
The Two Faces of Your Data — Why CQRS Exists
Your data model serves two masters. It optimizes for neither. CQRS splits it in half — and the cost of that split is the subject of this entire week.

What if your read model and your write model have nothing in common?
Not "slightly different." Not "could use some denormalization." Nothing. Different shapes. Different indexes. Different consistency requirements. Different access patterns. Different performance profiles. Two entirely separate descriptions of what the data means — living in the same table, served by the same ORM, fighting for the same query plan.
That's not a hypothetical. That's a reality I've encountered in every system past a certain scale. And the pattern that addresses it — Command Query Responsibility Segregation — is simultaneously one of the most powerful and most misapplied ideas in modern software architecture.
This week in The Architecture Logbook, we build CQRS from scratch. Not with a framework. Not with a library that hides the decisions. With code that makes every trade-off visible.
The query that served two masters
Here's a LINQ query from a real codebase. Not the actual code — the shape of it, abstracted, but the problem is exact:
var orderSummaries = await _context.Orders
.Include(o => o.Items)
.ThenInclude(i => i.Product)
.Include(o => o.Customer)
.Include(o => o.ShippingAddress)
.Include(o => o.PaymentHistory)
.Where(o => o.Status != OrderStatus.Cancelled)
.Where(o => o.CreatedAt >= startDate)
.OrderByDescending(o => o.CreatedAt)
.Select(o => new OrderSummaryDto
{
OrderId = o.Id,
CustomerName = o.Customer.FullName,
TotalAmount = o.Items.Sum(i => i.Quantity * i.UnitPrice),
ItemCount = o.Items.Count,
LastPaymentDate = o.PaymentHistory
.OrderByDescending(p => p.Date)
.Select(p => p.Date)
.FirstOrDefault(),
ShippingCity = o.ShippingAddress.City
})
.Take(50)
.ToListAsync();This query joins four tables, aggregates across line items, sorts payment history, and projects into a DTO — all to render a dashboard page. The SQL it generates is a multi-join monster with subqueries. On a table with 200,000 orders, it takes 800ms. The DBA is unhappy. The frontend team is unhappier.
But the same Orders table also serves this:
public async Task<Order> PlaceOrder(PlaceOrderCommand cmd)
{
var order = new Order(cmd.CustomerId, cmd.ShippingAddress);
foreach (var item in cmd.Items)
order.AddItem(item.ProductId, item.Quantity, item.UnitPrice);
order.CalculateTotal();
order.Validate(); // business rules: min order amount, credit check
_context.Orders.Add(order);
await _context.SaveChangesAsync();
return order;
}
The write path needs a rich domain model — aggregate roots, business rules, validation, invariant enforcement. It touches one order at a time. It needs strong consistency. It doesn't care about query performance across thousands of records.
The read path needs flat, pre-computed, denormalized data — customer names already joined, totals already calculated, results already sorted. It touches thousands of records. It can tolerate data that's a few seconds stale. It doesn't care about business rules.
One model. Two entirely different jobs. Neither served well.
The relational model is a compromise — and like most compromises in architecture, it works until it doesn't.
CQS: where the idea started
In 1988, Bertrand Meyer — the creator of the Eiffel programming language — formulated a principle he called Command-Query Separation. The idea was deceptively simple:
Every method should either change state (a command) or return data (a query), but never both.
// Command — changes state, returns nothing
void Withdraw(decimal amount);
// Query — returns data, changes nothing
decimal GetBalance();
// Violation — changes state AND returns data
decimal WithdrawAndReturnBalance(decimal amount);Meyer's insight was about method design, not architecture. But it planted a seed: if individual methods benefit from separating reads and writes, what happens when you apply the same principle to entire models?
CQRS: from method to architecture
In 2010, Greg Young took Meyer's method-level principle and scaled it up. Instead of separating commands and queries at the method level, he separated them at the model level. Two distinct models serving the same data:
Write Model (Command side):
Rich domain objects with behavior
Normalized storage (3NF or domain-optimized)
Strong consistency (transactions, aggregate boundaries)
Optimized for correctness, not query speed
Read Model (Query side):
Flat DTOs or view models
Denormalized storage (pre-joined, pre-calculated)
Eventually consistent (acceptable staleness window)
Optimized for query speed, not correctness rules
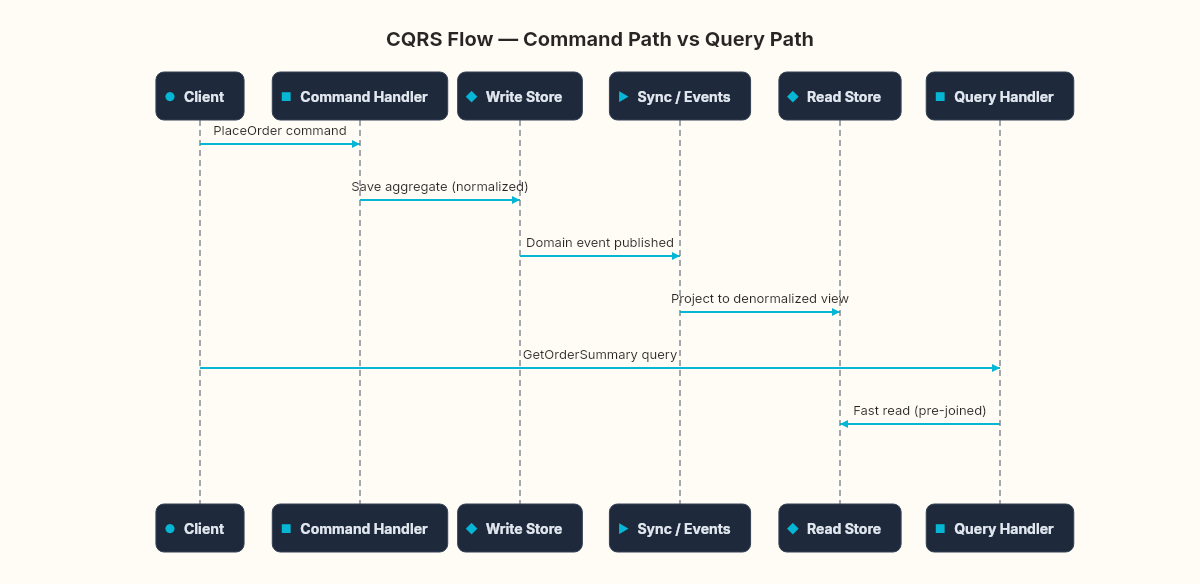
The two models can share the same database (simplest form), use different tables in the same database (moderate form), or use entirely different storage technologies — SQL Server for writes, Elasticsearch for reads, Redis for hot queries (full separation).
The architecture looks like overhead until you see the numbers.
The observer effect
In 1927, Werner Heisenberg described what became known as the uncertainty principle: the act of measuring a quantum particle's position disturbs its momentum, and vice versa. You cannot observe a system without changing it. The measurement apparatus and the measured phenomenon are entangled.
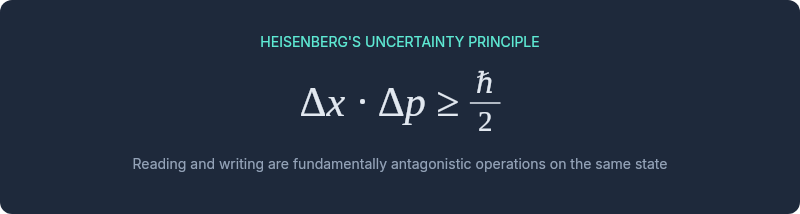
Software data has an analogous property. The model you design for writing data — enforcing invariants, maintaining relationships, ensuring consistency — actively interferes with reading data efficiently. Indexes that speed up queries slow down writes. Normalization that prevents anomalies requires expensive joins for reads. Aggregate boundaries that protect consistency create artificial barriers for cross-aggregate reporting.
Reading and writing are not just different operations. They are fundamentally antagonistic operations on the same state. Optimizing for one degrades the other. The single model is the measurement apparatus trying to observe and act simultaneously — and Heisenberg tells us that's physically constrained.
CQRS doesn't eliminate this tension. It acknowledges it and separates the concerns into models that can be optimized independently. The write model gets to be as normalized and rule-heavy as correctness demands. The read model gets to be as denormalized and fast as the dashboard requires. Neither compromises for the other.
What CQRS is not
Before we build it, three misconceptions worth clearing:
CQRS is not Event Sourcing. They're often discussed together, but CQRS works perfectly well without an event store. You can have a command handler that writes to a SQL table and a read model that queries a different SQL table. No events required. Event Sourcing is one way to populate the read model — not the only way, and not always the best way.
CQRS is not two databases. The simplest form of CQRS uses two different EF Core DbContext classes pointing at the same database — one for writes (with full entity configuration, relationships, and change tracking) and one for reads (with Dapper or raw SQL, no change tracking, no navigation properties). Same PostgreSQL instance. Different access patterns.
CQRS is not always worth it. If your application is a straightforward CRUD system where the read shape matches the write shape — a simple admin panel, a content management system, a configuration editor — CQRS adds complexity without benefit. The pattern earns its keep when read and write patterns diverge, and the cost of that divergence in a single model becomes visible in latency, query complexity, or developer friction.
The bridge from sagas
If you followed the saga pattern from the previous weeks, you've already built half of the write side. The saga orchestrator receives commands, validates them, and coordinates state transitions. The OrderSagaOrchestrator we built is essentially a command handler with compensation logic.
CQRS takes that command handler and asks: what does the other side look like? The saga knows how to change state. But what reads that state? What renders the dashboard? What populates the search results? What feeds the analytics pipeline?
The answer, in a single-model architecture, is "the same tables, with increasingly complex queries." The answer in CQRS is "a separate model, purpose-built for each consumer."
The cost
Separation is never free. CQRS introduces:
Eventual consistency. The read model lags behind the write model. A user who places an order and immediately checks their order list might not see it yet. This isn't a bug — it's a design decision. But it requires explicit handling: optimistic UI updates, polling strategies, or websocket notifications.
Synchronization logic. Something must keep the read model in sync with write-side changes. Event handlers, database triggers, change data capture, scheduled rebuilds — all viable, all with different trade-off profiles. The next article in the series about the CQRS blueprint builds the event handler approach.
Operational complexity. Two models means two schemas to migrate, two sets of queries to monitor, two failure modes to handle. When the projection handler crashes, the read model falls behind. When do you notice? How do you recover? A following chapter is entirely about these edge cases.
Cognitive overhead. Developers new to the codebase must understand that the OrderSummary table is derived, not authoritative. Writes go through command handlers, not directly to the read store. This mental model takes time to build and is easy to violate under deadline pressure.
Every architectural pattern is a bet: the cost of separation now will be less than the cost of coupling later. CQRS is that bet applied to your data model.
When the bet pays off
The pattern earns its complexity in specific conditions:
Read/write ratio is heavily skewed. Most systems read far more than they write. If your system processes 100 writes per second but serves 10,000 reads per second, optimizing the read path independently is worth the synchronization cost.
Read and write shapes have diverged. When your dashboard query joins seven tables and your write path touches one aggregate, the models have already separated in practice — CQRS just makes it explicit.
Different scaling requirements. The write side needs strong consistency and can tolerate queuing. The read side needs horizontal scaling and sub-millisecond response. CQRS lets you scale them independently — more read replicas, caching layers, different storage technologies.
Multiple read consumers. The same write events might feed a dashboard, a search index, an analytics pipeline, and a notification service. Each consumer needs a different read model. Without CQRS, each consumer writes its own complex query against the same normalized tables. With CQRS, each gets a purpose-built projection.
The question we're really asking isn't technical. It's economic: at what point does the cost of maintaining a single model exceed the cost of maintaining two?
That 800ms dashboard query and the 15ms order write are sharing a table, sharing indexes, sharing a query planner that can only optimize for one of them at a time. The compromise is invisible until it isn't — and by then, the workarounds have calcified into architecture.