
The Saga Verdict — Orchestration, Choreography, and Choosing Your Own Complexity
After a week of building, breaking, and measuring sagas, the question isn't which approach wins. It's which trade-offs you can live with.

In 1787, the delegates at the Philadelphia Convention spent four months arguing about a question that still has no clean answer: should power be centralized in a strong federal government, or distributed across independent states?
Hamilton wanted a single authority. Clear chain of command. One place where decisions get made and enforced. Madison pushed for distributed sovereignty — independent states that coordinate through shared protocols, each retaining the power to act on their own.
They compromised. But the tension between centralized control and distributed autonomy has never been resolved. It just keeps reappearing in different domains: monetary policy, military command structures, corporate governance. And — as we discovered across these chapters — distributed system coordination.
As we measured in the stress-test chapter, throwing a thousand concurrent orders at an orchestrator while killing services underneath it yielded a 94.2% success rate under hostile conditions. Now we step back and ask the question this entire pattern exploration has been building toward: when should you orchestrate, when should you choreograph, and when should you reach for a framework instead of building it yourself?
What we built, and what it cost us
The orchestrator we built in the blueprint chapter works. It handles the happy path, manages compensation on failure, persists state across restarts, and survived the stress test with a 94.2% success rate under hostile conditions. That's not nothing.
But building it cost us four chapters and roughly 600 lines of infrastructure code. State machine, compensation registry, timeout handling, idempotency checks, persistence layer. Every one of those pieces exists because the orchestrator pattern demands explicit coordination — someone has to be in charge, and that someone has to track everything.
The equivalent choreography approach would look different. No central coordinator. Each service listens for events and reacts independently. The order service publishes OrderCreated. The inventory service hears it, reserves stock, publishes StockReserved. The payment service hears that, charges the card, publishes PaymentConfirmed. No single service knows the full workflow. No single service is responsible for compensating failures across the chain.
The political parallel holds. Hamilton's federalism gives you visibility and control. Madison's distribution gives you autonomy and resilience. Both work. Both have failure modes the other doesn't.

Orchestration: the case for a strong center
The orchestrator knows the entire workflow. It holds the state machine, decides what happens next, and — critically — knows what to undo when something goes wrong.
Where it shines:
Complex compensation logic. When undoing step 3 depends on what happened in step 2, a choreographed system has to reconstruct that context from events. The orchestrator already has it. The edge cases we cataloged in the failure modes chapter — the payment that succeeded but the confirmation that timed out — are dramatically easier to handle when one component holds the full picture.
Observability. The stress test dashboard worked because the orchestrator tracked every saga's state transitions. In a choreographed system, building that same view requires correlating events across multiple services, each with its own log, its own clock, its own definition of "done."
Explicit ordering. If your business process has steps that must happen in sequence — reserve inventory before charging the card — an orchestrator enforces that by construction. Choreography can enforce it through event contracts, but the ordering is implicit and distributed across consumer configurations.
The orchestrator trades autonomy for clarity. You can read the workflow in one file. The cost is that one file becomes the system's single point of knowledge.
Where it hurts:
The orchestrator is a coordination bottleneck. Not necessarily a performance bottleneck — The stress test showed it handles 1,000 concurrent sagas without breaking — but an organizational bottleneck. Every workflow change requires modifying the orchestrator. Every new step, every new compensation path, every new timeout configuration. The team that owns the orchestrator becomes the team that owns the process.
At a transportation operations system, I watched this happen with a booking orchestration service. Three teams needed to change how seat assignments worked. All three changes required orchestrator modifications. The queue of pull requests against that single service became the queue of business features that couldn't ship.
Choreography: the case for federation
In the choreographed version, no service knows the full workflow. Each service knows only its own responsibilities and the events it cares about.
Where it shines:
Team autonomy. The inventory team can change how stock reservation works without touching any other service. They consume the same event, they publish the same event, and everything in between is their business. At a regulated industry platform, we ran event-driven claims processing this way. The underwriting team, the payments team, and the notifications team each evolved independently for months. No coordination meetings about shared orchestrators. No merge conflicts on a central workflow file.
Resilience to partial failure. If the notification service goes down in a choreographed system, the payment and inventory services keep working. They don't know the notification service exists. In an orchestrated system, a failing step stalls the entire saga until the timeout fires.
Scalability. Each service scales independently based on its own load patterns. The payment service might need 10 instances during a flash sale while the inventory service needs 2. No central coordinator needs to be sized for the aggregate load.
Where it hurts:
Implicit workflows. The business process — reserve stock, charge card, send confirmation — doesn't exist in any single place. It's distributed across event subscriptions in three different services. Understanding the full flow requires reading three codebases and tracing event chains. When a stakeholder asks "what happens when we get an order?", nobody can point to one file and say "this."
Compensation is brutal. The edge cases we explored — the payment that charged but the confirmation that never arrived — become much harder without a central coordinator. The payment service published PaymentConfirmed. Who's responsible for rolling it back? Does the inventory service know that the confirmation service failed? Should the payment service listen for a SagaTimedOut event and compensate itself? The answer is always "it depends," and the dependency chains get tangled fast.
Choreography trades visibility for independence. Each service is simpler. The system is harder to reason about.
The decision framework
After building both approaches across these chapters, running edge cases through them, and stress-testing the orchestrated version, I've landed on a framework that's less about "which is better" and more about which properties your system needs.
The first question is whether you need a saga at all. Count the services involved in your business transaction. If it's two — say, an order service and a payment service — a direct API call with a compensating action on failure is simpler than either pattern. The saga overhead (state persistence, compensation registry, timeout management) earns its keep at three or more independently deployed services.
Choose orchestration when:
Compensation logic is complex or order-dependent
The business process has strict step sequencing
You need a single source of truth for saga state (auditing, compliance)
One team owns the end-to-end workflow
The workflow changes frequently and needs to be readable
The sweet spot I've seen is 3-7 saga steps owned by a single team. Below three, a saga is overhead. Above seven, the state machine becomes its own maintenance burden — at that point, consider splitting into sub-sagas.
Choose choreography when:
Services are owned by different teams with different release cycles
The business process is naturally event-driven (notifications, analytics, logging)
Partial failure should not block unrelated services
The compensation for each step is self-contained (each service can undo its own work)
You need maximum deployment independence
Choreography scales better organizationally when you pass about four independent teams. The coordination cost of a shared orchestrator starts exceeding the cognitive cost of distributed event flows somewhere around that boundary. Below four teams, the orchestrator is cheaper. Above four, the PR queue on that single service becomes a governance problem.
Consider a hybrid when:
The core business flow is orchestrated (order → payment → fulfillment), but side effects are choreographed (notifications, analytics, audit logging)
Most of the time, this is the right answer. The real world rarely fits cleanly into one model
The hybrid is worth showing in code, because the pattern isn't obvious until you see it:
// The orchestrator handles the critical path
During(AwaitingPayment,
When(PaymentCompleted)
.Then(ctx => ctx.Saga.PaymentConfirmedAt = DateTime.UtcNow)
.TransitionTo(AwaitingFulfillment)
.Publish(ctx => new FulfillOrder(ctx.Saga.OrderId))
// Side effects published as events — not orchestrated
.Publish(ctx => new OrderPaid
{
OrderId = ctx.Saga.OrderId,
Amount = ctx.Saga.TotalAmount,
PaidAt = ctx.Saga.PaymentConfirmedAt
}));
// Notification, analytics, and audit services
// subscribe to OrderPaid independently.
// The orchestrator doesn't know they exist.
// They don't know the orchestrator exists.The orchestrator owns the happy path and the compensation path. The OrderPaid event fans out to whoever cares — notification service, analytics pipeline, audit log — and none of those consumers participate in the saga. If the notification service crashes, the order still completes. If the analytics pipeline falls behind, the payment still processes. The orchestrator doesn't wait for side effects, and the side effects don't need compensating actions in the saga.
The hybrid works because it asks the right question for each step: "Does failure here require compensating previous steps?" If yes, orchestrate it. If no, publish an event and let consumers handle themselves.
The toolbox: MassTransit, NServiceBus, Wolverine
Building a saga orchestrator from scratch was instructive. I would not do it in production.
The infrastructure we built across these chapters — state persistence, timeout management, compensation registry, idempotency, retry policies — is exactly what saga libraries handle for you. The question is which library fits your context. Same question the sommelier asks when choosing between vintages, just different bottles.
MassTransit (open source, MIT license)
MassTransit's saga state machines use Automatonymous — a fluent DSL for defining state transitions.
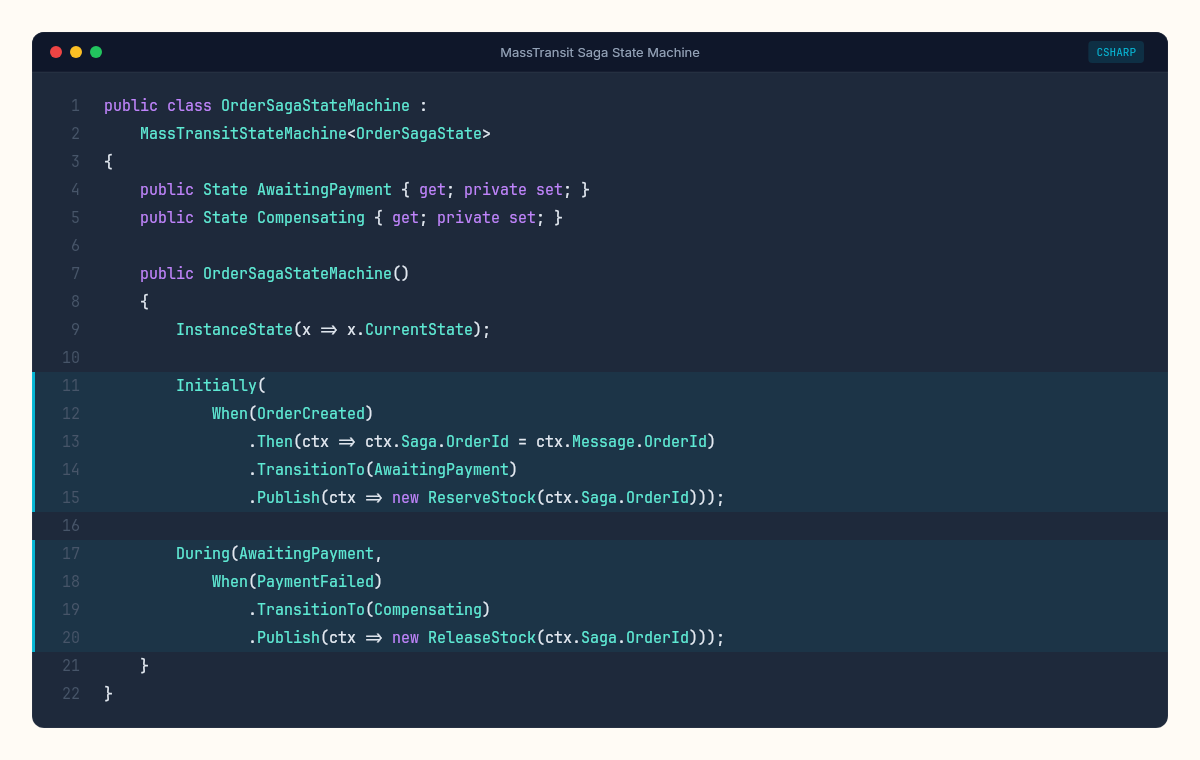
public class OrderSagaStateMachine :
MassTransitStateMachine<OrderSagaState>
{
public State AwaitingPayment { get; private set; }
public State AwaitingConfirmation { get; private set; }
public State Compensating { get; private set; }
public Event<OrderCreated> OrderCreated { get; private set; }
public Event<PaymentCompleted> PaymentCompleted { get; private set; }
public Event<PaymentFailed> PaymentFailed { get; private set; }
public OrderSagaStateMachine()
{
InstanceState(x => x.CurrentState);
Event(() => OrderCreated, x => x.CorrelateById(
ctx => ctx.Message.OrderId));
Initially(
When(OrderCreated)
.Then(ctx => ctx.Saga.OrderId = ctx.Message.OrderId)
.TransitionTo(AwaitingPayment)
.Publish(ctx => new ReserveStock(ctx.Saga.OrderId)));
During(AwaitingPayment,
When(PaymentCompleted)
.TransitionTo(AwaitingConfirmation)
.Publish(ctx => new SendConfirmation(ctx.Saga.OrderId)),
When(PaymentFailed)
.TransitionTo(Compensating)
.Publish(ctx => new ReleaseStock(ctx.Saga.OrderId)));
}
}The state machine is declarative. You can read the workflow. State persistence supports EF Core, MongoDB, Redis, and Azure Table Storage. Timeout scheduling uses Quartz.NET or Hangfire. The library handles idempotency, concurrent message delivery, and saga completion automatically.
Cost: MassTransit has a learning curve. The Automatonymous DSL is powerful but not obvious. First-time setup with EF Core persistence took me about two hours including the migration. The documentation assumes you already understand messaging patterns — if you don't, you'll be reading the source.
NServiceBus (commercial, Particular Software)
NServiceBus sagas use a handler-based model — closer to what we built across these chapters.
public class OrderSaga : Saga<OrderSagaData>,
IAmStartedByMessages<OrderCreated>,
IHandleMessages<PaymentCompleted>,
IHandleMessages<PaymentFailed>,
IHandleTimeouts<PaymentTimeout>
{
public async Task Handle(OrderCreated message,
IMessageHandlerContext context)
{
Data.OrderId = message.OrderId;
await context.Send(new ProcessPayment(message.OrderId));
await RequestTimeout<PaymentTimeout>(context,
TimeSpan.FromSeconds(30));
}
public async Task Handle(PaymentFailed message,
IMessageHandlerContext context)
{
await context.Send(new ReleaseStock(Data.OrderId));
MarkAsComplete();
}
}Explicit handlers instead of a state machine DSL. The timeout mechanism is built in. Saga persistence supports SQL Server, RavenDB, CosmosDB, MongoDB, and Azure Table Storage. NServiceBus also provides recoverability — failed messages go to error queues with full context for manual or automated retry.
Cost: NServiceBus is commercial software. The license is per-endpoint, and for teams with many services, the cost adds up. The trade-off: you get Particular's ServicePulse monitoring dashboard, which gives you the observability we built manually in the stress test — out of the box.
Wolverine (open source, JasperFx)
Wolverine is the newest contender. Built by Jeremy Miller (who also built Marten for event sourcing), it takes a code-first approach.
public class OrderSagaHandler
{
public async Task<(ReserveStock, ScheduleTimeout)> Handle(
OrderCreated created, OrderSagaState state)
{
state.OrderId = created.OrderId;
return (
new ReserveStock(created.OrderId),
new ScheduleTimeout(TimeSpan.FromSeconds(30)));
}
public async Task<ReleaseStock> Handle(
PaymentFailed failed, OrderSagaState state)
{
return new ReleaseStock(state.OrderId);
}
}Wolverine infers the saga workflow from method signatures — the return type determines what messages get published. Less ceremony than MassTransit, less explicit than NServiceBus. State persistence uses Marten (PostgreSQL) or EF Core.
Cost: Wolverine is young. The community is smaller. The documentation is growing but has gaps. If you hit an edge case the library doesn't handle, you're reading source code. That said, the integration with Marten makes it the natural choice if you're already using PostgreSQL and event sourcing.
The honest comparison

A few numbers to ground the comparison. MassTransit has been in active development since 2007, with over 5,800 GitHub stars and a NuGet download count in the tens of millions. NServiceBus has been around even longer (2006), with Particular Software providing commercial support, training, and the ServicePulse monitoring suite. Wolverine is the youngest — first stable release in 2023 — but it's built on Jeremy Miller's decade of open-source experience with Jasper and Marten.

What matters most depends on what you're building, who's building it, and how long you plan to maintain it.
If your team already uses RabbitMQ or Azure Service Bus and wants a mature, well-documented saga implementation with full state machine support, MassTransit is the default recommendation. It's battle-tested, actively maintained, and the community is large enough that most problems have been solved in a GitHub issue somewhere.
If you're in an enterprise context where observability, support contracts, and compliance matter more than license cost, NServiceBus offers the most complete package. ServicePulse alone justifies the cost for teams that are serious about production monitoring.
If you're building on PostgreSQL with Marten and want the leanest possible code, Wolverine is worth evaluating. It's opinionated in useful ways, and Jeremy Miller's track record with open-source .NET libraries is strong.
If your saga is simple — three steps, minimal compensation, rarely changes — you might not need any of these. A hand-rolled state machine with an outbox (like what we built for the outbox pattern) can be the right answer when the complexity budget doesn't justify a framework dependency.
Two weeks of patterns, one uncomfortable truth
We've spent the first stretch of this series building messaging guarantees. The first pattern was the outbox — making sure messages leave the database reliably. The second was the saga — coordinating multi-service operations when any step can fail.
The uncomfortable truth is that most systems don't need either pattern. Most systems run fine with synchronous HTTP calls and a single database. The outbox matters when message loss costs real money. The saga matters when a business process genuinely spans multiple services that can't share a transaction.
The danger isn't in using these patterns. The danger is in reaching for them before the pain justifies the complexity. A saga orchestrator adds 600 lines of infrastructure and a persistent state machine to your system. A choreographed event chain adds implicit coupling across every service that participates. Both are real costs, paid by the team that maintains the system at 2 AM when something goes wrong.
The question I ask before introducing either pattern: can I solve this with a database transaction and a background job? If the answer is yes, I stop there. If the answer is genuinely no — because the services are independently deployed, independently scaled, and owned by different teams — then the patterns earn their keep.
I've seen teams introduce sagas for workflows that crossed exactly two services. The overhead of the state machine, the compensation registry, and the saga persistence layer exceeded the complexity of the business logic they were coordinating. A simpler pattern — service A calls service B, and if B fails, A reverts — would have taken an afternoon instead of a sprint.
The inverse is also dangerous. I've worked on systems where five services shared a single database transaction through distributed locks and two-phase commits. It worked until it didn't. The first time a network partition split the database coordinator from one of the participants, the entire system froze for forty-seven minutes while the lock timed out. That's the kind of pain that justifies a saga — not the theoretical possibility of failure, but the concrete experience of it.
Hamilton and Madison never resolved the tension between centralization and federation. They couldn't — the tension is inherent to any system that distributes authority across autonomous units. The American federal system has been renegotiating that balance for 240 years. Your distributed system will renegotiate it for as long as it runs. The point isn't to pick a side. The point is to pick the side that makes the inevitable renegotiation cheaper.
The real skill in distributed systems isn't knowing the patterns. It's knowing the moment when the pain of not having them exceeds the cost of maintaining them. That moment is different for every system, and no framework can tell you when you've crossed it.
The next pattern in the series tackles one of the most debated architectural decisions in the .NET world: CQRS — separating your reads from your writes. The saga we built here will become a write-side command handler. The question is what happens on the read side.