
When Read and Write Disagree — Eventual Consistency and Five Edge Cases Nobody Warns You About
The CQRS blueprint works beautifully in a tutorial. Then a user places an order and can't find it. Then a projection handler crashes at 3am. Then someone deploys a new event schema on Tuesday. Five failures that tutorials skip.

The screen refreshes and the order isn't there.
The customer placed it three seconds ago. The confirmation email arrived. The payment was charged. But the order list shows nothing new. They refresh again. Still nothing. They place the order a second time. Now they have two orders, two charges, and a support ticket that begins with "your system is broken."
That's the first thing that goes wrong when you separate reads from writes. Not a bug — a design decision that nobody explained to the customer. The write model accepted the order immediately. The projection handler that updates the read model was 400 milliseconds behind. The user was faster than the projection.
The blueprint chapter built the separation: command handlers, domain events, a write store and a read store. Clean architecture. Elegant code. Every piece working exactly as designed. But "working as designed" and "working as expected" are different things, and the gap between them is where production incidents live.
The card catalog problem
Before digital databases, libraries maintained card catalogs — physical drawers of index cards, each one describing a book. A large research library might maintain three separate catalogs: one sorted by author, one by subject, one by title. The same book appeared in all three, but each card contained different information optimized for different lookups.
When a new book arrived, a librarian had to create three cards and file them in three different places. If the librarian filed the author card but got called away before filing the subject card, the book existed in one index but not another. A patron searching by subject wouldn't find it. The book was there — the index was behind.

CQRS read models are card catalogs. The write model is the shelf where the book physically sits. The projection handlers are the librarians filing cards. And the five edge cases we're about to examine are the five ways a librarian gets interrupted.
Edge case 1: The stale read
The simplest and most common failure. A user performs a write (places an order) and immediately reads (loads the order list). The read model hasn't been updated yet.
// Command side — completes in 15ms
await _dispatcher.DispatchAsync(new CreateOrderCommand { ... });
// User immediately navigates to order list
// Query side — projection hasn't processed the event yet
var orders = await _readStore.GetRecentOrdersAsync();
// The new order is missingThe gap: Our projection handler from the blueprint processes events asynchronously. The command handler publishes the OrderCreated event, the event bus routes it, the projection handler picks it up, queries the read store, upserts the row. That pipeline takes 50-500ms depending on load. If the user's browser makes the GET request within that window, they see stale data.
Mitigation strategies (each with trade-offs):
Optimistic UI update: The client adds the order to the list locally before the server confirms the read model is updated. Fast, but can show data that the write side rejected.
// After successful command
var optimisticOrder = new OrderSummary
{
OrderId = result.OrderId,
Status = "Pending",
TotalAmount = cmd.Items.Sum(i => i.Quantity * i.UnitPrice),
CreatedAt = DateTime.UtcNow
};
// Display immediately, replace when read model catches upRead-your-writes consistency: After a write, the query handler checks the write store directly for the specific entity, then falls back to the read store for everything else. Breaks the separation for one query.
Polling with version: The command returns a version number. The client polls the read model until it sees that version. Adds latency but guarantees consistency.
The stale read isn't a bug in your system. It's a budget — how much staleness your users can tolerate before it becomes a problem.
Edge case 2: Out-of-order events
Events should arrive in the order they were published. They don't always.
Expected: OrderCreated → OrderItemAdded → OrderItemAdded → OrderConfirmed
Actual: OrderCreated → OrderConfirmed → OrderItemAdded → OrderItemAddedThis happens when the event bus delivers OrderConfirmed before the second OrderItemAdded — possible with partitioned message brokers, competing consumers, or retry logic that reprocesses earlier events after later ones have already been handled.
Our projection handler from the blueprint assumes sequential processing:
case OrderItemAdded e:
var existing = await _readStore.GetByIdAsync(e.AggregateId);
if (existing != null) // What if OrderCreated hasn't been processed yet?
{
existing.ItemCount++;
// ...
}
break;If OrderItemAdded arrives before OrderCreated, the GetByIdAsync returns null. The projection silently drops the event. The read model is now permanently wrong — the order exists but has the wrong item count.
Fix: Buffer-and-reorder, or make projections idempotent and replayable:
case OrderItemAdded e:
var existing = await _readStore.GetByIdAsync(e.AggregateId);
if (existing == null)
{
// Event arrived before OrderCreated — store in retry queue
await _retryQueue.EnqueueAsync(e, retryAfter: TimeSpan.FromSeconds(1));
return;
}
// Process normally...
break;The retry queue re-delivers the event after a short delay, by which time OrderCreated has likely been processed. If the retry also fails, the event moves to a dead-letter queue for manual inspection.
Edge case 3: Projection handler crashes
The projection handler is a process. Processes crash. When ours crashes mid-batch, some events have been processed and some haven't. On restart, where do we pick up?
Without a checkpoint, the handler replays from the beginning — reprocessing events that already updated the read model. This is why the UPSERT with ON CONFLICT DO UPDATE in our blueprint matters: reprocessing an event must produce the same result as processing it once.
public class CheckpointedProjectionRunner
{
private readonly ICheckpointStore _checkpoints;
private readonly OrderSummaryProjection _projection;
public async Task RunAsync(IAsyncEnumerable<EventEnvelope> events)
{
var lastCheckpoint = await _checkpoints.GetAsync("order-summary");
await foreach (var envelope in events)
{
if (envelope.Position <= lastCheckpoint)
continue; // Already processed
await _projection.HandleAsync(envelope.Event);
// Checkpoint after each event (or batch for performance)
await _checkpoints.SaveAsync("order-summary", envelope.Position);
}
}
}
The checkpoint store records the last successfully processed event position. On restart, the handler skips everything before that position. The cost: one extra write per event (or per batch) to the checkpoint store. A small price for crash recovery.
The subtle failure: What if the projection handler updates the read model but crashes before writing the checkpoint? On restart, it reprocesses the event. If the projection is idempotent (UPSERT), no harm done. If it's not — say, it increments a counter — the read model is now wrong by one.
Idempotency isn't optional in projections. It's the only thing standing between a crashed handler and corrupted data.
Edge case 4: Read model rebuild
Sometimes you need to throw away the entire read model and rebuild it from scratch. Schema change, data corruption, new projection logic, migration to a different read store technology. This is CQRS's superpower — and its operational challenge.
The rebuild process:
public async Task RebuildAsync(
IAsyncEnumerable<EventEnvelope> allEvents)
{
// 1. Create new read model table
await _readStore.CreateStagingTableAsync();
// 2. Replay all events against staging table
long count = 0;
await foreach (var envelope in allEvents)
{
await _projection.HandleAsync(envelope.Event,
targetTable: "order_summaries_staging");
count++;
if (count % 10000 == 0)
Console.WriteLine($"[Rebuild] Processed {count} events");
}
// 3. Atomic swap — staging becomes live
await _readStore.SwapTablesAsync(
"order_summaries_staging", "order_summaries");
Console.WriteLine($"[Rebuild] Complete — {count} events replayed");
}The staging table pattern avoids downtime: the old read model serves queries while the new one builds. The atomic swap (ALTER TABLE ... RENAME) switches them in one operation. No window where neither table is valid — the same pattern we used for Redis snapshot files in the C# Lab series.
The cost: Rebuilding a read model with 5 million events takes time. At 1,000 events/second processing speed, that's 83 minutes. During that time, the staging table is behind. After the swap, there's a brief catchup period for events that arrived during the rebuild.
The hard question: How often can you rebuild? If your rebuild takes 83 minutes and your system generates 50,000 events per hour, you accumulate 70,000 events during the rebuild that need catchup processing. The math constrains how frequently you can afford to rebuild — and how far behind you're willing to let the read model fall.
Edge case 5: Event schema versioning
Your OrderCreated event has three fields today. Next month, you need to add DiscountCode. Six months later, you need to rename ShippingCity to ShippingRegion because you expanded internationally.
Every event you've ever stored still has the old schema. Your projection handler must handle all versions:
public interface IEventUpcast<TFrom, TTo>
where TFrom : IDomainEvent
where TTo : IDomainEvent
{
TTo Upcast(TFrom oldEvent);
}
public class OrderCreatedV1ToV2 : IEventUpcast<OrderCreatedV1, OrderCreated>
{
public OrderCreated Upcast(OrderCreatedV1 old)
{
return new OrderCreated(
old.AggregateId,
old.CustomerId)
{
DiscountCode = null, // didn't exist in V1
OccurredAt = old.OccurredAt
};
}
}The upcaster transforms old events into the current schema before the projection handler sees them. The projection handler only needs to understand the latest version. Historical events are upcast on read, not modified in storage.
The alternative — weak schema: Store events as JSON and let the projection handler tolerate missing fields:
case OrderCreated e:
await _readStore.UpsertAsync(new OrderSummary
{
OrderId = e.AggregateId,
CustomerId = e.CustomerId,
DiscountCode = e.DiscountCode ?? "NONE", // graceful fallback
// ...
});
break;Simpler. More fragile. Works until a field is renamed rather than added, at which point the fallback produces wrong data instead of missing data.
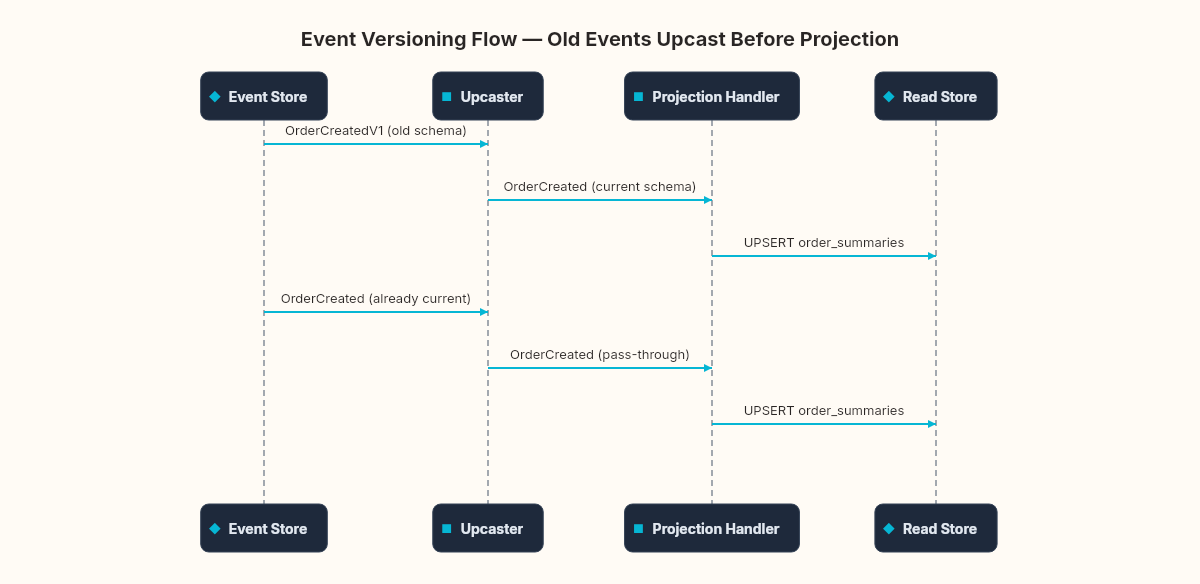
Neither approach is free. Upcasters add code per schema change. Weak schema adds null checks everywhere and breaks on renames. The choice depends on how frequently your events evolve and how long you keep historical events.
The counterpoint
Five edge cases. Five mitigation strategies. Each one adds code, complexity, and operational surface area. A reasonable person might look at this list and ask: is the separation worth it?
Sometimes, no. If your read and write patterns are similar enough — same shape, same consistency requirements, same scale — a single model with carefully placed indexes will outperform CQRS with less operational burden. The edge cases don't exist when there's only one model.
But when the patterns diverge — different shapes, different scale requirements, different consistency tolerance — these edge cases are the cost of admission to a system that can handle both independently. The stale read, the out-of-order event, the crashed handler, the rebuild, the schema evolution — they're not accidents. They're the explicit trade-offs of a specific architectural choice.
Every one of these edge cases is a conversation the architecture is having with itself — the write side saying "this happened" and the read side answering "I heard you, give me a moment." The question isn't whether the delay exists. It's whether your users and your system can tolerate it.