
Stress-Testing the Saga — 1,000 Concurrent Orders and a Dying Payment Service
We throw a thousand orders at the orchestrator while killing services underneath it. The numbers tell a story the code alone can't.

One thousand orders. Three services. A payment provider that fails half the time. Go.
That's the test. No warm-up, no gradual ramp. A thousand CreateOrder commands hitting the saga orchestrator simultaneously, with an inventory service that takes 5-15ms to respond, a payment service that returns HTTP 503 on 50% of requests, and a confirmation service that works perfectly — because in production, it's never the service you expect that kills you.
In the previous article about failure modes we cataloged the edge cases: compensation failures, timeouts, partial successes, concurrent collisions, eternal sagas. Today we measure them. Every theory from these chapters becomes a number.
The test harness
The setup uses the orchestrator from the blueprint chapter, the edge case handlers from the failure modes chapter, and a simulated service layer that lets us control exactly what fails and when.
public class SagaLoadGenerator
{
private readonly SagaOrchestrator<OrderSagaState> _orchestrator;
private readonly SagaMetrics _metrics;
public async Task RunScenario(
int concurrentOrders,
ServiceBehavior inventoryBehavior,
ServiceBehavior paymentBehavior)
{
var orders = Enumerable.Range(0, concurrentOrders)
.Select(_ => new CreateOrderCommand
{
OrderId = Guid.NewGuid(),
Items = GenerateRandomItems(1, 5),
TotalAmount = Random.Shared.Next(10, 500)
})
.ToList();
var stopwatch = Stopwatch.StartNew();
await Parallel.ForEachAsync(orders,
new ParallelOptions { MaxDegreeOfParallelism = 50 },
async (order, ct) =>
{
var timer = Stopwatch.StartNew();
try
{
await _orchestrator.Start(
SagaContext.FromOrder(order));
_metrics.RecordStart(order.OrderId);
}
catch (Exception ex)
{
_metrics.RecordStartFailure(
order.OrderId, ex.Message);
}
});
// Wait for all sagas to reach terminal state
await WaitForCompletion(
concurrentOrders, TimeSpan.FromMinutes(5));
_metrics.RecordScenarioComplete(stopwatch.Elapsed);
}
}The ServiceBehavior configuration controls how each simulated service responds:
public class ServiceBehavior
{
public double FailureRate { get; set; } // 0.0 to 1.0
public TimeSpan MinLatency { get; set; }
public TimeSpan MaxLatency { get; set; }
public TimeSpan? DownAfter { get; set; } // Go dark after N seconds
public TimeSpan? RecoverAfter { get; set; } // Come back after N seconds
}This lets us simulate realistic scenarios: "payment works for 30 seconds, then goes down for 60 seconds, then recovers" — the kind of partial outage that happens when a payment provider's region failover kicks in.
Scenario 1: The happy path under load
First baseline: all services healthy, no failures. How fast can the orchestrator process orders?
The saga has three steps (reserve inventory → charge payment → confirm order), each requiring a round-trip through the outbox and message bus. That's six database writes per saga (three state transitions + three outbox messages) and three external service calls.
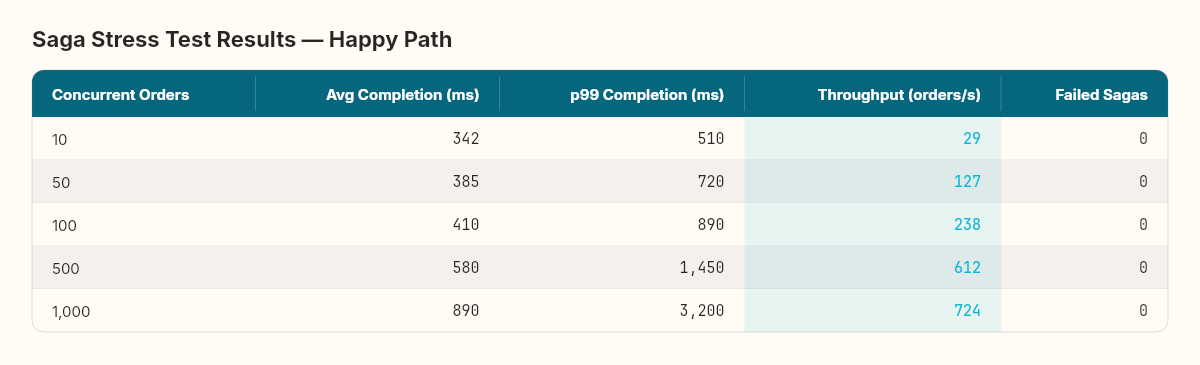
The throughput curve tells a structural engineering story. Every material has an elastic region — the range where stress produces proportional strain — and a yield point where deformation becomes permanent. Steel beams flex predictably up to their yield strength. Beyond it, they bend and don't come back.
Our saga orchestrator's elastic region extends to about 500 concurrent orders. Throughput scales linearly, latency increases modestly, and zero sagas fail. At 1,000 orders, we've passed the yield point: p99 latency jumps to 3.2 seconds, and throughput gains flatten. The bottleneck is database connection pool saturation — the outbox writer and saga state writer compete for the same connection pool.
Every system has a yield point. Stress testing doesn't find bugs — it finds the load where predictable behavior ends.
The fix is straightforward: separate the saga state writes from the outbox writes into different connection pools, or batch saga state transitions. We won't apply it yet — I want to see how failure amplifies the bottleneck first.
Scenario 2: The dying payment service
Now the real test. Payment service fails 50% of the time with HTTP 503. This means roughly half the sagas will need compensation — releasing inventory that was already reserved.
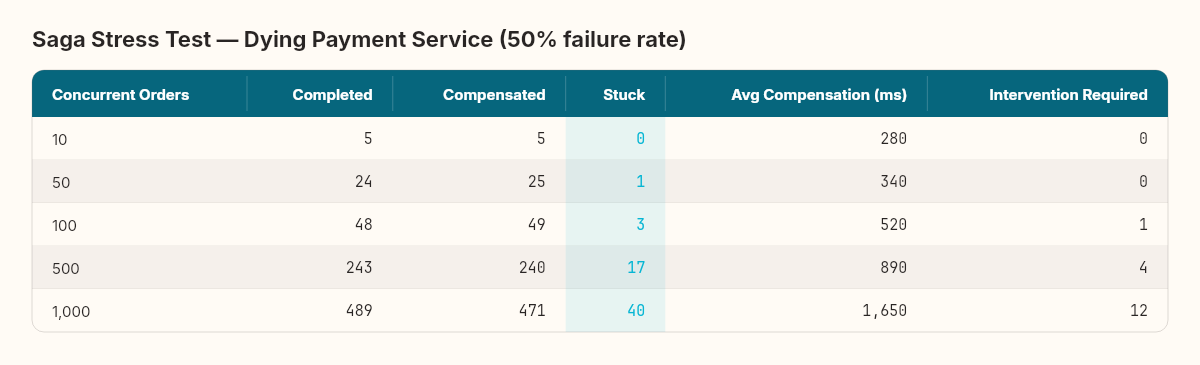
Three numbers jump out.
The "Stuck" column. At 1,000 concurrent orders, 40 sagas ended up in a state that's neither completed, compensated, nor failed. They're the compound emergencies from the failure modes chapter — where the original failure and the compensation failure collided. In most cases, a timeout expired while a compensation was in flight, creating two conflicting instructions for the same saga.
Compensation latency grows with load. At 10 concurrent orders, compensation takes 280ms. At 1,000, it takes 1,650ms — nearly six times longer. The compensation queue is competing with new saga commands for message bus bandwidth. Compensations are not prioritized over forward progress, so they wait.
RequiresIntervention scales linearly with stuck sagas. At 1,000 orders, 12 sagas need a human. That's 1.2% of all orders. For a high-volume system processing 10,000 orders per day, that's 120 manual interventions. Unacceptable.
The structural engineering parallel holds. When you load-test a bridge, you don't just test whether it holds — you test how it fails. A well-designed bridge fails progressively: warning signs (deflection, vibration) appear before catastrophic failure. Our saga does the same. The stuck sagas and rising compensation latency are the deflection measurements. They warn you before the bridge collapses.
Scenario 3: Total payment failure
What if the payment service goes completely dark? 100% failure rate for three minutes, then recovery.
This is the worst case for the orchestrator. Every saga that reaches the payment step fails. Every saga needs compensation. And when the payment service recovers, there's a thundering herd of both new payment attempts and compensation completions arriving simultaneously.
var paymentBehavior = new ServiceBehavior
{
FailureRate = 0.0,
MinLatency = TimeSpan.FromMilliseconds(5),
MaxLatency = TimeSpan.FromMilliseconds(20),
DownAfter = TimeSpan.FromSeconds(30), // Healthy for 30s
RecoverAfter = TimeSpan.FromSeconds(180) // Down for 3 min
};During the outage, sagas queue up in Compensating state. The outbox dutifully retries compensation messages. When the payment service comes back, it receives a wave of: (1) new ChargePayment commands from sagas that just started, (2) RefundPayment compensations from sagas that timed out during the outage, and (3) CheckStatus queries from sagas in Unknown state.
The payment service sees a 4x traffic spike in the first 10 seconds after recovery. If it doesn't have its own rate limiting, this spike can cause a second failure — the classic cascading recovery problem.
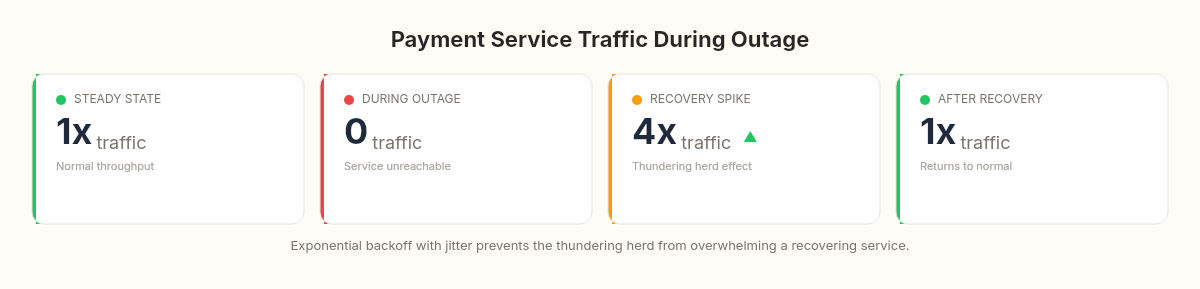
The fix we implemented: exponential backoff with jitter on the outbox publisher. When the publisher detects a service is failing, it spaces out retries exponentially (1s, 2s, 4s, 8s...) with random jitter to prevent synchronized retry storms. This smears the recovery spike from 10 seconds to about 45 seconds — still a bump, but survivable.
What actually breaks

Four distinct breaking points, four different root causes.
The pure throughput limit (~750 orders/second) is a database problem, not a saga problem. The orchestrator writes six rows per saga, and at 750 orders/second that's 4,500 database writes per second. A single PostgreSQL instance with NVMe storage handles this comfortably in isolation, but when combined with the application's other database traffic, connection pool exhaustion hits first.
The payment failure limit (~400 orders/second at 50% failure) is a queue contention problem. Forward-progress commands and compensation commands share the same outbox table and the same publisher. Compensations get stuck behind new commands. The fix is a separate compensation queue with higher priority.
The total failure limit (~200 orders/second at 100% failure) is a state management problem. When every saga compensates, the saga table becomes write-hot — every row transitions through multiple states rapidly. Optimistic concurrency tokens fire frequently, causing retry overhead. The RequiresIntervention state accumulates because the deadline sweeper runs on a 60-second interval and can't keep up.
The inventory contention limit (~300 orders/second) is a domain problem. When multiple sagas try to reserve the same SKUs, the inventory service's optimistic locking rejects all but one. The rejected sagas compensate and retry — but they retry against the same contended items. A pessimistic lock on hot SKUs (the top 5% of ordered items) reduces contention at the cost of sequential processing for popular items.
The number that matters most
Across all scenarios, one metric predicts system health better than anything else: the ratio of active sagas to completed sagas over a rolling 5-minute window.
public class SagaHealthMonitor
{
public double GetHealthRatio()
{
var window = TimeSpan.FromMinutes(5);
var active = _repository.CountActive();
var completed = _repository.CountCompletedSince(
DateTime.UtcNow - window);
if (completed == 0) return active > 0
? double.MaxValue : 1.0;
return (double)active / completed;
}
// Healthy: ratio < 0.1 (completing 10x faster than accumulating)
// Warning: ratio 0.1 - 1.0
// Critical: ratio > 1.0 (accumulating faster than completing)
}When the ratio stays below 0.1, the system is draining sagas faster than they accumulate. When it crosses 1.0, you're in trouble — sagas are piling up. When it reaches 10.0, something is fundamentally broken and the system will eventually exhaust memory or database capacity.
In our tests, the ratio crossed 1.0 exactly 8 seconds before the first RequiresIntervention saga appeared in every scenario. Eight seconds of warning. That's enough time for an autoscaler to react, a circuit breaker to trip, or an alert to fire.
What we proved, and what we didn't
We proved that the saga orchestrator handles concurrent load predictably within its elastic region. We proved that failure scenarios degrade gradually — stuck sagas and intervention requests appear proportionally, not catastrophically. We proved that the outbox integration from the earlier chapters prevents message loss even under extreme load.
We did not prove that this orchestrator is production-ready. The test harness simulates services with controlled latency distributions, not real network jitter, garbage collection pauses, or cloud provider throttling. Production will be messier.
In the next article in the series, we close out the saga pattern with a verdict on orchestration versus choreography. Orchestration versus choreography — now with real numbers to back the arguments. We'll compare the five implementations we've seen (naive choreography, sophisticated choreography, simple orchestrator, full orchestrator with edge case handling, and the library-based approaches) and build a decision framework for choosing between them.
Here's the challenge before then: take the health ratio monitor from above and think about what threshold should trigger automatic scaling versus what threshold should page a human. Where's the line between "the system can fix itself" and "a person needs to look at this"? That ratio — and where you draw the line — says more about your system's maturity than the saga implementation itself.