
The Event Sourcing Blueprint — EventStoreDB, Aggregates, and Projections in .NET
Theory becomes code. We wire EventStoreDB to .NET, build an event-sourced aggregate, and project event streams into queryable read models.

Here's the entire write side of an event-sourced order:
await client.AppendToStreamAsync(
$"order-{orderId}",
StreamState.Any,
new[] { ToEventData(new OrderCreated(orderId, customerId, DateTime.UtcNow)) });One line. No DbContext. No SaveChangesAsync. No migration files. No UPDATE statement overwriting the previous state. You append an event to a stream, and the stream becomes the order's complete history.
Compare that with the EF Core equivalent we've been writing for the past three weeks — mapping classes, fluent configurations, change trackers, migrations. EventStoreDB strips all of that away. What's left is a database that stores events the way a film editor stores footage: every take, every angle, every cut preserved on the timeline. The final movie is assembled later.
That assembly is what we build today.
The raw footage problem
Film editors don't work with the finished movie. They work with raw footage — hours of dailies, multiple takes of every scene, B-roll, sound recordings, color tests. The raw footage is never cut or altered. It's immutable. The editor's job is to project a coherent narrative from that material.
Different editors produce different films from the same footage. The theatrical cut emphasizes pacing. The director's cut restores deleted scenes. The documentary uses the same behind-the-scenes footage to tell a completely different story. The raw material doesn't change. The projection does.
Event sourcing works the same way. The event stream is your raw footage — immutable, append-only, complete. Projections are your cuts — each one reads the same events and produces a different view optimized for a different audience. The order summary dashboard, the shipping fulfillment queue, the financial reconciliation report — all assembled from the same stream, each shaped for its consumer.
EventStoreDB is the vault where the footage lives.
Setting up EventStoreDB
EventStoreDB is an open-source database purpose-built for event sourcing. It stores events in streams, supports projections natively, and exposes a gRPC API that the .NET client wraps cleanly.
For local development, Docker gets you running in seconds:
docker run -d --name eventstore \
-p 2113:2113 -p 1113:1113 \
-e EVENTSTORE_INSECURE=true \
-e EVENTSTORE_RUN_PROJECTIONS=All \
-e EVENTSTORE_START_STANDARD_PROJECTIONS=true \
eventstore/eventstore:latestPort 2113 serves both the HTTP API and the admin UI. Port 1113 is the TCP protocol (legacy, but some tools still use it). The INSECURE flag disables TLS for local development — never in production.
Add the client NuGet package:
dotnet add package EventStore.Client.Grpc.Streams
dotnet add package EventStore.Client.Grpc.ProjectionManagementAnd configure the connection:
var settings = EventStoreClientSettings.Create("esdb://localhost:2113?tls=false");
var client = new EventStoreClient(settings);That's your pipeline to the vault.
The event-sourced aggregate
In the previous article about event sourcing theory, we defined event records — OrderCreated, ItemAdded, DiscountApplied. Now we need three things: a way to serialize events into EventStoreDB's format, an aggregate that applies events to rebuild state, and a repository that loads and saves streams.
Event serialization
EventStoreDB stores events as EventData objects — a type name, JSON payload, and optional metadata. The conversion is mechanical:
public static class EventSerializer
{
private static readonly JsonSerializerOptions Options = new()
{
PropertyNamingPolicy = JsonNamingPolicy.CamelCase,
WriteIndented = false
};
public static EventData ToEventData<T>(T evt) where T : IDomainEvent
{
var typeName = evt.GetType().Name;
var data = JsonSerializer.SerializeToUtf8Bytes(evt, Options);
return new EventData(Uuid.NewUuid(), typeName, data);
}
public static IDomainEvent Deserialize(ResolvedEvent resolved)
{
var json = resolved.Event.Data.Span;
return resolved.Event.EventType switch
{
nameof(OrderCreated) =>
JsonSerializer.Deserialize<OrderCreated>(json, Options)!,
nameof(ItemAdded) =>
JsonSerializer.Deserialize<ItemAdded>(json, Options)!,
nameof(DiscountApplied) =>
JsonSerializer.Deserialize<DiscountApplied>(json, Options)!,
nameof(OrderConfirmed) =>
JsonSerializer.Deserialize<OrderConfirmed>(json, Options)!,
nameof(OrderCancelled) =>
JsonSerializer.Deserialize<OrderCancelled>(json, Options)!,
_ => throw new InvalidOperationException(
$"Unknown event type: {resolved.Event.EventType}")
};
}
}The switch-on-string for deserialization is deliberate. When you add a new event type, the compiler won't catch the missing case — but the InvalidOperationException will, loudly, on the first replay. This is one of the trade-offs we flagged when discussing event sourcing theory: event schema awareness lives in your code, not in your database schema.
The aggregate
The Order aggregate from the theory chapter stays almost unchanged. The difference is that it now tracks uncommitted events — events raised during the current operation but not yet persisted:
public class Order
{
public Guid Id { get; private set; }
public decimal Total { get; private set; }
public OrderStatus Status { get; private set; }
public long Version { get; private set; } = -1;
private readonly List<IDomainEvent> _uncommittedEvents = new();
public IReadOnlyList<IDomainEvent> UncommittedEvents => _uncommittedEvents;
// --- Factory: create new order ---
public static Order Create(Guid orderId, Guid customerId)
{
var order = new Order();
order.Raise(new OrderCreated(orderId, customerId, DateTime.UtcNow));
return order;
}
// --- Command methods raise events ---
public void AddItem(Guid productId, int quantity, decimal price)
{
if (Status == OrderStatus.Cancelled)
throw new InvalidOperationException("Cannot add items to cancelled order.");
Raise(new ItemAdded(Id, productId, quantity, price));
}
public void ApplyDiscount(decimal percentage, string reason)
{
if (percentage is <= 0 or > 100)
throw new ArgumentOutOfRangeException(nameof(percentage));
Raise(new DiscountApplied(Id, percentage, reason));
}
public void Confirm()
{
if (Status != OrderStatus.Created)
throw new InvalidOperationException($"Cannot confirm order in {Status} state.");
Raise(new OrderConfirmed(Id, DateTime.UtcNow));
}
// --- Internal: raise + apply ---
private void Raise(IDomainEvent evt)
{
Apply(evt);
_uncommittedEvents.Add(evt);
}
// --- Rehydration: replay from history ---
public static Order Rehydrate(IEnumerable<(IDomainEvent Event, long Position)> history)
{
var order = new Order();
foreach (var (evt, position) in history)
{
order.Apply(evt);
order.Version = position;
}
return order;
}
private void Apply(IDomainEvent evt)
{
switch (evt)
{
case OrderCreated e:
Id = e.OrderId;
Status = OrderStatus.Created;
break;
case ItemAdded e:
Total += e.Quantity * e.Price;
break;
case DiscountApplied e:
Total *= (1 - e.Percentage / 100);
break;
case OrderConfirmed:
Status = OrderStatus.Confirmed;
break;
case OrderCancelled:
Status = OrderStatus.Cancelled;
break;
}
}
public void ClearUncommittedEvents() => _uncommittedEvents.Clear();
}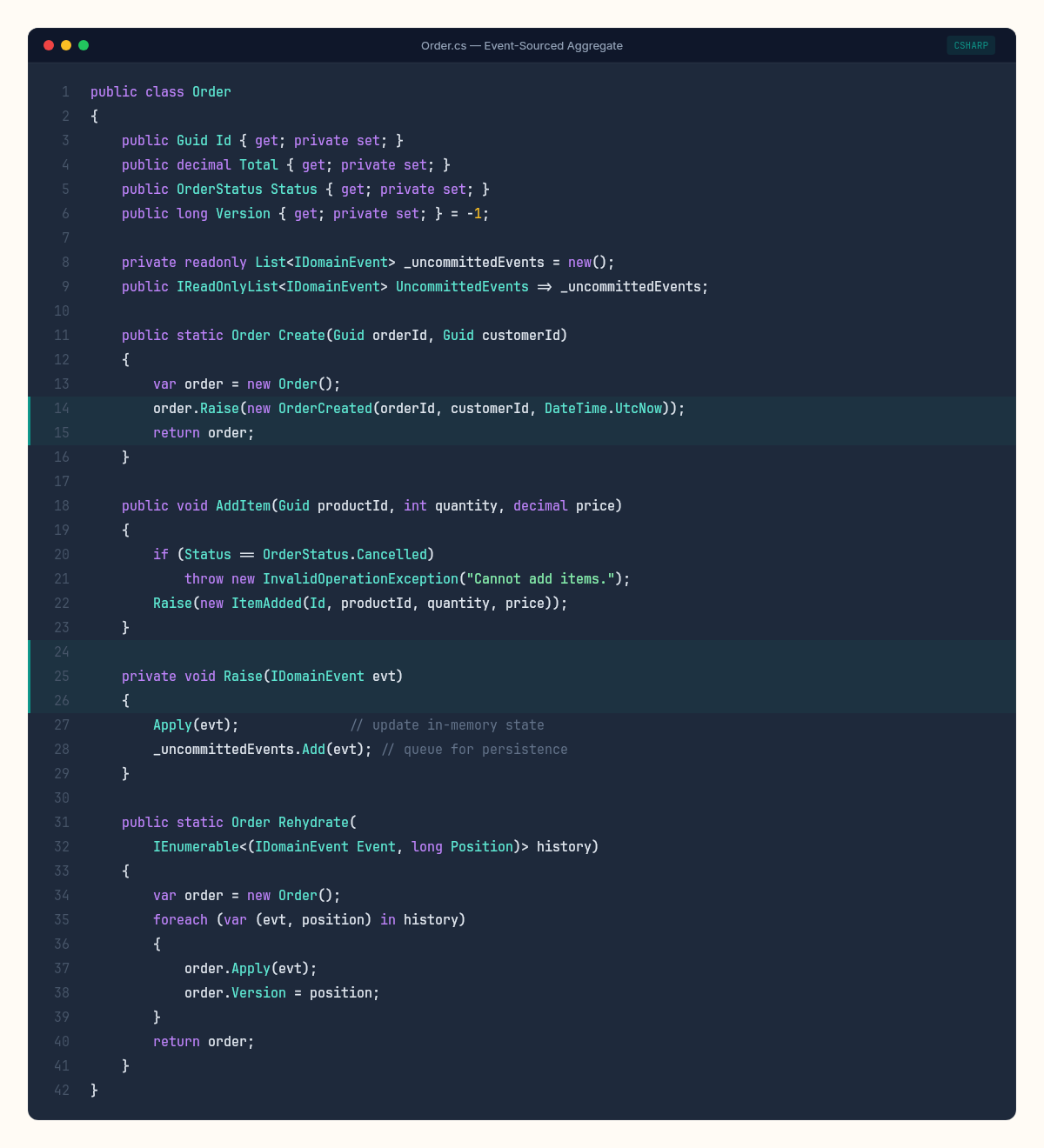
The pattern is strict: command methods validate, then call Raise. Raise calls Apply (to update in-memory state) and queues the event. Nothing writes to a database. The aggregate is a pure state machine with a pending event buffer.
The repository
The repository bridges the aggregate and EventStoreDB:
public class EventStoreOrderRepository
{
private readonly EventStoreClient _client;
public EventStoreOrderRepository(EventStoreClient client) => _client = client;
public async Task<Order> LoadAsync(Guid orderId)
{
var streamName = $"order-{orderId}";
var events = new List<(IDomainEvent, long)>();
var result = _client.ReadStreamAsync(
Direction.Forwards, streamName, StreamPosition.Start);
if (await result.ReadState == ReadState.StreamNotFound)
throw new OrderNotFoundException(orderId);
await foreach (var resolved in result)
{
var evt = EventSerializer.Deserialize(resolved);
events.Add((evt, resolved.Event.EventNumber.ToInt64()));
}
return Order.Rehydrate(events);
}
public async Task SaveAsync(Order order)
{
var streamName = $"order-{order.Id}";
var events = order.UncommittedEvents
.Select(EventSerializer.ToEventData)
.ToArray();
if (events.Length == 0) return;
var expectedRevision = order.Version == -1
? StreamRevision.None
: StreamRevision.FromInt64(order.Version);
await _client.AppendToStreamAsync(
streamName, expectedRevision, events);
order.ClearUncommittedEvents();
}
}The expectedRevision parameter is the optimistic concurrency guard. If another process appended events to this stream between your Load and Save, EventStoreDB rejects the write with a WrongExpectedVersionException. No row-level locks. No SELECT FOR UPDATE. The stream revision is the version vector.
Projections: assembling the cut
Events in the stream answer: what happened to order X? But your dashboard needs: how many orders are pending today? Your finance team needs: what's the total revenue this quarter? Your shipping system needs: which confirmed orders haven't shipped?
Each question is a different projection — a read model assembled from the event stream, optimized for one specific query pattern.
The subscription approach
EventStoreDB supports persistent subscriptions that push events to your consumer as they're appended. For .NET, the catch-up subscription is the workhorse:
public class OrderSummaryProjection : BackgroundService
{
private readonly EventStoreClient _client;
private readonly IServiceScopeFactory _scopeFactory;
private StreamPosition _lastProcessed = StreamPosition.Start;
public OrderSummaryProjection(
EventStoreClient client, IServiceScopeFactory scopeFactory)
{
_client = client;
_scopeFactory = scopeFactory;
}
protected override async Task ExecuteAsync(CancellationToken ct)
{
var subscription = _client.SubscribeToStream(
"$ce-order", // category projection: all order-* streams
FromStream.Start,
cancellationToken: ct);
await foreach (var message in subscription.Messages.WithCancellation(ct))
{
if (message is not StreamMessage.Event evt) continue;
using var scope = _scopeFactory.CreateScope();
var db = scope.ServiceProvider
.GetRequiredService<ReadModelDbContext>();
await ProjectEvent(db, evt.ResolvedEvent);
}
}
private async Task ProjectEvent(
ReadModelDbContext db, ResolvedEvent resolved)
{
var domainEvent = EventSerializer.Deserialize(resolved);
switch (domainEvent)
{
case OrderCreated e:
db.OrderSummaries.Add(new OrderSummaryRow
{
OrderId = e.OrderId,
CustomerId = e.CustomerId,
Total = 0,
Status = "Created",
CreatedAt = e.CreatedAt
});
break;
case ItemAdded e:
var order = await db.OrderSummaries
.FindAsync(e.OrderId);
if (order != null)
order.Total += e.Quantity * e.Price;
break;
case OrderConfirmed e:
var confirmed = await db.OrderSummaries
.FindAsync(e.OrderId);
if (confirmed != null)
confirmed.Status = "Confirmed";
break;
case OrderCancelled e:
var cancelled = await db.OrderSummaries
.FindAsync(e.OrderId);
if (cancelled != null)
cancelled.Status = "Cancelled";
break;
}
await db.SaveChangesAsync();
}
}The $ce-order stream is a built-in EventStoreDB category projection. It automatically aggregates all streams matching the prefix order-* into a single virtual stream. You subscribe once and receive events from every order.
The read model is a plain EF Core entity — OrderSummaryRow in a SQL Server or PostgreSQL table. The projection receives events and updates denormalized rows. Your API queries the read model directly, never touching the event store for reads.
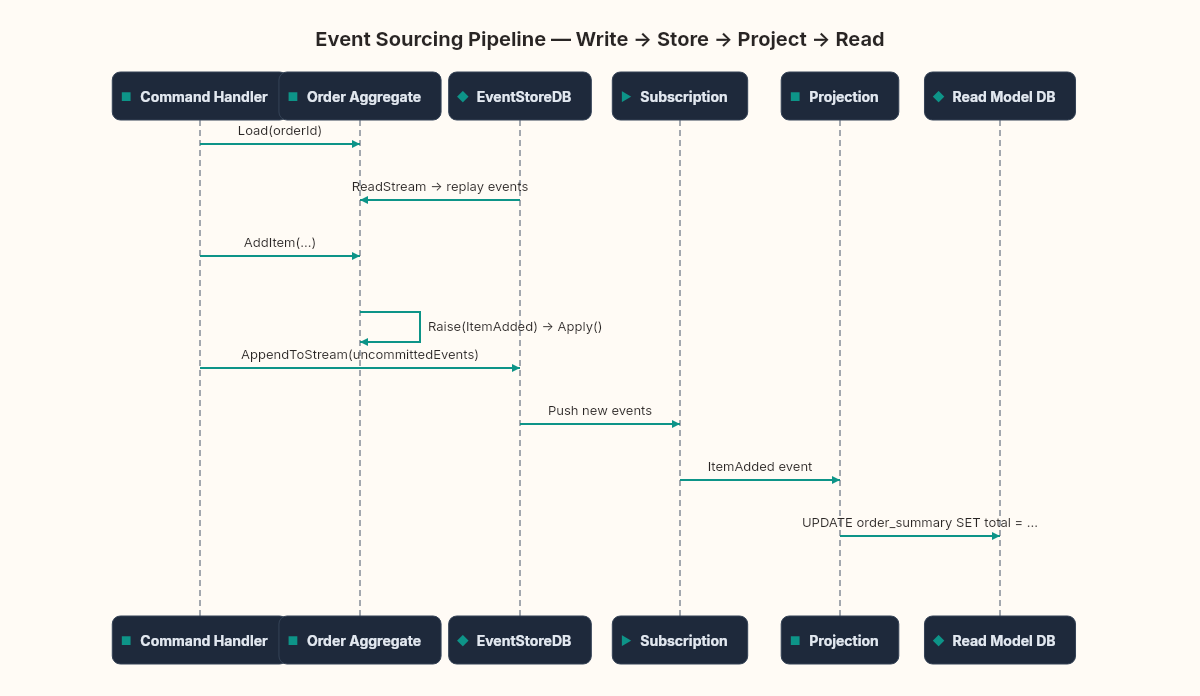
This is the CQRS pipeline from the previous weeks, but now the event store is the single source of truth. The write side appends events. The read side subscribes and projects. The gap between them is eventual consistency — the projection might lag the write by milliseconds to seconds, depending on throughput and processing speed.
Rebuilding: the director's cut
Here's the capability that makes event sourcing worth its trade-offs.
Three months after deployment, the product team asks for a new dashboard: revenue by region. In a traditional system, you'd need to add a column, backfill it from... where? The data was overwritten. In an event-sourced system, you write a new projection, subscribe from the beginning of time, and replay every event. The new read model assembles itself from the historical record.
// New projection — replay from start, build revenue-by-region
public class RevenueByRegionProjection : BackgroundService
{
protected override async Task ExecuteAsync(CancellationToken ct)
{
var subscription = _client.SubscribeToStream(
"$ce-order", FromStream.Start, cancellationToken: ct);
await foreach (var message in subscription.Messages.WithCancellation(ct))
{
if (message is not StreamMessage.Event evt) continue;
// Project into region-specific read model...
}
}
}No data migration. No backfill script. No "we only have data from when we added that column." The events were always there. You just hadn't asked that question yet.
This is the director's cut — same footage, different story. And you can create as many cuts as you need.

What we haven't solved yet
This blueprint gets the core pipeline working: commands produce events, aggregates enforce invariants, EventStoreDB persists streams, projections build read models. But several hard problems remain.
Event versioning. What happens when OrderCreated needs a new field six months from now? You can't ALTER TABLE on events that already happened. You need upcasting — transforming old events to new shapes during deserialization. The stress test article addresses this.
Snapshot strategies. An order with 500 events takes 500 replays to rehydrate. At some point, you snapshot the aggregate's current state and replay only from the snapshot forward. Where to draw that line is a performance question the next article in the series measures.
Stream growth. EventStoreDB handles millions of events, but streams growing unbounded affect read performance. Archival, soft deletes, and scavenge operations need planning.
The blueprint is the foundation — commands in, events out, projections flowing. The edge cases are where architecture becomes engineering.
Every append to the event store is permanent footage in the vault. Every projection is an editor's cut — shaped for its audience, rebuildable at will. The raw material never changes.
The next article in the series stress-tests the seams: what happens when event schemas evolve, when projections fail mid-stream, when you need to replay a million events and your read model is empty.