost: the write itself takes time, the disk controller must confirm the write reached stable storage, and the operating system must flush its buffers.
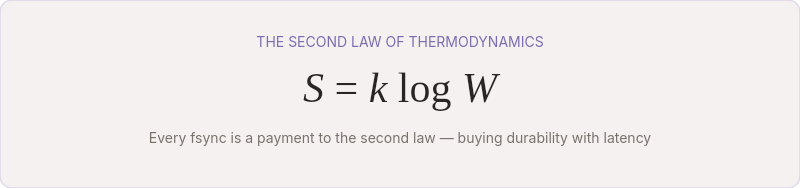
The fsync system call is where this cost becomes visible to programmers. When you call fsync, you're telling the OS: don't just buffer this write — make sure it's physically on the disk. The OS flushes its page cache, the disk controller flushes its write buffer, and control returns only when the bits are stable. This can take anywhere from 0.1ms (NVMe SSD) to 10ms (spinning disk). Fast by human standards. An eternity at 500,000 operations per second.
Every fsync is a payment to the second law. You're buying durability with latency.
Building the append-only file
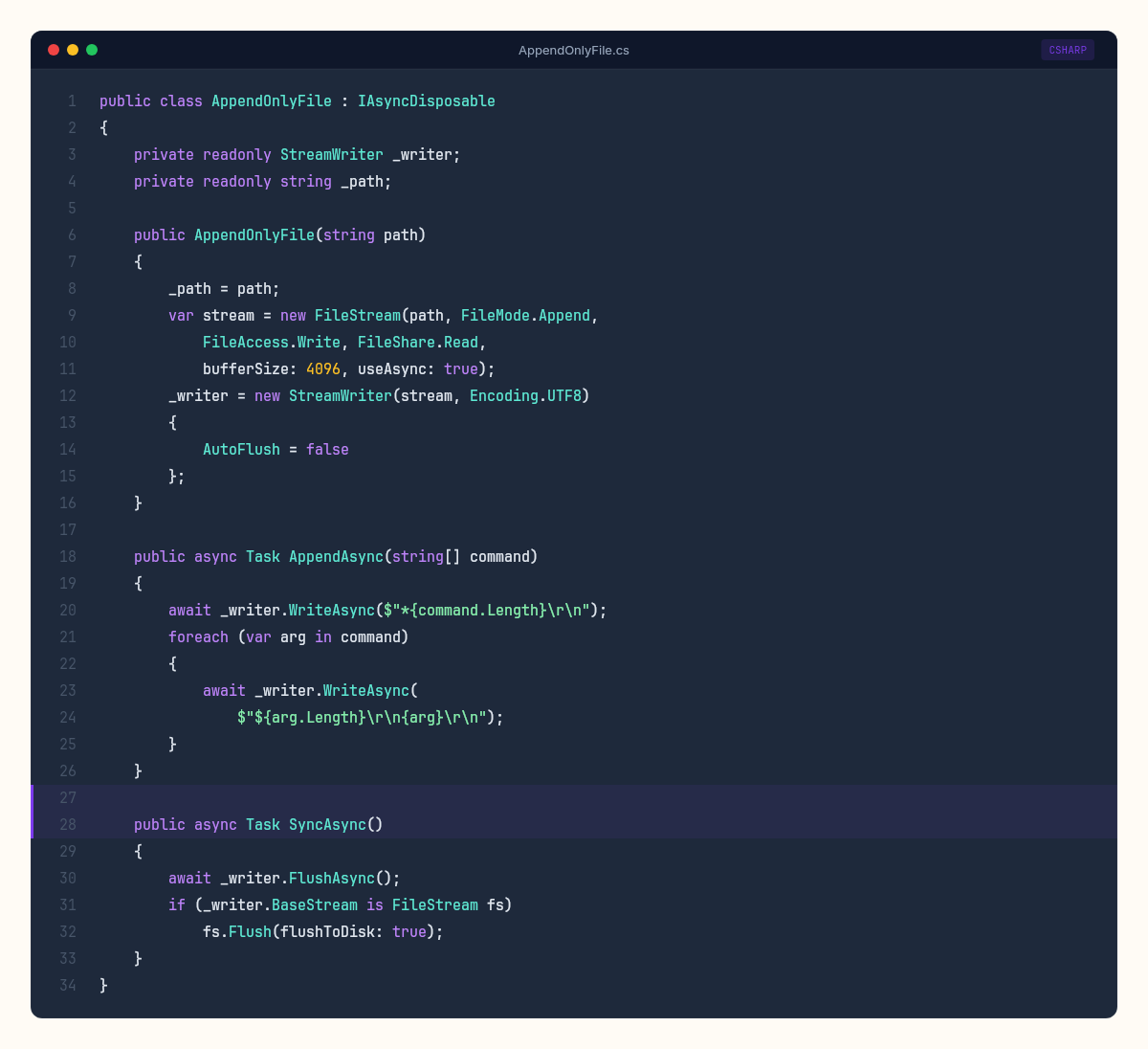
The AOF strategy is conceptually simple: intercept every write command in the dispatcher loop and append it to a file before executing it.
public class AppendOnlyFile : IAsyncDisposable
{
private readonly StreamWriter _writer;
private readonly string _path;
public AppendOnlyFile(string path)
{
_path = path;
var stream = new FileStream(path, FileMode.Append,
FileAccess.Write, FileShare.Read,
bufferSize: 4096, useAsync: true);
_writer = new StreamWriter(stream, Encoding.UTF8)
{
AutoFlush = false // we control when to flush
};
}
public async Task AppendAsync(string[] command)
{
// Write as RESP array — same format clients send
await _writer.WriteAsync($"*{command.Length}\r\n");
foreach (var arg in command)
{
await _writer.WriteAsync(
$"${arg.Length}\r\n{arg}\r\n");
}
}
public async Task SyncAsync()
{
await _writer.FlushAsync();
// fsync — ensure data reaches stable storage
if (_writer.BaseStream is FileStream fs)
fs.Flush(flushToDisk: true);
}
public async ValueTask DisposeAsync()
{
await SyncAsync();
await _writer.DisposeAsync();
}
}
We write commands in RESP format — the same wire protocol our clients use. This means the replay engine is just the RESP parser we already built for the TCP server, pointed at a file instead of a socket. No new serialization format. No schema versioning. The log file is human-readable, greppable, and uses infrastructure we've already tested.
Now we integrate it into the dispatcher:
private async Task RunDispatcherAsync(CancellationToken ct)
{
await foreach (var env in _commands.Reader.ReadAllAsync(ct))
{
var result = ProcessCommand(env.Command, _store);
// Log write commands to AOF before responding
if (IsWriteCommand(env.Command[0]))
{
await _aof.AppendAsync(env.Command);
}
env.ResponseChannel.Writer.TryWrite(result);
env.ResponseChannel.Writer.Complete();
}
}
private static bool IsWriteCommand(string name) =>
name.ToUpperInvariant() switch
{
"SET" or "DEL" or "EXPIRE" or "LPUSH" or
"RPUSH" or "SADD" or "HSET" => true,
_ => false
};Only write commands are logged. GET, EXISTS, KEYS — read-only operations that don't change state — are skipped. This keeps the log file smaller and the replay faster.
The fsync spectrum
The trade-off becomes concrete with three options for when to call SyncAsync():
Every command (fsync after each write):
Durability: lose at most 1 command on crash
Cost: 0.1–10ms per write. At 1ms fsync on SSD, throughput ceiling is ~1,000 writes/second
Every second (batch fsync on a timer):
Durability: lose at most 1 second of writes on crash
Cost: one fsync per second regardless of write volume. Throughput limited only by memory and CPU
Never (let the OS decide):
Durability: lose whatever the OS hasn't flushed — typically 30 seconds of writes
Cost: minimal. The OS batches disk I/O optimally
public enum FsyncPolicy
{
Always, // fsync after every write command
EverySecond, // fsync once per second (default)
No // let the OS decide
}Real Redis defaults to everysec — and so do we. It's the sweet spot: you lose at most one second of writes in a catastrophic failure, but your throughput isn't bottlenecked by disk latency.
// Background fsync loop for EverySecond policy
private async Task RunFsyncLoopAsync(CancellationToken ct)
{
while (!ct.IsCancellationRequested)
{
await Task.Delay(1000, ct);
await _aof.SyncAsync();
}
}Replaying the log
On startup, if an AOF file exists, we replay it to reconstruct the store:
public async Task ReplayAofAsync(string path, RedisStore store)
{
if (!File.Exists(path)) return;
using var stream = File.OpenRead(path);
var reader = new StreamReader(stream, Encoding.UTF8);
int commandCount = 0;
while (!reader.EndOfStream)
{
var command = await ReadCommandFromStream(reader);
if (command == null) break;
ProcessCommand(command, store);
commandCount++;
}
Console.WriteLine($"[AOF] Replayed {commandCount} commands");
}ReadCommandFromStream is essentially the same RESP parser from the TCP server, adapted to read from a StreamReader instead of a NetworkStream. Same format, same logic, different source. This is the payoff of choosing RESP as the log format.
Building the snapshot engine
The AOF approach has a growing problem — literally. The file only grows. If you set the same key a million times, the AOF contains a million SET commands, but only the last one matters. Real Redis solves this with AOF rewriting — periodically compacting the log by writing only the current state. We'll take a simpler approach: binary snapshots.
public class SnapshotEngine
{
public async Task SaveAsync(string path,
Dictionary<string, RedisValue> data)
{
var tempPath = path + ".tmp";
await using (var stream = File.Create(tempPath))
await using (var writer = new BinaryWriter(stream))
{
writer.Write(data.Count);
foreach (var (key, value) in data)
{
writer.Write(key);
writer.Write((byte)value.Type);
writer.Write(value.StringValue ?? "");
writer.Write(value.ExpiresAt?.Ticks ?? -1);
}
}
// Atomic rename — the old snapshot is replaced only
// after the new one is fully written
File.Move(tempPath, path, overwrite: true);
}
public async Task<Dictionary<string, RedisValue>> LoadAsync(
string path)
{
if (!File.Exists(path))
return new Dictionary<string, RedisValue>();
var data = new Dictionary<string, RedisValue>();
await using var stream = File.OpenRead(path);
using var reader = new BinaryReader(stream);
var count = reader.ReadInt32();
for (int i = 0; i < count; i++)
{
var key = reader.ReadString();
var type = (RedisType)reader.ReadByte();
var strValue = reader.ReadString();
var expireTicks = reader.ReadInt64();
data[key] = new RedisValue
{
Type = type,
StringValue = strValue,
ExpiresAt = expireTicks == -1
? null
: new DateTime(expireTicks, DateTimeKind.Utc)
};
}
return data;
}
}The write-to-temp-then-rename pattern is critical. If the process crashes mid-write, the temp file is corrupt but the previous snapshot is intact. File.Move with overwrite: true is atomic on most filesystems — the directory entry switches in one operation. You never have a window where neither file is valid.
Choosing a strategy on startup
The startup sequence checks for both persistence files and picks the most complete source:
public async Task RestoreAsync()
{
// Prefer AOF if it exists — it's more up-to-date
if (File.Exists("appendonly.aof"))
{
await ReplayAofAsync("appendonly.aof", _store);
return;
}
if (File.Exists("dump.rdb"))
{
var data = await _snapshot.LoadAsync("dump.rdb");
foreach (var (key, value) in data)
_store.Set(key, value);
Console.WriteLine($"[RDB] Loaded {data.Count} keys");
}
}Real Redis supports running both simultaneously — AOF for durability, snapshots for fast recovery of large datasets. We keep it simple: one or the other, AOF preferred.
The durability spectrum
Every persistence choice sits on a spectrum between speed and safety:
There is no free lunch. You cannot have zero data loss, zero latency impact, and instant recovery. Every combination trades one property for another. This isn't a limitation of Redis or C# or any specific technology — it's a consequence of physics. Moving bits from volatile to stable storage takes time and energy. The only question is when and how much you're willing to pay.
The Channel architecture showed us that our dispatcher processes commands sequentially. That single-threaded guarantee now becomes a persistence advantage: since writes flow through one point, we can log them at one point. No distributed coordination, no two-phase commit. One file, one writer, one fsync policy.
Our Redis clone now survives restarts. It accepts connections, parses RESP, dispatches through a Channel, stores in memory, expires on schedule, and persists to disk. The question that remains is the one every engineer eventually asks about their system: how fast is it, really? And how does it compare to the thing it's imitating?