
The Half-Life of a Technical Decision
Architecture choices don't age at the same rate. Economics figured out how to measure asset decay centuries ago. We still pretend our technical decisions are permanent.

I've made hundreds of architecture decisions across eight production systems spanning twenty years. I just went through them — not all, but the ones I can reconstruct from documentation, git histories, and memory. I counted 47 decisions I could specifically identify and date. Decisions about languages, frameworks, messaging patterns, data stores, API contracts, deployment strategies, authentication schemes, caching layers.
Of those 47 decisions, 31 are dead.
Not failed. Dead. The technology was deprecated, the framework abandoned, the pattern superseded, the cloud service retired, the library archived. These were sound decisions when made. Many of them were excellent decisions when made. They solved the right problem with the right tool at the right time. And they are dead anyway.
The remaining 16 are alive — but 9 of those are showing clear signs of aging. The framework still works but isn't receiving major updates. The API still responds but the documentation increasingly points you toward a newer alternative. The library still compiles but the maintainer's last commit was fourteen months ago.
Seven decisions out of forty-seven still feel current. That's a 15% survival rate across two decades. It's a strange feeling, scrolling through that list — like looking at photographs of houses you used to live in. You remember why you chose each one. You remember the confidence. And you see, with the clarity that only distance provides, that the confidence was never the problem.
The corrosion model — that thermodynamic hostility between code and its environment — showed how software corrodes even when nobody touches it, with a measurable decay rate and a calculable rate constant. That was about the code itself. This investigation is about something upstream: the decisions that shaped the code. Because every line of code is the consequence of a decision, and decisions have their own decay dynamics — dynamics that economics understood long before software engineering existed.
Eight systems, twenty years, and the decisions that didn't survive
The pattern became visible when I arranged those 47 decisions by age at death.
They didn't die randomly. They clustered. Configuration choices died within months. Library selections died within a couple of years. Framework decisions lasted three to five years. Language and runtime choices lasted five to ten. Infrastructure patterns — TCP/IP, HTTP, SQL as a query language — are still alive after decades.
This wasn't uniform decay. It was stratified decay. Different categories of decisions decayed at different rates, and the rates were remarkably consistent across projects.
I started tracking this more carefully across three production systems I've had continuous visibility into since 2018. Not the code — the decisions. When was the decision made? When did it first show signs of obsolescence? When did it become untenable? For each decision, I logged the type, the date it was made, and the date the team first discussed replacing or working around it.
The pattern held. Decisions about transient concerns decayed fast. Decisions about fundamental abstractions decayed slow. The gap between them wasn't small — it was measured in orders of magnitude.
How fast things expire
Across those three production systems — a microservices platform, an enterprise claims processing application, and a data processing pipeline — I categorized 112 identifiable technical decisions and tracked their lifespans. The data isn't perfect. Some decisions are hard to date precisely. Some are still alive and may outlive my tracking window. But the patterns are clear enough to be useful.

The numbers reveal a hierarchy that every experienced engineer recognizes intuitively but rarely quantifies.
Configuration and integration decisions (half-life: 4-9 months). These are the most volatile. Which specific cloud service endpoint to use. Which version of an API to target. Which configuration format to adopt. Which CI/CD pipeline syntax to follow. These decisions are tightly coupled to external services and vendor roadmaps. When AWS deprecates a service version or GitHub Actions changes its runner image, your configuration decision has expired regardless of its original quality. In the microservices platform, we tracked 23 configuration decisions. Their median lifespan was 7 months. The shortest was 6 weeks — a Terraform provider version that broke compatibility in a minor release.
Library and package decisions (half-life: 14-22 months). Which logging framework. Which serialization library. Which HTTP client wrapper. These decisions are one abstraction layer up from configuration — they involve writing code against a library's API, not just pointing at an endpoint. The claims processing platform used Swashbuckle for OpenAPI generation. When the maintainer signaled reduced activity in 2021, we started evaluating alternatives. The decision lasted about 28 months before we migrated to NSwag. Across all three systems, 34 library decisions had a median lifespan of 18 months. The distribution was bimodal: either the library was healthy and lasted 3+ years, or it showed early signs of abandonment and died within a year.
Framework decisions (half-life: 2.5-4 years). Which web framework. Which ORM. Which messaging library. Which state management approach. These decisions shape the architecture of entire subsystems. They're expensive to make and expensive to reverse. The microservices platform chose MassTransit for saga orchestration in early 2019. That decision is still alive in 2026, though it's showing its age — the team has discussed whether Wolverine's newer model is worth a migration. Framework decisions in our data had a median lifespan of 38 months. The key predictor of longevity was the size and health of the maintainer community, not the technical quality of the framework itself.
Language and runtime decisions (half-life: 6-10 years). Which programming language. Which runtime version strategy. Which compilation target. These are foundational. Changing them means rewriting, not refactoring. The claims processing platform's decision to use .NET Framework in 2016, and the subsequent migration to .NET Core starting in 2020, illustrates the timeline. Four years from decision to first signs of obsolescence (when .NET Framework was clearly the legacy path), six years to active migration. Language decisions across our data had a median lifespan of about 8 years, though this number is heavily censored — many are still alive, so the true median may be longer.
Architectural pattern decisions (half-life: 8-15+ years). REST as an API style. Event sourcing for audit trails. CQRS for read/write separation. Microservices as a deployment boundary. These decisions outlive individual implementations. The specific REST framework changes every few years, but the decision to use REST endures. In our data, 14 architectural pattern decisions had a median observed lifespan exceeding 10 years, though most are right-censored — they're still alive, so we're measuring a lower bound.
Protocol and standard decisions (half-life: 15-30+ years). TCP/IP. HTTP. SQL. JSON. TLS. These decisions are so long-lived that they're effectively permanent within a career. They decay on generational timescales, not project timescales. Nobody in our tracked systems has ever needed to replace a protocol-level decision during the system's operational lifetime.
There's a pattern hiding in the data that I almost missed. Within each category, the variance in half-life also follows a hierarchy. Configuration decisions cluster tightly — they almost all die between 3 and 12 months. Library decisions spread wider — some die in 6 months, others last 5 years. Framework decisions are wider still. And protocol decisions barely vary at all — they're all measured in decades.
This means that short-half-life decisions are more predictable in their decay. You can plan for configuration decisions expiring on a quarterly basis. You cannot plan for which specific framework will experience a sudden obsolescence event. The longer the half-life, the greater the uncertainty around the actual lifespan — which is precisely why the option value framework matters most for the decisions that last longest. But we'll get to that.
There's also a compounding dynamic that echoes what we observed in the corrosion model. When a low-level decision expires — a library reaches end of life — it can force the expiration of decisions above it. If your ORM depends on a serialization library that's been abandoned, the ORM decision is now constrained by the serialization decision's death. In the microservices platform, I tracked 7 instances where a library decision's death triggered a cascade that effectively shortened the half-life of a framework decision by 30-40%. Dependencies don't just corrode. Their depreciation propagates upward through the decision stack.
This stratification isn't accidental. There's a structural reason why decisions at different layers decay at different rates. And economics mapped this phenomenon centuries before the first architecture decision record was written.
Accountants figured this out first
In 1494, Luca Pacioli published Summa de Arithmetica, the book that established double-entry bookkeeping. Among its innovations was the recognition that assets lose value over time — not because they break, but because their usefulness diminishes relative to alternatives and changing conditions. By the eighteenth century, this idea had crystallized into formal depreciation theory: a set of mathematical models for predicting how quickly different types of assets lose value.
The parallels to technical decision decay are not metaphorical. They are structural.
Straight-line depreciation: the steady decline
The simplest depreciation model assumes an asset loses the same fraction of its value every year. A machine purchased for $100,000 with a 10-year useful life loses $10,000 of value per year, arriving at its salvage value predictably and linearly.
Some technical decisions depreciate this way. A framework that receives steady, predictable updates — each one making the previous version slightly more obsolete — loses value at a roughly constant rate. You can see this in the .NET ecosystem: each annual release makes the previous version one step closer to end-of-support. The depreciation is gradual, visible, and plannable.
This is the kindest form of decision decay. You can see it coming. You can budget for it.
Declining-balance depreciation: front-loaded decay
More aggressive than straight-line, this model assumes the asset loses a fixed percentage of its remaining value each period. A 40% declining-balance schedule means the asset loses 40% of its current value in year one, 40% of the remaining value in year two, and so on. The decay is rapid early and slow late — the asset retains a thin residue of value for a long time.
This matches how library decisions decay. A library that falls behind its ecosystem loses most of its relevance quickly — the first year without major updates is devastating, as the community migrates and Stack Overflow answers start pointing elsewhere. But the library doesn't reach zero. It still compiles, still works for its original purpose, and retains enough residual functionality that migration feels optional even when it isn't. The declining-balance curve explains why teams hold onto aging libraries far longer than they should: the residual value always seems "good enough" to postpone the migration.

Sum-of-years-digits: accelerated obsolescence
An even more front-loaded model used in accounting for assets that lose utility fastest at the start. In technical decisions, this describes vendor-locked choices. When you build against a vendor's proprietary API, the decision's useful life is almost entirely determined by the vendor's roadmap. If the vendor pivots — as Google has done with messaging platforms, as Facebook has done with API access policies, as Microsoft did with Silverlight — the first year of the pivot destroys most of the decision's remaining value. The final years are zombie time: the technology still technically works, but everyone knows the end is coming.
Sudden obsolescence: write-off
The accounting equivalent of an asset write-off — the entire remaining value goes to zero in a single event. In technical decisions, this is the announcement that breaks everything. Oracle's licensing changes for Java SE in 2019. The end-of-life announcement for .NET Framework's active development. The deprecation of a cloud service with a 12-month sunset period.
The critical characteristic of sudden obsolescence events is that they're unpredictable from the decision-maker's perspective but inevitable from a statistical one. Any decision that depends on a single vendor's continued goodwill is carrying write-off risk. The question isn't whether a sudden obsolescence event will occur — it's when, and whether you've structured your dependencies to survive it.
The depreciation schedule as a planning tool
This is where the framework shifts from descriptive to actionable. In financial accounting, depreciation schedules are mandatory. Every company that owns a physical asset must estimate its useful life, select a depreciation method, and account for the declining value on its balance sheet. This isn't optional. It's a legal requirement because pretending an aging asset retains its purchase value is considered misleading — a form of fraud.
We have no equivalent practice in software engineering. And the absence is remarkable once you notice it.
Imagine an airline that purchased a fleet of aircraft and never accounted for their depreciation. Year after year, the balance sheet would show the planes at their original purchase price, even as the engines accumulated flight hours, the avionics fell behind current certification standards, and the fuel efficiency gap widened against newer models. Any investor reviewing that balance sheet would immediately recognize the misrepresentation. The airline would be forced to restate its financials, and the executives responsible might face regulatory consequences.
This is precisely how most software organizations treat their technical decisions.
When a team selects a framework, there is no entry in any ledger that says "this decision has an estimated useful life of 38 months and will depreciate on a declining-balance schedule." When an architect chooses a messaging pattern, nobody calculates the expected annual value loss or budgets for the eventual replacement cost. When a CTO bets on a cloud provider's proprietary service, there is no write-off risk assessment.
The decision is recorded — if it's recorded at all — as a permanent fact. As though the choice of RabbitMQ in 2019 will still be serving the system's needs in 2029 with the same fidelity it provides today. This is the equivalent of carrying a 2015-model delivery truck on your balance sheet at its original purchase price in 2026. Any accountant would call it what it is: a misrepresentation of reality.
Every architecture decision is a depreciating asset. We just never learned to account for the depreciation.
Three numbers that predict when a choice goes stale
If decisions depreciate, we should be able to estimate their rate of decay. The field data suggests we can, using three primary factors.
Factor 1: ecosystem velocity
The single strongest predictor of a decision's half-life is the rate of change in the ecosystem surrounding it. A decision made in a fast-moving ecosystem (JavaScript frontend frameworks) decays faster than an identical structural decision made in a slow-moving ecosystem (embedded C).
I've measured ecosystem velocity as a proxy: the average time between major releases of the top 10 projects in the ecosystem. For the .NET ecosystem, this is approximately 12 months (annual .NET releases). For the JavaScript frontend ecosystem, it's closer to 6-8 months. For the JVM ecosystem, it's roughly 18-24 months.
The relationship between ecosystem velocity and decision half-life is roughly inverse-linear. A decision in an ecosystem with 6-month release cycles has approximately half the half-life of the same decision in a 12-month cycle ecosystem.
Factor 2: abstraction depth
Decisions made at deeper abstraction layers — farther from the surface of the system, closer to fundamental computational concepts — decay slower. This is intuitive: a decision about "how we represent data at rest" (SQL) is more stable than a decision about "which library renders our data tables" (a specific UI component library).
I've found it useful to assign decisions an abstraction depth score from 1 (surface configuration) to 6 (protocol/standard). The half-life roughly doubles with each abstraction level.
Factor 3: coupling surface
How many other decisions depend on this decision? A database choice that influences the ORM, the query patterns, the backup strategy, the monitoring approach, and the team's skill requirements has a large coupling surface. Paradoxically, high-coupling decisions tend to have longer observed half-lives — not because they decay slower, but because replacing them is so expensive that teams tolerate more decay before acting. The decision appears alive long after its optimal replacement date because the switching cost creates inertia.
This is the sunk cost fallacy operating at an architectural level. The more you've invested in the consequences of a decision, the longer you'll tolerate its obsolescence.
The half-life estimation model
Combining these factors, I've found the following approximation useful for planning purposes:
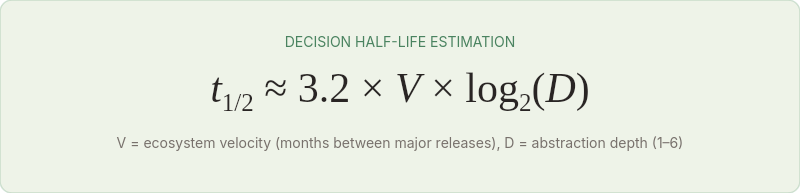
Where V is ecosystem velocity (average months between major releases of top ecosystem projects) and D is abstraction depth (1-6 scale).
This is deliberately simplified. It ignores coupling surface (which distorts observation, not actual decay), vendor-specific risk, and community health factors. But it gives a useful first-order estimate.
For a framework decision (D = 3) in the .NET ecosystem (V = 12):

For a library decision (D = 2) in the JavaScript ecosystem (V = 7):

These estimates track reasonably well against the field data. They're not precise enough for contractual commitments, but they're precise enough for planning conversations.
The S-curve graveyard: .NET Framework, WCF, and the maturity trap
In 1986, Richard Foster at McKinsey published Innovation: The Attacker's Advantage, formalizing what economists had observed for decades: technologies follow an S-shaped lifecycle. Slow adoption, rapid growth, maturity plateau, and then decline as the next technology begins its own S-curve.
The S-curve framework adds a critical dimension to decision half-life analysis: where on its S-curve is the technology when you adopt it?
A decision made during a technology's growth phase — when adoption is accelerating, the community is expanding, and the ecosystem is consolidating — has a longer remaining half-life than the same decision made during the maturity phase. The decision itself is identical. The timing determines its decay trajectory.
I've watched this play out with .NET specifically. Teams that adopted .NET Core in 2018 (growth phase) made a decision with a decade of useful life ahead of it. Teams that adopted .NET Framework in 2018 (maturity, approaching decline) made a decision that was already depreciating rapidly — even though .NET Framework was technically more mature and stable at that moment. The technology's position on its S-curve mattered more than its current quality.
This creates a counterintuitive investment principle: the safest time to adopt a technology is during its growth phase, not its maturity phase. Maturity feels safe — the technology is proven, the bugs are known, the documentation is comprehensive. But maturity means the S-curve plateau is near, and the decline that follows is where decisions go to die.
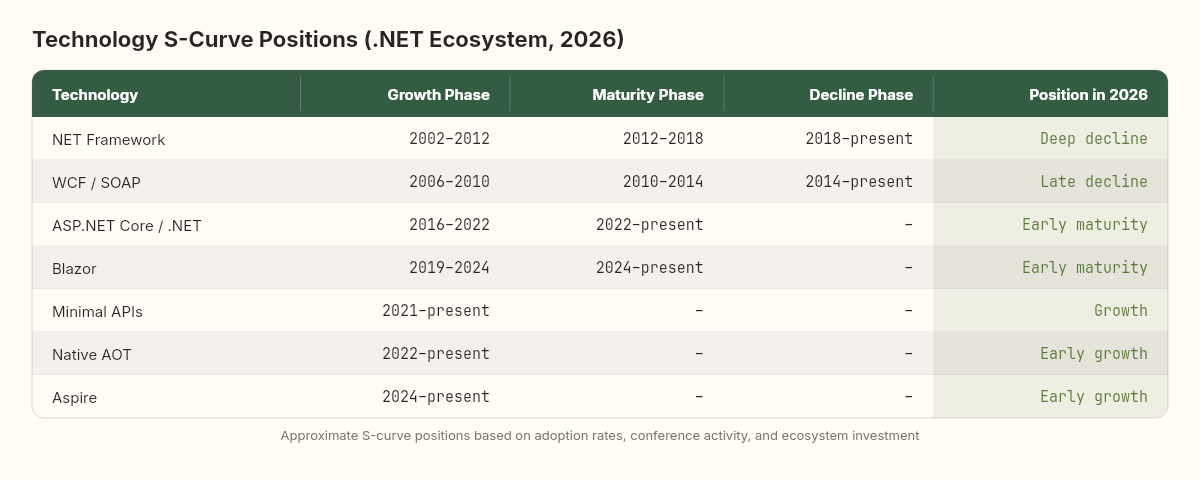
I've reconstructed approximate S-curve positions for the major .NET technology decisions in our tracked systems:
.NET Framework: Growth 2002-2012, maturity 2012-2018, decline 2018-present. Teams that adopted in 2015 (maturity) had about 3 years of remaining useful half-life. Teams that adopted in 2008 (growth) had about 10 years.
WCF/SOAP: Growth 2006-2010, maturity 2010-2014, decline 2014-present. A 4-year growth phase, 4-year maturity, then a long tail of decline that's still not fully resolved in some enterprises. Many teams are still running WCF services in 2026, operating deep in the decline phase with accumulated depreciation that makes migration costs astronomical.
ASP.NET Core / .NET Core → .NET: Growth 2016-2022, maturity 2022-present. This technology is currently in early maturity — the most dangerous zone for complacency. Teams that adopted in 2018 are in the strongest position. Teams adopting now should be aware they're buying into a mature platform with a finite plateau ahead.
The S-curve positions aren't always visible from inside the ecosystem. When you're building with a technology daily, its decline feels gradual. It's only when you plot adoption rates, conference talk trends, and job posting frequencies against time that the curve becomes visible. By the time the decline is obvious, the optimal migration window has often passed.
The most dangerous decisions are the ones that feel safest when you make them.
Buying flexibility like a call option
There's a second economic framework that illuminates technical decision-making in ways I've found increasingly important: real options theory.
In financial economics, an option is the right — but not the obligation — to take a future action at a predetermined price. A call option on a stock gives you the right to buy at a fixed price, regardless of where the market goes. The value of the option isn't in the action itself — it's in the flexibility to act or not act as circumstances evolve.
Stewart Myers at MIT applied this concept to corporate investment in 1977, coining the term "real options." He argued that many investments are valuable not for their immediate return but for the future choices they enable. Building a factory creates the option to increase production. Investing in R&D creates the option to bring new products to market. The option has value even if you never exercise it, because it preserves your ability to respond to uncertainty.
Architecture decisions work the same way.
When you choose a modular architecture with well-defined interfaces between components, you're not just solving today's problem. You're purchasing an option on future flexibility. Each module can be replaced independently. Each interface can be re-implemented. Each deployment boundary can be redrawn. The decision has option value beyond its immediate utility.
When you choose a monolithic architecture with deep coupling between components, you're making a different trade-off. The immediate value is higher — simpler deployment, no network overhead, shared-memory efficiency. But the option value is lower. Future changes require rewriting, not swapping. Future scaling requires scaling everything, not the bottleneck.
Technical decisions that preserve future options depreciate slower than decisions that foreclose them.
This isn't because flexible decisions are inherently better. It's because flexibility is a hedge against the uncertainty of which depreciation model will apply. If you don't know whether your framework decision will face straight-line depreciation (gradual obsolescence) or sudden write-off (vendor abandons the project), the decision that costs a little more upfront but preserves your ability to respond is the one with lower expected lifetime cost.
The option pricing model from finance gives us a vocabulary for this: the more volatile the technology ecosystem (the more uncertain the future), the more valuable the option component of a decision becomes. In a stable ecosystem, optimizing for immediate value makes sense — the future is predictable. In a volatile ecosystem, optimizing for option value makes sense — the future is not.
This is why experienced architects instinctively reach for abstractions at integration boundaries. They're not over-engineering. They're purchasing options. The anti-corruption layer between your code and a vendor API isn't just a structural pattern — it's a call option on vendor independence. Its value increases precisely when vendor lock-in risk increases.
The service bus library we couldn't let go
There's a reason dead decisions linger far past their expiration dates, and it's not laziness or ignorance. It's a well-documented cognitive bias that economists have studied for decades: the sunk cost fallacy.
Daniel Kahneman and Amos Tversky's prospect theory (1979) demonstrated that humans weight losses roughly twice as heavily as equivalent gains. Abandoning a technical decision feels like a loss — the investment in code, in team expertise, in operational knowledge, in documentation — even when the rational calculation clearly favors replacement.
I've watched this play out in a pattern so consistent I could set a clock by it.
Year 1-2: The team chooses a technology. Enthusiasm is high. Investment accelerates. Code, tooling, and expertise accumulate.
Year 3-4: Signs of decay appear. The technology falls behind alternatives. Stack Overflow activity declines. Conference talks shift to newer approaches. Core team members start mentioning alternatives in architecture discussions.
Year 4-5: A formal proposal to migrate emerges. It's debated extensively. The primary counterargument is always the same: "We've invested too much to switch now." This argument is textbook sunk cost reasoning — the investment is gone regardless of what you decide. But it wins the debate roughly 60-70% of the time in my observation.
Year 5-7: The decision becomes untenable. Migration begins, but now under pressure — the old technology is no longer receiving security patches, or key team members have left, or a compliance requirement forces the move. The migration costs 3-5x what it would have cost in year 3.
The economic literature calls this "escalation of commitment." In software engineering, it looks like this: a team spending more time maintaining workarounds for an aging library than the migration would have cost two years ago. It's the drawer full of adapters for phones you no longer own — you keep them because throwing them away feels like admitting the money was wasted, even though keeping them wastes something worse: space you could use for something that works.
I watched this exact pattern play out in the claims processing platform between 2020 and 2022. The team had built significant expertise around a particular service bus library. When a newer alternative emerged that solved several pain points — better saga support, cleaner configuration, native outbox integration — the migration proposal was estimated at 6 weeks. The counterargument: "We've spent two years learning this library's quirks and building tooling around it." The proposal was deferred.
Twelve months later, the same migration was estimated at 12 weeks. The library had fallen further behind. The tooling had grown more complex to compensate. But the sunk cost argument was now stronger: "We've spent three years. And the custom tooling we built is now critical infrastructure."
Another twelve months. The estimate was 5 months. A security vulnerability in the library's transport layer forced an emergency patch that the maintainer took 8 weeks to release. The team spent those 8 weeks on a workaround that added 2,000 lines of code that would be thrown away in any migration. By now, the sunk cost was enormous — and the team was spending more time maintaining the workarounds than the migration would have cost in year one.
The depreciation framework makes the rational choice visible: if a decision has crossed its half-life and the depreciation curve is declining-balance or accelerated, the residual value is dropping faster than the switching cost is rising. Every month you delay, the economics get worse. But the sunk cost weighs on the decision like gravity, and gravity is patient.
Four ways to build for expiration
If technical decisions are depreciating assets — and the evidence says they are — then our approach to architecture needs to change in four specific ways.
Build a depreciation schedule
For every significant technical decision, estimate its useful life using the half-life model. Record the decision, its estimated half-life, and its depreciation type in an architecture decision record. Revisit the schedule annually, just as a financial team reviews its asset depreciation schedules.
This sounds bureaucratic. It isn't. It takes five minutes per decision and saves months of escalation-of-commitment delay. When the team debates whether to migrate off a framework, having a record that says "estimated useful life: 4 years; current age: 3.5 years; depreciation model: declining-balance" transforms an emotional argument into a data-informed conversation.
Match investment to half-life
Don't invest the same level of architectural effort in decisions with wildly different half-lives. A configuration decision with a 6-month half-life doesn't deserve a three-week design spike. A protocol decision with a 20-year half-life does.
This principle should guide abstraction decisions. You should write abstraction layers around short-half-life decisions (vendor APIs, specific libraries) because the return on that investment accrues within months — the abstraction will be exercised when the underlying decision expires. You should not write abstraction layers around long-half-life decisions (HTTP, SQL, TCP) because the abstraction overhead accumulates for decades before it's exercised, if ever.
The mismatch I see most often: teams that write elaborate abstraction layers around SQL (long half-life, low depreciation risk) while hardcoding vendor-specific cloud service calls throughout their codebase (short half-life, high depreciation risk). They've invested their option-value budget exactly backwards.
Set replacement triggers, not replacement dates
Don't schedule a migration for 2028. Instead, define the conditions under which migration becomes economically rational. "When the framework's last security patch is more than 6 months old." "When fewer than 3 core contributors have committed in the past quarter." "When our IDE's language support drops below version parity with current releases."
Trigger-based replacement acknowledges that you don't know which depreciation model will apply. Straight-line depreciation is plannable. Sudden obsolescence is not. Triggers catch both.
I've found it helpful to define three trigger levels for each significant decision:
Amber: The decision is approaching its estimated half-life, or early depreciation signals are visible. Action: begin evaluating alternatives, allocate one engineer for a migration spike. Cost at this stage is typically 1-2 weeks of exploration.
Red: The decision has passed its half-life and multiple depreciation signals are active. Action: initiate formal migration planning, estimate costs, present to leadership. Cost at this stage is typically 2-4 months of focused work.
Critical: The decision is untenable — security vulnerabilities unpatched, community abandoned, vendor support ended. Action: emergency migration with all associated costs of unplanned work. Cost at this stage is typically 2-3x what it would have been at amber, plus the opportunity cost of emergency context-switching.
The purpose of the trigger system is simple: it converts "we should probably migrate someday" — which in practice means "we'll migrate when forced to" — into "we migrate when condition X is met." The former leads to critical-stage migrations every time. The latter catches most migrations at amber, where the costs are manageable and the team has time to make good choices instead of panicked ones.
In the three systems I've tracked, decisions that had defined replacement triggers cost an average of 40% less to migrate than decisions that were replaced reactively. The sample is small and the comparison is imperfect. But the direction is clear: planned depreciation beats unplanned depreciation, every time.
Account for option value in architectural reviews
When evaluating two architectural approaches, don't just compare immediate costs and benefits. Compare option values. Which approach preserves more future flexibility? Which one forecloses fewer future decisions?
In practice, this means asking: "If we're wrong about our assumptions, how expensive is it to change course?" The approach with the lower course-correction cost has higher option value, even if its immediate cost is slightly higher. A microservice boundary that's well-defined is more expensive to build than a tightly-coupled module, but its option value — the ability to replace, scale, or rewrite that service independently — is substantially higher.
The option value lens doesn't always favor flexibility. Sometimes the right call is to optimize for the present and accept the reduced optionality. A startup with 12 months of runway should not spend 3 months building abstraction layers against vendor lock-in. The option value of flexibility is real, but it's worth less than the option value of having a working product before the money runs out. Context determines which options are worth purchasing.
But it should be a conscious trade-off, not an accidental one. And it should be recorded as such, with the acknowledged depreciation risk. The decision record should state: "We chose vendor-specific integration to ship faster. Estimated half-life: 2 years. Depreciation model: declining-balance. Replacement trigger: vendor price increase > 30% or service downtime > 4 hours/month." That's an informed bet. The alternative — choosing vendor lock-in without acknowledging the depreciation schedule — is a bet you don't know you're making.
The ledger's blind spots
The depreciation model illuminates a great deal. But it also has edges where the analogy frays.
Network effects distort half-lives. Some technologies persist far beyond their depreciation curves because of network effects — the value of the decision increases with the number of other people who made the same decision. PHP has outlasted dozens of technically superior alternatives because WordPress creates a network effect that sustains it. The depreciation model assumes independent decay, but network effects create a gravitational pull that slows decay for popular choices and accelerates it for niche ones. The decision to use PHP in 2010 was objectively worse than the decision to use a more modern alternative on pure technical merit, but it may have been better on depreciation-adjusted merit because the network effect extended its useful life by 5-10 years.
Organizational learning resets the clock. When a team deeply understands a technology — its internals, its failure modes, its optimization strategies — the practical half-life extends because the team can compensate for ecosystem decay with deep expertise. A team of Cobol experts can extract useful life from Cobol decisions that would be untenable for a team that learned it last year. I've seen this in practice: a team at the claims processing platform maintained a legacy WCF service for two years past what any reasonable depreciation schedule would have recommended — and did so cost-effectively, because their deep understanding of WCF's edge cases meant the maintenance burden was lower than the migration cost. The depreciation model measures the technology's decay, but the team's accumulated expertise is a separate asset that doesn't depreciate on the same schedule. When those experts leave, the effective half-life of the decision collapses overnight.
Regulatory constraints freeze decisions. In regulated industries — healthcare, finance, aerospace — technology decisions are sometimes frozen by compliance requirements. A banking system can't migrate off a validated technology stack until the replacement has been through a certification process that may take years. The technology has depreciated past its economic useful life, but the regulatory constraint acts as an artificial support, preventing the write-off. This creates a dangerous dynamic: the technology is nominally alive but functionally dead, and the team operates under the illusion of stability while the accumulated decay builds toward an eventual forced migration at maximum cost.
Before the code grows, before it breaks, before it corrodes — someone made a decision. And that decision started depreciating the moment it was made.
Not all decisions decay at the same rate. Configuration choices last months. Library choices last a couple of years. Framework choices last several. Language choices last a decade. Protocol choices last a generation. Each layer has its own curve, its own half-life, its own optimal moment to let go.
The most important decisions in a system are not the ones you got right. They're the ones you structured so that being wrong is cheap to correct. Not "is this the right technology?" but "if this turns out to be wrong, how much does it cost to change?"
Good architecture isn't about making decisions that last. It's about making decisions that know how to die.