
The CQRS Verdict — When Separation Earns Its Complexity
We split the read and write models, handled the edge cases, found the resonant frequency at 3,200 commands per second. Now the honest question: was the separation worth it?

I recommended CQRS to a team that didn't need it.
Three years ago. Enterprise insurance platform, Dublin. The domain was complex — policy lifecycle management, underwriting workflows, regulatory audit trails. Complex enough that I said: "We should separate reads and writes. Different optimization profiles. Different scaling needs." The team agreed. We built it.
Six months later, the write side had four command handlers. Four. The read side had three projections. The entire system processed around 200 requests per minute at peak. We'd built a runway capable of handling 747s for an airport that served prop planes.
The CQRS was technically correct. The domain events were clean. The projections were fast. But we'd added roughly 40% more code, a separate projection pipeline, eventual consistency semantics that confused the front-end team, and a debugging surface that required correlating events across two models. For a system that would have been perfectly served by a single EF Core DbContext with some well-placed read-only views.
That experience is why this verdict exists: not as advocacy, but as a cost-benefit analysis.
Separation of powers
In 1787, the framers of the United States Constitution faced a design problem that maps almost perfectly to CQRS. A single governing body handling legislation, enforcement, and interpretation had been tried — monarchies, parliaments with unchecked authority, colonial governors serving all three functions. It worked at small scale. At national scale, the conflation of responsibilities bred corruption, bottlenecks, and decisions optimized for the decision-maker rather than the governed.
Their solution was separation of powers. Legislative, executive, judicial — three branches, each with a different data model of the same underlying reality (the law), each optimized for a different operation (creating law, enforcing law, interpreting law).

The insight wasn't that separation is always better. It's that separation has a threshold. Below a certain complexity of governance, a town council handling all three functions works fine. Above that threshold, the coordination cost of separation is less than the corruption cost of conflation.
CQRS follows the same curve.
The decision framework
After building CQRS three times — once where it was unnecessary, once where it was essential, and once where we ripped it out after six months — I've arrived at a framework with three axes.
Axis 1: Read/Write asymmetry. How different are your read and write patterns? If your dashboard needs denormalized aggregates across five tables while your writes touch a single aggregate root, the asymmetry is high. If your reads and writes hit the same shape of data, the asymmetry is low.
Axis 2: Scale divergence. Do reads and writes need to scale independently? A reporting dashboard serving 50,000 concurrent users while the back office processes 100 orders per hour has extreme scale divergence. A CRUD application where reads and writes are roughly proportional has none.
Axis 3: Model complexity. How many domain invariants does your write model enforce? If the answer is "validate some fields and save," CQRS adds ceremony without value. If the answer is "enforce business rules across multiple aggregates, emit domain events for downstream processes, and maintain complex state transitions," the write model benefits from isolation.

Score each axis 1-5. If the total is below 7, a single model serves you better. Between 7 and 11, consider CQRS with shared storage (same database, different query paths). Above 11, full CQRS with separate read and write stores earns its complexity.
The question isn't whether CQRS is a good pattern. It's whether your system has crossed the threshold where separation costs less than conflation.
The tool landscape
If you've decided CQRS fits, three approaches dominate the .NET ecosystem.
MediatR (hand-rolled + library)
// The approach we built this week — explicit, no magic
public class CreateOrderCommandHandler
: IRequestHandler<CreateOrderCommand, Guid>
{
public async Task<Guid> Handle(
CreateOrderCommand cmd, CancellationToken ct)
{
var order = Order.Create(cmd.CustomerId, cmd.Items);
await _writeDb.Orders.AddAsync(order, ct);
await _writeDb.SaveChangesAsync(ct);
foreach (var evt in order.DomainEvents)
await _mediator.Publish(evt, ct);
return order.Id;
}
}What it gives you: Explicit command/query separation with minimal ceremony. You own the projection pipeline, the event handling, the error recovery. The pipeline behaviors (validation, logging, authorization) are clean and composable.
What it costs: You build everything. Projection handlers, checkpoint tracking, error recovery, read model rebuilds — all yours. As the stress test showed, a naive projection handler caps at ~330 events per second before you optimize.
Wolverine (opinionated framework)
// Wolverine's cascading handler — framework manages events
public static (OrderCreated, OrderItemAdded[]) Handle(
CreateOrderCommand cmd, OrderDbContext db)
{
var order = Order.Create(cmd.CustomerId, cmd.Items);
db.Orders.Add(order);
return (
new OrderCreated(order.Id),
cmd.Items.Select(i => new OrderItemAdded(order.Id, i)).ToArray()
);
}What it gives you: Cascading messages (return events, framework publishes them). Built-in outbox (Marten or EF Core). Automatic retry policies. Integration with Marten for event sourcing. The projection pipeline is managed — batching, parallelism, error handling come built-in.
What it costs: Framework coupling. Wolverine conventions permeate your codebase. The "cascading return" pattern is elegant but unfamiliar to developers from MediatR backgrounds. Debugging framework-managed pipelines requires understanding Wolverine's internals.
Hand-rolled (no framework)
// Pure manual approach — maximum control
public class CommandDispatcher
{
private readonly IServiceProvider _sp;
public async Task<TResult> DispatchAsync<TResult>(
ICommand<TResult> command)
{
var handlerType = typeof(ICommandHandler<,>)
.MakeGenericType(command.GetType(), typeof(TResult));
dynamic handler = _sp.GetRequiredService(handlerType);
return await handler.HandleAsync((dynamic)command);
}
}What it gives you: Zero external dependencies. Full control over every pipeline stage. The mental model is simple: commands go in, events come out, projections consume events. No magic, no conventions, no upgrade risk.
What it costs: Everything is manual. You'll rebuild pipeline behaviors that MediatR gives you for free. You'll rebuild the outbox integration that Wolverine handles automatically. For small teams, this is fine. For larger systems, you're maintaining infrastructure instead of writing domain logic.

Composing the three weeks
The real power of CQRS emerges when it composes with the patterns we built for the outbox and saga chapters. The outbox ensures events reach the projection pipeline reliably. The saga orchestrates multi-step processes that span command handlers. CQRS separates the read and write concerns so each pattern operates in its natural domain.
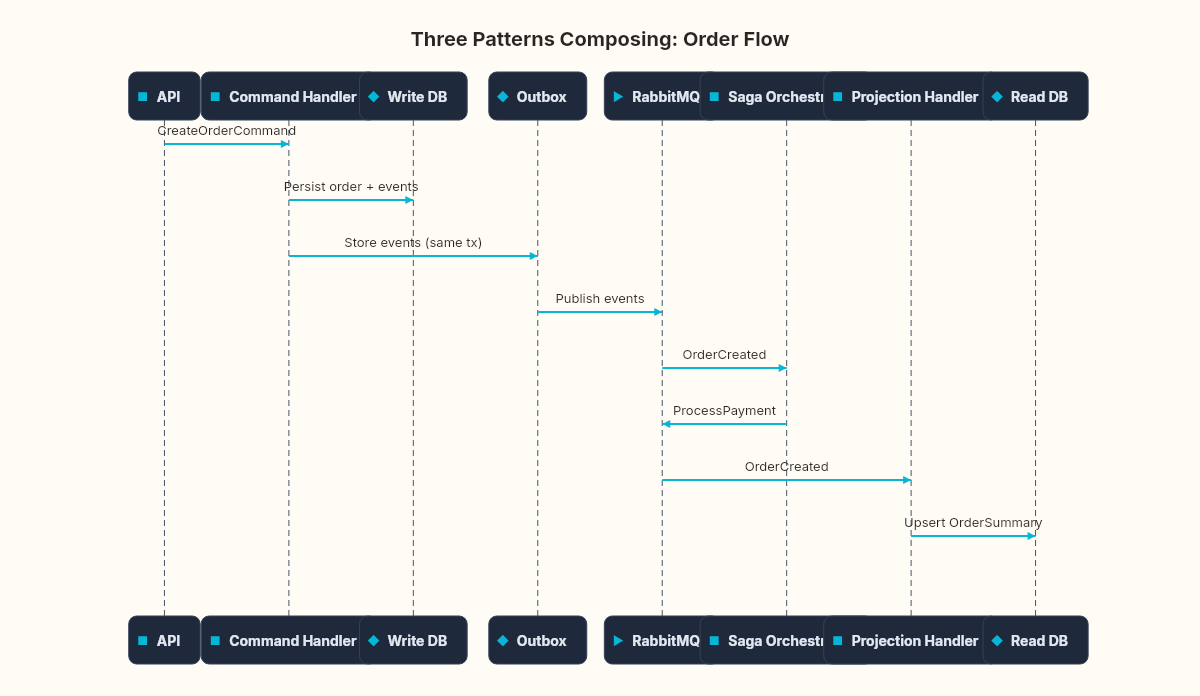
The composition sequence for a single order:
Command handler (CQRS write side) validates and persists the order, emitting domain events
Outbox (from when we built the outbox) captures those events transactionally alongside the write
Outbox publisher relays events to the message broker
Saga orchestrator (from the saga orchestration work) picks up the
OrderCreatedevent and initiates the payment → inventory → shipping workflowProjection handler (CQRS read side) consumes the same events to update the dashboard
Each saga step's completion event flows back through the outbox, updating both the saga state and the read model
Three patterns. Three weeks. One coherent system where each pattern handles the concern it was designed for.
The complexity budget
Every pattern has a cost. Here's what three weeks of building, breaking, and measuring taught us:
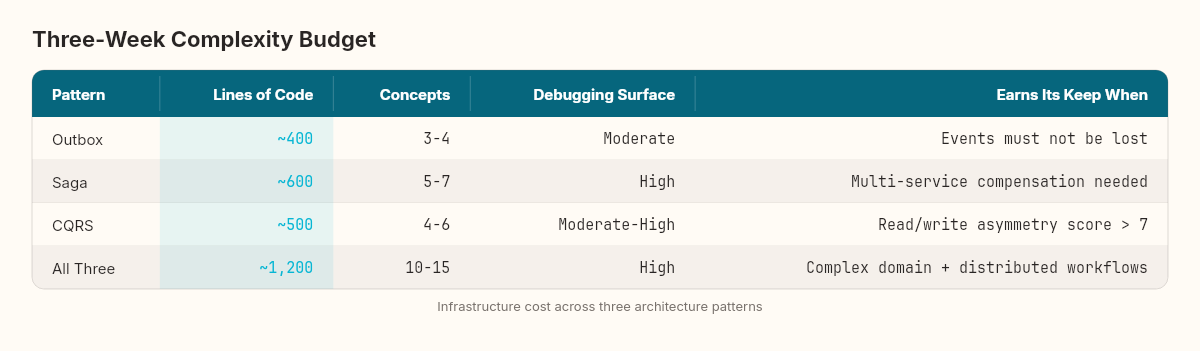
The combined system is roughly 1,200 lines of infrastructure code supporting whatever domain logic sits on top. For a system processing 200 requests per minute, that's over-engineering. For a system processing 20,000 orders per hour across five services with different read and write profiles, it's the minimum viable architecture.
When not to use CQRS
The most useful output of this week isn't the code. It's the list of situations where CQRS actively hurts:
CRUD applications. If your domain is "receive data, validate fields, save to database, display on a form" — CQRS adds a projection pipeline to a system that gains nothing from it. Use a single DbContext. Use AutoMapper if the read shape differs slightly. Move on.
Small teams with high velocity needs. CQRS requires the team to understand eventual consistency, projection lag, event ordering, and dual-model debugging. If your team is three developers shipping fast in a startup, the conceptual overhead slows you down more than the technical benefits speed you up.
Systems where consistency matters more than performance. If a user absolutely must see the latest state immediately after writing — financial ledgers viewed during reconciliation, real-time auction bidding, collaborative document editing — the eventual consistency window of CQRS creates more problems than the performance separation solves. You'll end up adding read-your-own-writes hacks that undermine the entire pattern.
Greenfield without evidence. Don't start with CQRS. Start with a single model. Monitor read and write patterns in production. When the data shows asymmetry, divergent scaling needs, or model complexity that a single context can't serve cleanly — then separate. The stress test from the previous chapter gives you the tool to measure whether you've crossed the threshold.
Three weeks, three patterns, one logbook entry
We started three weeks ago with a message that disappeared between a database commit and a RabbitMQ publish. We ended with a system that reliably coordinates multi-service workflows through command-driven writes, event-sourced sagas, and optimized read models — all connected by the outbox that ensures nothing gets lost in transit.
Each pattern solved one problem cleanly:
The outbox solved reliable event publishing
The saga solved multi-step coordination with compensation
CQRS solved the tension between write-optimized and read-optimized models
Each pattern introduced one new class of problems:
The outbox introduced duplicate delivery and ordering concerns
The saga introduced partial failure and timeout management
CQRS introduced projection lag and eventual consistency edge cases
The architecture logbook continues. The next arc explores a pattern that sits underneath all three — the one that records not just the current state, but every state transition that led to it. Event sourcing: the pattern that remembers everything.