
When Events Evolve — Versioning, Upcasting, and the Schemas You Can't Take Back
Events are immutable. Your domain model isn't. Here's what happens when those two truths collide — and five strategies for surviving schema evolution in an event-sourced system.

I shipped an event-sourced order system with five event types and no versioning strategy.
The OrderCreated event looked like this:
public record OrderCreated(Guid OrderId, Guid CustomerId, DateTime CreatedAt);Clean. Minimal. Exactly the data we needed — for three months. Then the business requirements shifted: orders needed a Currency field. International expansion. Every order needed to know whether it was EUR, GBP, or USD.
The obvious fix:
public record OrderCreated(Guid OrderId, Guid CustomerId, DateTime CreatedAt, string Currency);But the event store already contained 47,000 OrderCreated events without a Currency field. They weren't rows in a table I could ALTER. They were immutable facts — things that happened, recorded exactly as they happened. I couldn't change the past.
This is the edge case nobody mentions in the EventStoreDB quickstart. The schema problem. And it's the reason event sourcing has a reputation for being difficult in the long term.
Fossils and reclassification
In 1903, the paleontologist Elmer Riggs examined the bones of Brontosaurus excelsus and concluded it was actually the same genus as Apatosaurus ajax, described two years earlier. Under taxonomic rules, the older name takes priority. Brontosaurus ceased to exist — not the animal, the classification. The fossils didn't change. The bones in the museum drawer were the same bones. What changed was how scientists interpreted them.
For a century, paleontologists upcasted every Brontosaurus specimen to Apatosaurus. They didn't alter the fossils. They built a translation layer: when you encounter a specimen labeled Brontosaurus, read it as Apatosaurus.
Then in 2015, a comprehensive study of diplodocid morphology concluded the differences were significant enough to warrant separate genera. Brontosaurus was reclassified again — reinstated. The upcaster changed. The fossils never did.
Event versioning works the same way. The events in your store are fossils — immutable specimens from a system that has since evolved. When the domain model changes, you don't rewrite the fossils. You change how you read them.
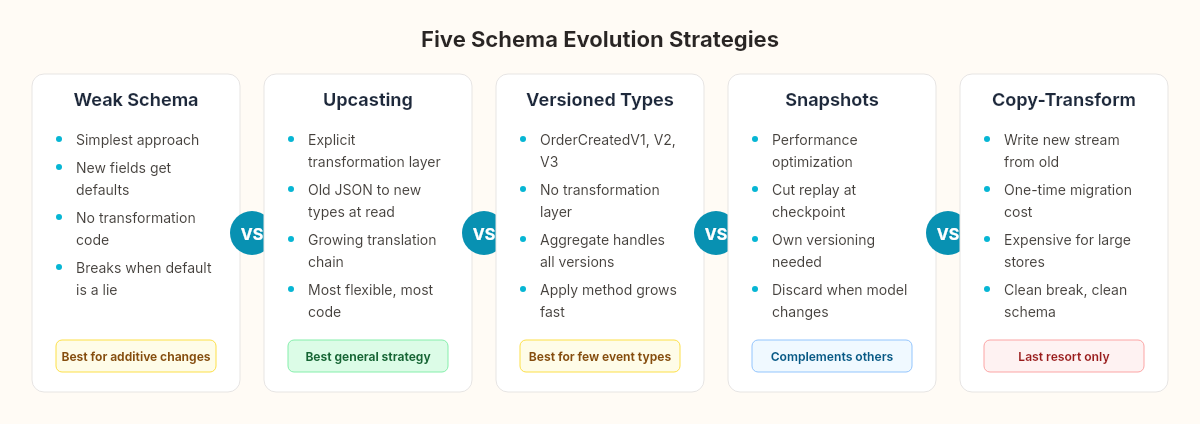
Strategy 1: Weak schema — optional fields
The simplest approach. New fields get default values when missing from old events:
public record OrderCreated(
Guid OrderId,
Guid CustomerId,
DateTime CreatedAt,
string Currency = "EUR"); // default for pre-currency eventsWhen System.Text.Json deserializes an old OrderCreated event that has no Currency property, the default parameter value fills in. No transformation code. No additional infrastructure.
Where it works: when the new field has a sensible default. Currency defaulting to EUR was acceptable for us — all existing orders were European.
Where it breaks: when the default is a lie. If orders had been multi-currency from the start and we simply hadn't captured it, defaulting to EUR would silently corrupt every non-EUR order's replay. The default must be true for all existing events, not just convenient.
Strategy 2: Upcasting — explicit transformation
When a default doesn't cut it, you transform old events into the new shape during deserialization. This is upcasting: a function that takes a version-N event and returns a version-N+1 event.
public static class EventUpcaster
{
public static IDomainEvent Upcast(string eventType, JsonElement raw)
{
return eventType switch
{
"OrderCreated" when !raw.TryGetProperty("currency", out _) =>
new OrderCreated(
raw.GetProperty("orderId").GetGuid(),
raw.GetProperty("customerId").GetGuid(),
raw.GetProperty("createdAt").GetDateTime(),
Currency: LookupOriginalCurrency(
raw.GetProperty("customerId").GetGuid())),
_ => null // no upcasting needed, use standard deserialization
};
}
private static string LookupOriginalCurrency(Guid customerId)
{
// External lookup: customer's billing country → currency
// This is a one-time migration concern, not a runtime hot path
return CurrencyLookupCache.GetOrDefault(customerId, "EUR");
}
}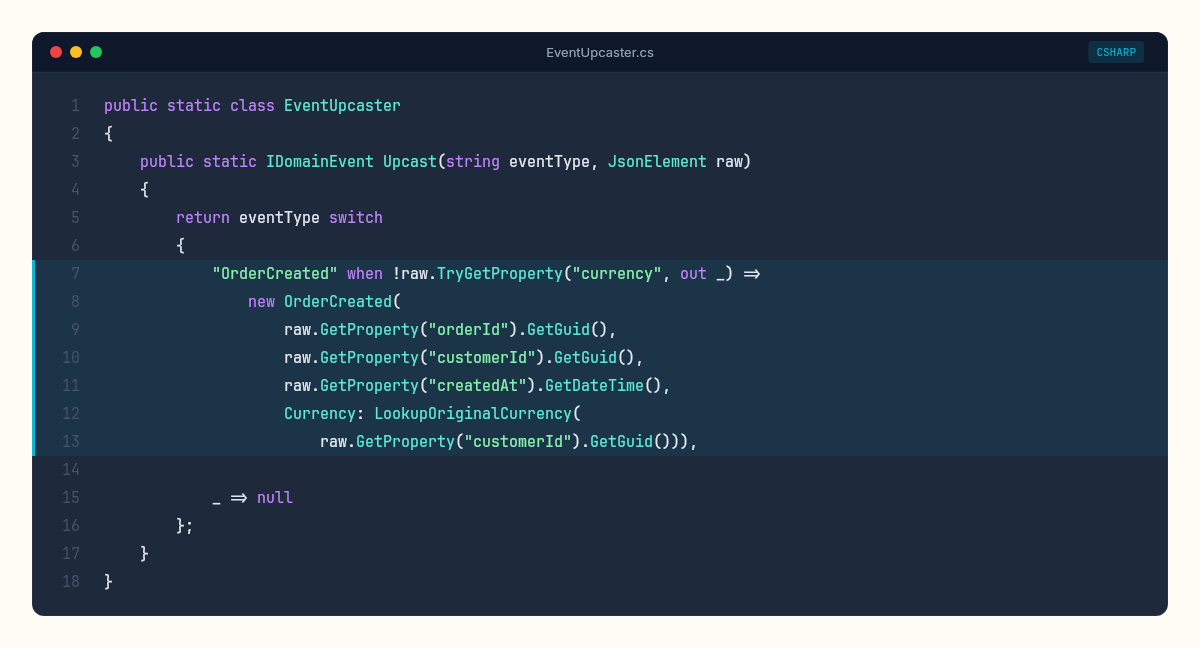
The key insight: the upcaster runs at deserialization time, not at write time. The stored bytes never change. You intercept the raw JSON before it becomes a typed event, detect the version (by checking for missing properties, or by reading a version metadata field), and transform.
The cost: the upcaster becomes a growing translation layer. Every schema change adds a case. Two years in, you might have three versions of OrderCreated chained: v1 → v2 → v3. Each transformation must be correct and composable.
// Version chain: v1 → v2 → v3
// v1: OrderCreated(OrderId, CustomerId, CreatedAt)
// v2: OrderCreated(OrderId, CustomerId, CreatedAt, Currency)
// v3: OrderCreated(OrderId, CustomerId, CreatedAt, Currency, Channel)Events are immutable. Your understanding of them isn't. The upcaster is the layer where old facts meet new context — the taxonomist's revision applied to fossils that will never change.
Strategy 3: Event type versioning — new types, not mutated ones
Instead of transforming OrderCreated across versions, introduce explicitly versioned types:
public record OrderCreatedV1(Guid OrderId, Guid CustomerId, DateTime CreatedAt);
public record OrderCreatedV2(Guid OrderId, Guid CustomerId, DateTime CreatedAt, string Currency);
public record OrderCreatedV3(Guid OrderId, Guid CustomerId, DateTime CreatedAt, string Currency, string Channel);The aggregate's Apply method handles all versions:
private void Apply(IDomainEvent evt)
{
switch (evt)
{
case OrderCreatedV1 e:
Id = e.OrderId;
Currency = "EUR";
Channel = "web";
Status = OrderStatus.Created;
break;
case OrderCreatedV2 e:
Id = e.OrderId;
Currency = e.Currency;
Channel = "web";
Status = OrderStatus.Created;
break;
case OrderCreatedV3 e:
Id = e.OrderId;
Currency = e.Currency;
Channel = e.Channel;
Status = OrderStatus.Created;
break;
}
}The advantage: no transformation layer. Each version is a separate type. The aggregate is the only place that knows how to interpret each version.
The cost: the aggregate grows. Three versions of one event means three case clauses. Multiply that across a dozen event types and five versions each, and the Apply method becomes archaeological itself — layers of historical interpretation stacked on top of each other.
Strategy 4: Snapshots — cutting the replay short
Event versioning is a schema problem. Snapshots address a different edge case: performance.
In the event sourcing pipeline we built, the Order aggregate rehydrates by replaying every event from the beginning of its stream. For an order with 15 events, that's trivial. For an aggregate with 10,000 events — a long-lived shopping cart, a financial account spanning years — replay becomes a bottleneck.
A snapshot captures the aggregate's current state at a specific stream position:
public class OrderSnapshot
{
public Guid OrderId { get; set; }
public decimal Total { get; set; }
public OrderStatus Status { get; set; }
public string Currency { get; set; }
public long StreamPosition { get; set; }
public DateTime SnapshotAt { get; set; }
}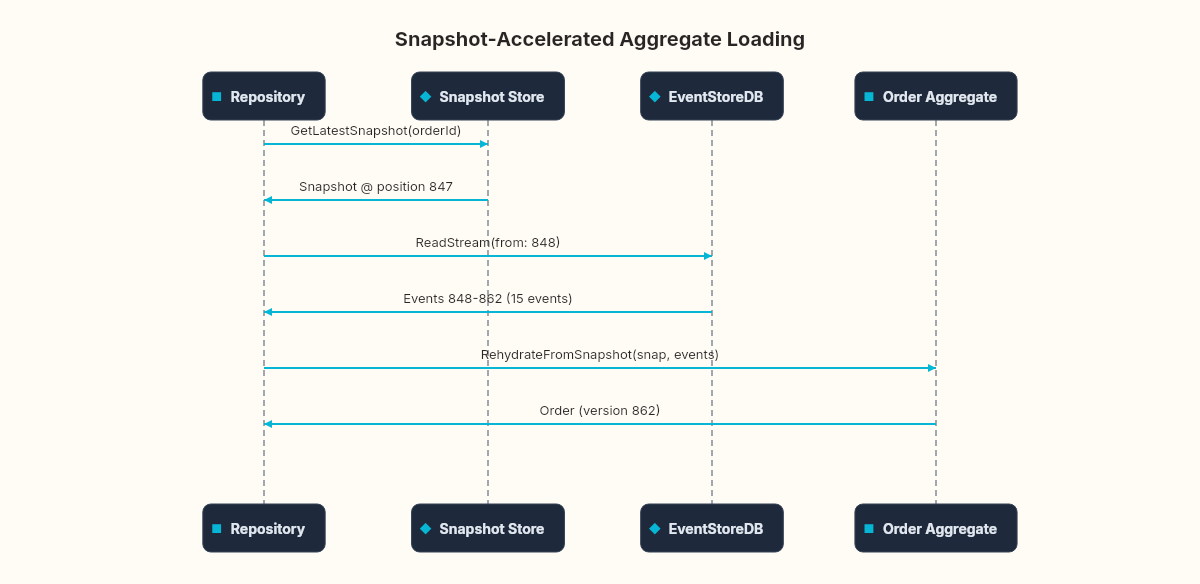
The repository changes to load from the snapshot, then replay only the events after it:
public async Task<Order> LoadAsync(Guid orderId)
{
var snapshot = await _snapshotStore.GetLatestAsync(orderId);
var startPosition = snapshot != null
? StreamPosition.FromInt64(snapshot.StreamPosition + 1)
: StreamPosition.Start;
var events = new List<(IDomainEvent, long)>();
var result = _client.ReadStreamAsync(
Direction.Forwards, $"order-{orderId}", startPosition);
await foreach (var resolved in result)
{
var evt = EventSerializer.Deserialize(resolved);
events.Add((evt, resolved.Event.EventNumber.ToInt64()));
}
return snapshot != null
? Order.RehydrateFromSnapshot(snapshot, events)
: Order.Rehydrate(events);
}When to snapshot: not eagerly. Snapshotting after every event defeats the purpose (you'd be writing state and events). A common heuristic: snapshot every N events (50, 100, 500 — measure to decide). Or snapshot when replay time exceeds a latency budget.
The hidden cost: snapshots are themselves a versioning problem. If the aggregate's shape changes (new fields, renamed properties), old snapshots may deserialize incorrectly. You need snapshot versioning on top of event versioning — or a policy that discards snapshots and replays from scratch when the aggregate model changes. I prefer the discard approach: snapshots are an optimization, not a source of truth. If in doubt, throw them away and replay.
Strategy 5: Projection failures and replay
The projection pipeline we wired with EventStoreDB subscribes to the event stream and builds read models. Three things go wrong in production:
1. Projection handler bugs. Your OrderSummaryProjection has a bug that miscalculates totals for discounted orders. You fix the code. But the read model already contains wrong data for every discounted order processed since deployment. The fix: delete the read model table, reset the subscription checkpoint to zero, replay all events. The projection rebuilds itself from scratch with the corrected logic.
// Reset and replay: drop the read model, resubscribe from start
await db.Database.ExecuteSqlRawAsync("TRUNCATE TABLE OrderSummaries");
await _checkpointStore.ResetAsync("order-summary-projection");
// Projection restarts from StreamPosition.Start on next iterationThis is the superpower the projection system promised — new projections from historical data. It's also the recovery mechanism for broken ones.
2. Out-of-order events. EventStoreDB guarantees ordering within a single stream. But if your projection subscribes to a category stream ($ce-order) or the $all stream, events from different order streams may interleave. An ItemAdded for order A might arrive before OrderCreated for order A if the subscription processes events from multiple streams concurrently.
The defense: idempotent, order-tolerant projection handlers. Check if the entity exists before updating it. If an ItemAdded arrives for an order that doesn't exist in the read model yet, either buffer it or skip it — the OrderCreated will arrive shortly and a replay will fix the gap.
case ItemAdded e:
var order = await db.OrderSummaries.FindAsync(e.OrderId);
if (order == null)
{
// OrderCreated hasn't been projected yet — skip, replay will catch it
_logger.LogWarning("ItemAdded for unknown order {OrderId}, skipping", e.OrderId);
return;
}
order.Total += e.Quantity * e.Price;
break;The null check is not defensive programming — it's a design decision. Category stream subscriptions don't guarantee cross-stream ordering. Your projection must tolerate gaps.
3. Projection lag under load. During peak traffic, the projection might fall behind the write side. This is eventual consistency working as designed — but the gap matters. If a user places an order and immediately views their order list, the projection may not have processed the event yet.
The mitigation isn't to make projections synchronous (that defeats CQRS). It's to accept the lag and design the UI for it: optimistic updates on the client, "processing" states, or read-your-own-writes semantics where the API checks the event store directly for the just-written entity before falling back to the read model.
The edge case nobody diagrams: stream growth
EventStoreDB handles large streams well — millions of events per stream is feasible. But "feasible" and "advisable" are different words.
A stream representing a user account that accumulates events for years will grow indefinitely. Loading it means reading every event (or replaying from the last snapshot). Projections subscribing to long streams process an ever-growing backlog on restart.
Three management strategies:
Archive and compact. After a domain-meaningful boundary (account year-end, order lifecycle completion), write a summary event that captures the final state and archive the detailed history to cold storage. New replays start from the summary.
// Write a compaction event that summarizes the stream's final state
await client.AppendToStreamAsync($"order-{orderId}",
StreamState.Any,
new[] { ToEventData(new OrderCompacted(orderId, total, status, DateTime.UtcNow)) });
// Archive original events to cold storage, then soft-deleteSoft-delete completed streams. EventStoreDB supports stream deletion (which is actually a tombstone — the events can be scavenged later). For short-lived aggregates (individual orders, transactions), delete the stream after the entity reaches a terminal state and the projection has processed all events.
Scavenge operations. EventStoreDB's scavenge process reclaims disk space from deleted events and streams. Schedule it during low-traffic windows — it's IO-intensive.
The events you append today will still be in your store when the next developer joins the team. Design your schemas, your versioning strategy, and your stream lifecycle as if that developer is reading them for the first time — because they will be.
None of these edge cases are reasons to avoid event sourcing. They're reasons to plan for it. A relational database has its own edge cases — migration failures, data loss from overwrites, audit gaps, schema drift between environments. Event sourcing trades one set of problems for another. The question isn't which set is smaller. It's which set you're better equipped to handle.
The next article in the series measures all of this. How fast does aggregate replay degrade as stream length grows? What's the real-world cost of snapshotting? How long does a full projection rebuild take across 100,000 events? The stress test puts numbers on everything we discussed here.