
The Order That Got Stuck Between Three Services
One order. Three services. A distributed deadlock nobody saw coming — and the pattern that prevents it.

The order was stuck for eleven hours before anyone noticed.
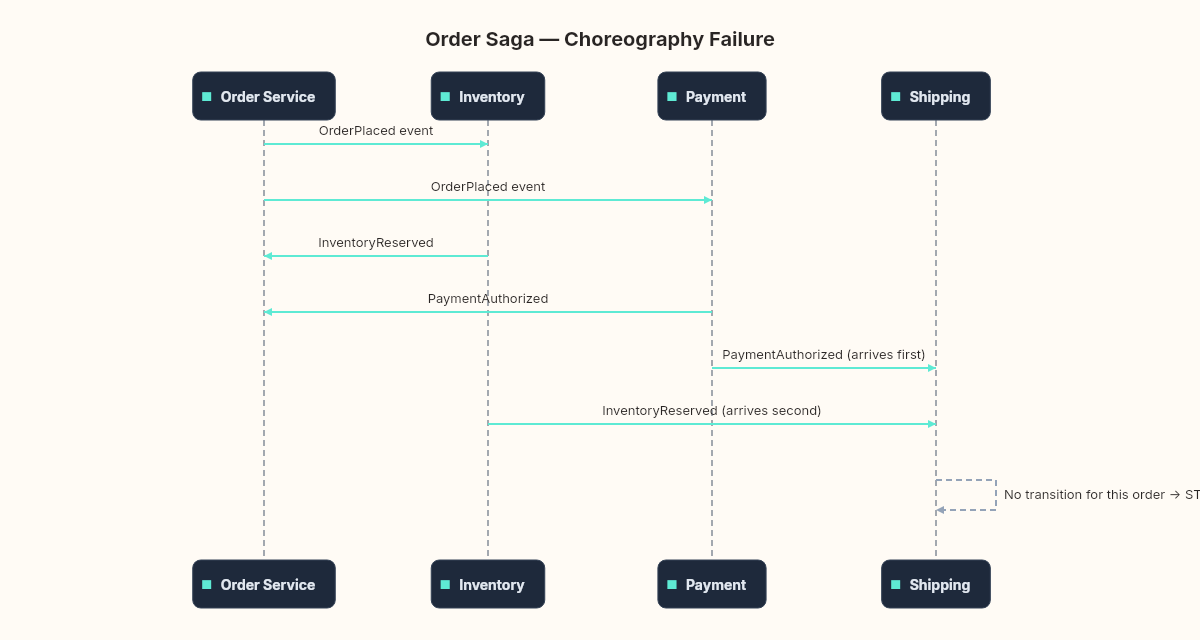
Not failed. Not rejected. Stuck. Inventory had reserved two units. Payment had authorized the charge. Shipping was waiting for both to confirm. But the confirmation messages had arrived in the wrong order, and the shipping service's state machine didn't have a transition for "payment confirmed before inventory confirmed."
So it sat there. In a state that wasn't success, wasn't failure, wasn't timeout. A state the original developer hadn't imagined, because they'd tested each service in isolation and the sequences had always worked.
I found it on a Tuesday morning, buried in a dashboard that nobody checked because the system "had monitoring." The order belonged to a customer who'd already called support twice.
Earlier in the series we explored the outbox pattern across several chapters — making sure a message reliably leaves your service. That's a solved problem now. But here's the question the outbox doesn't answer: what happens when the message arrives, and the thing it triggers needs to coordinate with two other services, and all three need to agree on whether the operation succeeded or failed?
That's the next pattern. The saga.
What goes wrong without it
Let me describe the architecture that produced the stuck order, because you've probably seen something like it.
Three services. Order, Payment, Inventory. A customer clicks "Place Order" and the Order service needs to:
Reserve inventory (Inventory service)
Charge the card (Payment service)
Confirm the order (back to Order service)
The naive approach: the Order service publishes an OrderPlaced event. Both Payment and Inventory subscribe. Each does its work and publishes a confirmation event. The Order service listens for both confirmations and, when both arrive, marks the order as complete.
This is choreography. No central coordinator. Each service reacts to events and publishes its own events. It looks elegant on a whiteboard.
Here's what goes wrong.
Partial failure. Payment succeeds, but Inventory discovers the item is out of stock. The money is charged. The item can't ship. Who undoes the payment? The Inventory service doesn't know about payments. The Order service hasn't received a failure event yet — it's still waiting for a confirmation that will never come.
Ordering ambiguity. Payment confirms before Inventory does. Or Inventory confirms before Payment does. Or both confirm at exactly the same time. The Order service needs to handle all of these sequences. With three steps, there are six possible orderings. With five steps, there are 120.
Timeout uncertainty. How long should the Order service wait? Thirty seconds? Five minutes? What if Payment is slow because the card issuer is doing fraud detection? A short timeout causes false failures. A long timeout causes stuck orders.
Observability gaps. Each service logs its own perspective. Payment logs "charge authorized." Inventory logs "stock reserved." But nobody logs the overall business operation — the order as a unified thing. When something goes wrong, you're reconstructing a timeline from three separate log streams, hoping the timestamps are synchronized.
The partial failure in slow motion. Let me walk through a specific scenario, step by step, because the devil lives in the sequence.
A customer orders a laptop. The Order service publishes OrderPlaced. Payment and Inventory both receive it.
Payment charges the card. The customer's bank authorizes $1,200. The money is now held — it's real, it's committed, the customer can see the pending charge on their bank app. Payment publishes PaymentAuthorized.
Inventory checks stock. The warehouse had two laptops left, but between the time the customer clicked "Buy" and now — maybe three seconds — another order claimed the last two. Stock is zero. Inventory publishes InventoryInsufficient.
Now the system is in a state that nobody designed for. $1,200 is charged. No laptop exists to ship. The Order service receives PaymentAuthorized and InventoryInsufficient, and it knows the order can't be fulfilled. But what can it do? It can mark the order as failed. It can notify the customer. What it can't do is refund the payment, because the Order service has no access to the payment provider's API. It doesn't even know the transaction ID.
The Order service could publish a RefundRequested event. But who handles it? The Payment service, presumably. Did anyone build that handler? Is the Payment service subscribed to RefundRequested? If it is, does it know how to correlate the refund back to the original charge? What if the refund fails — who retries it?
Each of these questions requires a new event, a new handler, a new subscription. And every one of them introduces another failure point. The refund message could get lost. The Payment service could be down when the refund event arrives. The queue could be backed up and the refund takes hours while the customer is staring at a $1,200 charge and an empty order page.
This is what "partial failure" means in distributed systems. It's not a crash. It's not an error code. It's a state where some participants succeeded and others didn't, and there's no automatic mechanism to bring them back into agreement. The customer has paid for a laptop that doesn't exist, and the only thing holding the system together is the hope that all the compensating events will eventually find their way to the right handlers in the right order.
Without a saga, this hope is your architecture.
The stuck order I found was a combination of the first three. A race condition in event ordering created a state the system couldn't recover from. And nobody noticed because the fourth problem — observability — meant the system looked healthy from every individual service's perspective.
The theatre connection
There's a reason the two approaches to this problem are called orchestration and choreography. The terms come from performance art, and the distinction is more precise than most engineers realize.
In ballet, choreography means the dancers have memorized the entire piece. Each performer knows exactly when to move, where to stand, what comes next. There's no conductor calling out instructions in real time. The coordination is encoded in the performers themselves. If a dancer misses a cue, the others adjust instinctively — or the performance breaks.
Orchestration is the opposite. A conductor stands at the front with a score. The musicians watch the conductor, not each other. The conductor decides tempo, dynamics, entrances. If a musician loses their place, the conductor can bring them back. The coordination lives in one place: the podium.
Software borrowed these terms, but most teams use them loosely. "We're doing choreography" usually means "services publish events and hope for the best." "We're doing orchestration" usually means "one service calls the others in sequence."
The theatre analogy makes the trade-off precise.
Choreography requires every participant to know the entire protocol. Every service must understand what events to expect, in what order, and what to do when the unexpected happens. The coordination logic is distributed across all participants. This works beautifully when the protocol is simple and stable — two services, one exchange, well-defined outcomes. It falls apart when the protocol is complex or changes frequently, because updating the choreography means updating every dancer.
Choreography distributes the coordination logic. Orchestration centralizes it. The choice isn't about elegance — it's about where you want the complexity to live when things go wrong.
Orchestration concentrates the protocol in one place. A saga orchestrator knows the full sequence: step one, step two, step three, and what to undo if step three fails. The participating services don't need to understand the overall flow. They just execute commands and report results. This makes the protocol visible, testable, and changeable in one place. The cost is a single point of coordination — the orchestrator itself becomes critical infrastructure.
Neither approach is inherently better. The question is: how many participants, how complex is the failure recovery, and how often does the protocol change?
The saga pattern, from first principles
The term "saga" comes from a 1987 paper by Hector Garcia-Molina and Kenneth Salem at Princeton. They weren't thinking about microservices — they were thinking about long-lived database transactions.
The problem: a transaction that takes minutes or hours (batch processing, multi-step workflows) holds locks for the entire duration. Nothing else can touch that data. Garcia-Molina and Salem proposed breaking the long transaction into a sequence of smaller transactions, each with a compensating transaction that undoes its work if a later step fails.
That's still the core idea, forty years later.
A saga is a sequence of steps where:
Each step is a local transaction in one service
Each step has a compensating action that reverses it
If any step fails, the compensating actions for all completed steps run in reverse order
OrderSaga:
Step 1: ReserveInventory → Compensate: ReleaseInventory
Step 2: ChargePayment → Compensate: RefundPayment
Step 3: ConfirmOrder → Compensate: CancelOrder
If Step 2 fails:
Run Compensate for Step 1 → ReleaseInventory
(Step 2 never completed, so no compensation needed)
Order ends in FAILED stateThis is fundamentally different from a distributed transaction. A distributed transaction (two-phase commit) tries to make all steps succeed or all steps fail atomically — as if they were one transaction. A saga accepts that intermediate states are visible. Between Step 1 completing and Step 2 completing, the inventory is reserved but payment hasn't been charged. That intermediate state is real. Other parts of the system might see it.
This is the trade-off that trips people up. Sagas give you eventual consistency and failure recovery, but they don't give you isolation. The "I" in ACID disappears. And that has consequences we'll explore in the chapter on edge cases.
What the orchestrator actually looks like
In the orchestrated version, a central component manages the saga's lifecycle. Think of it as a state machine.
public enum OrderSagaState
{
NotStarted,
InventoryReserved,
PaymentCharged,
Completed,
Compensating,
Failed
}
public class OrderSaga
{
public Guid OrderId { get; set; }
public Guid CorrelationId { get; set; }
public OrderSagaState State { get; set; }
public DateTime StartedAt { get; set; }
public DateTime? CompletedAt { get; set; }
public string? FailureReason { get; set; }
}The orchestrator receives the initial command — CreateOrder — and walks through the steps:
// Simplified orchestration logic
public async Task Handle(CreateOrder command)
{
var saga = new OrderSaga
{
OrderId = command.OrderId,
CorrelationId = Guid.NewGuid(),
State = OrderSagaState.NotStarted,
StartedAt = DateTime.UtcNow
};
// Step 1: Reserve inventory
await _bus.Send(new ReserveInventory(saga.CorrelationId, command.Items));
saga.State = OrderSagaState.InventoryReserved;
await _repository.Save(saga);
}
public async Task Handle(InventoryReserved @event)
{
var saga = await _repository.Load(@event.CorrelationId);
// Step 2: Charge payment
await _bus.Send(new ChargePayment(saga.CorrelationId, saga.OrderId));
saga.State = OrderSagaState.PaymentCharged;
await _repository.Save(saga);
}
public async Task Handle(PaymentFailed @event)
{
var saga = await _repository.Load(@event.CorrelationId);
// Compensation: release the inventory we reserved
saga.State = OrderSagaState.Compensating;
saga.FailureReason = @event.Reason;
await _bus.Send(new ReleaseInventory(saga.CorrelationId));
await _repository.Save(saga);
}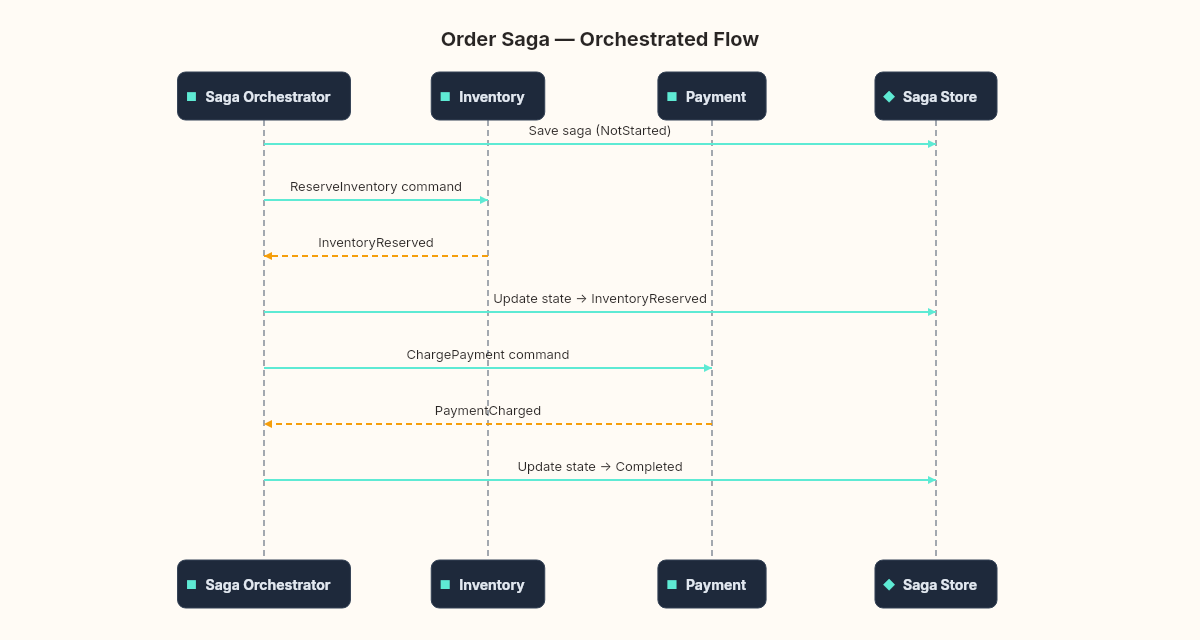
The critical detail: the saga's state is persisted after every transition. If the orchestrator crashes between sending ReserveInventory and receiving InventoryReserved, it can recover by reloading the saga from the database and checking what state it's in. This is where the outbox pattern from earlier in the series connects — the orchestrator uses the outbox to ensure that state changes and message sends are atomic.
The CorrelationId threads through every message. It's the identifier that ties all the pieces together across service boundaries. Without it, you can't reconstruct which inventory reservation belongs to which payment charge belongs to which order.
Why the stuck order happened
Back to that eleven-hour stuck order.
The system was using choreography. No central orchestrator. Each service reacted to events and published its own. The problem was the Order service's state machine. It expected events to arrive in a specific sequence: InventoryReserved first, then PaymentAuthorized. When payment confirmation arrived first — which happened under load because the payment provider's response time was faster than the inventory check — the Order service received an event it didn't have a handler for in its current state.
It didn't crash. It didn't log an error. It just ignored the message, because the message handler checked the current state and found no valid transition. The message was acknowledged and discarded. When InventoryReserved arrived a moment later, the Order service transitioned to AwaitingPayment — but the payment confirmation was already gone.
Stuck.
An orchestrator would have prevented this by design. The orchestrator controls the sequence. It sends one command at a time (or sends them in parallel and waits for all responses). The participating services don't need to know the protocol. They receive a command, do their work, and report the result. The ordering problem disappears because the orchestrator manages the ordering.
The choreography approach can handle this too — but the Order service's state machine needs explicit transitions for every possible event ordering. With three steps, that's manageable. With five or six steps, you're maintaining a state machine with dozens of transitions, and the probability of missing one increases with every new step.
The question for the coming chapters
This is the pattern we're building and breaking over the coming chapters.
First, we'll implement a full saga orchestrator in .NET — state machine, compensation logic, persistence, and the connection to the outbox we built earlier. Then we'll break it: compensation failures, timeouts, partial rollbacks, and the edge cases that tutorials skip. After that, we throw a thousand concurrent orders at it with a dying payment service. Finally, the verdict: orchestration versus choreography, and when each one earns its complexity.
But before any of that, here's the question I want you to sit with.
Think about the most complex business operation in your system. The one that touches more than two services. Trace the happy path. Now trace the failure paths. How many are there? Who is responsible for deciding that the operation failed? Who triggers the undo? Is there a single place you can look to see the current state of that operation, or do you have to query three services and reconstruct it?
If the answer to that last question is "reconstruct it" — you're running a choreography, whether you designed one or not. And the question isn't whether you'll get a stuck order. It's how long before someone notices.