
What Building an ORM Taught Me That Using One Never Could
Week 1 synthesis. Six chapters, one custom ORM, and the uncomfortable distance between knowing about something and understanding it.

I have a confession. Before this week, I thought I understood Entity Framework Core.
I've shipped production code with it across half a dozen projects. I've tuned queries, configured relationships, written custom value converters, debugged lazy loading disasters, and explained the difference between AddAsync and Add to more junior developers than I can count. I could draw the EF Core pipeline on a whiteboard. I could tell you which methods trigger immediate evaluation and which ones build expression trees.
I knew about EF Core. I didn't understand it.
The gap between two kinds of knowing
The philosopher Gilbert Ryle drew a distinction that's stuck with me since I first encountered it in a university library: knowing-that versus knowing-how.
Knowing-that is propositional. You can state it as a fact. "EF Core uses snapshot-based change tracking." "Expression trees represent code as data." "Connection pooling amortizes the cost of TCP handshakes." I knew all of this before Monday.
The distance between "I know about it" and "I understand it" was larger than I expected.
Knowing-how is procedural. You can't fully state it — you have to demonstrate it. You have to build the thing, feel where the weight is, discover which decisions are hard and which are trivial. Knowing-how lives in your hands, not in your declarative memory.
This week took me from knowing-that to knowing-how.
And the distance between them was larger than I expected.
Six chapters, six surprises
Let me tell you what actually surprised me.
Chapter 1 — The impedance mismatch is not a bug, it's geometry. I knew objects and tables don't map cleanly. But building the mapping layer made me see that the mismatch isn't a failure of ORMs. It's a mathematical inevitability. Sets aren't hierarchies. Relations aren't object graphs. Codd's relational model and object-oriented programming solve different problems with incompatible structures. No amount of engineering elegance makes circles fit into squares. You just build better adapters.
Chapter 2 — Reflection is simple until it isn't. Reading class metadata at runtime — typeof(T).GetProperties() — feels trivial. It is, for a single call. What I didn't appreciate until I built a full mapping engine was how quickly reflection becomes a design problem, not a performance problem. Which properties do you map? How do you handle inheritance? What about read-only properties, computed properties, properties that exist in the object but not in the table? The decisions are relentless. EF Core's ModelBuilder configuration API isn't overengineered. It's a scar tissue map of every edge case that someone hit in production.
Chapter 3 — Expression trees are the most underrated feature in C#. I've written LINQ queries across dozens of codebases without thinking about what happens underneath. Building a SQL generator from Expression<Func<T, bool>> forced me to understand that LINQ doesn't execute your code — it inspects it. The compiler hands you a data structure describing your intent, and you can walk that structure and translate it into anything: SQL, an API call, a validation rule, a diagram. This is metaprogramming hiding in plain sight. Most C# developers use it every day without knowing it exists.
Chapter 4 — The N+1 problem is an emergent property, not a mistake. I've diagnosed N+1 issues many times. But building an ORM that naturally produces them gave me a visceral understanding of why. It's not that lazy loading is bad design. It's that lazy loading makes the cost of a query invisible at the call site. The developer writes customer.Orders and sees a property access. The ORM sees a database round trip. The mismatch between perceived cost and actual cost is the real bug — and it's a design problem that no API can fully solve. You can eager-load, you can batch, you can project. But the tension between convenience and performance is baked into the abstraction itself.
Chapter 5 — Change tracking is a philosophical problem disguised as a technical one. How do you know what changed? You have to remember what was, compare it to what is, and infer what happened. That's not just snapshot comparison — that's the Ship of Theseus in code. If every property of an entity has changed, is it the same entity? EF Core says yes (same primary key). Our ORM says yes (same reference). But the database says "you replaced every column" — and it's right too. The answer depends on what you mean by identity. Building a change tracker doesn't teach you algorithms. It teaches you that identity is a decision, not a fact.
Chapter 6 — The dyno doesn't lie. Our ORM was 47x slower than EF Core. After optimization, 6.7x slower. The gap isn't in code quality — it's in accumulated engineering time. Thousands of hours of profiling, caching, compiled materializers, and query plan reuse. Every time someone says "let's build our own," they're competing against that accumulated time. Sometimes it's worth it. Usually it isn't.
What I'll carry forward
Three things from this week will change how I work on Monday morning. But I want to show you, not just tell you — because "showing, not telling" was the whole thesis of this week.
I'll read EF Core's generated SQL differently. Here's what I mean. Before this week, I'd look at a LINQ query and think about the result:
// What I used to see: "get customers with their orders"
var customers = await _context.Customers
.Include(c => c.Orders)
.Where(c => c.Orders.Any(o => o.Total > 1000))
.ToListAsync();After building the SQL generation layer in Chapter 3, I see the translation decisions. That Include becomes a LEFT JOIN — not a separate query — because EF Core's query pipeline detected that the filter references the navigation property. It could have issued two queries (one for customers, one for orders), but the expression tree visitor recognized the cross-entity predicate and merged them. If I change .Any() to .Count() > 0, the generated SQL shifts from EXISTS (SELECT 1 ...) to (SELECT COUNT(*) ...) > 0 — a subtle difference that matters at scale. I know this now because I wrote the expression visitor that makes that exact decision in Chapter 3, and got it wrong the first time.
// What I see now: an expression tree that EF Core's
// RelationalQueryTranslatingExpressionVisitor will walk,
// choosing JOIN strategy based on predicate shape,
// materializing via a compiled delegate (not reflection),
// and caching the query plan by expression tree structure.Knowing what's underneath makes the output legible in a way it wasn't before.
I'll reach for compiled delegates whenever reflection appears in a hot path. This was the single biggest performance insight of the week. In Chapter 6, our ORM materialized 1,000 rows in 48ms. After replacing PropertyInfo.SetValue() with compiled delegates, it dropped to 6.8ms — a 7x improvement from one structural change. The pattern is universal:
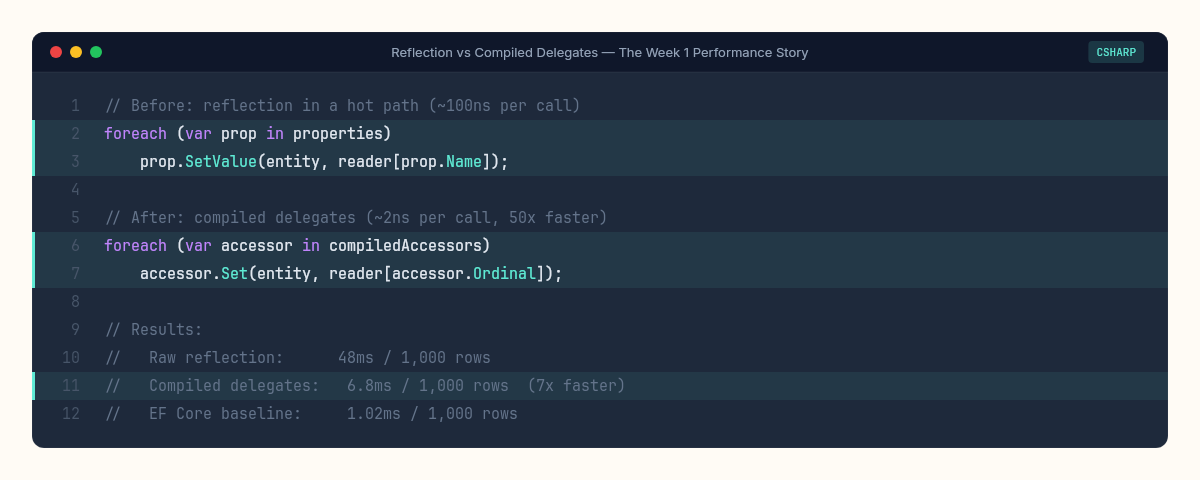
Not just for ORMs — I've used this exact pattern to speed up a claim-to-DTO mapper at a financial services platform from 12ms to 0.4ms per batch. Anywhere you call PropertyInfo.GetValue/SetValue in a loop, there's a compiled delegate waiting to replace it.
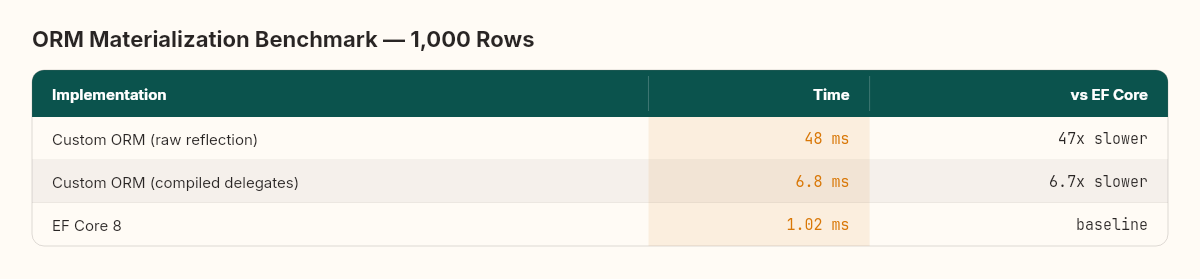
I'll be more honest about build-vs-buy decisions. Our final benchmark told the whole story: 48ms (raw) to 6.8ms (optimized) to EF Core's 1.02ms. We closed two-thirds of the gap with compiled delegates and query plan caching. The remaining 6.7x gap represents thousands of hours of engineering — buffer reuse strategies, compiled materializer specialization, query plan cache invalidation — that we'd need months to replicate. Production code serves users, not the engineer's curiosity. The right tool for learning is a scratch implementation. The right tool for production is the one with thousands of hours of optimization you didn't have to do yourself.
What's next
Week 2, we leave databases behind.
We're going to build a tiny programming language in C#. A lexer. A parser. An interpreter. From raw characters to running code, in seven chapters.
If this week taught me that ORMs are harder than they look, next week will teach me that compilers are simpler than they seem. Or at least, that's the hypothesis. The lab notebook is open.
Before then, one question to sit with over the weekend. Open your current project. Find the ORM layer. Look at a query, a save, a relationship load. Can you trace, without documentation, what's happening underneath? Not the API. The mechanism. The SQL, the snapshots, the expression trees.
If you can't, that's not a failure. It's the starting point for the same path we just walked. And the distance between "I know about it" and "I understand it" is always worth crossing.