
When Sagas Go Wrong — Compensation Failures, Timeouts, and Partial Rollbacks
We built the orchestrator. Now we break it. Five failure modes that tutorials skip — and the uncomfortable truth about compensation.

What happens when the undo fails?
As we built in the saga blueprint chapter, the orchestrator has a clean abstraction: every step has a compensating action, and if any step fails, the compensations run in reverse. ReserveInventory / ReleaseInventory. ChargePayment / RefundPayment. Neat, symmetric, elegant.
But here's the question nobody asks in the tutorials: what if RefundPayment itself fails? What if the payment provider is down — the same instability that caused the original failure? Now you have a charged card, reserved inventory, and no mechanism to undo either one. The saga is stuck in Compensating state with no exit.
This is where the pattern gets real.
Failure mode 1: The compensation that never completes
Pilots call them "boldface" — the emergency procedures memorized verbatim because there's no time to look them up. Engine fire on takeoff. Dual engine failure. Cabin depressurization. Each procedure is a sequence of steps, and each step is designed to be executable under extreme duress.
But flight training also teaches something darker: what to do when the emergency procedure doesn't work. When you pull the fire handle and the fire doesn't extinguish. When you deploy the RAT (ram air turbine) and it doesn't extend. The industry calls these "compound emergencies" — the original failure plus the failure of the recovery.
Saga compensation failures are compound emergencies. The original step failed (payment provider rejected the charge), and now the compensation for a previous step is also failing (inventory service is unreachable). You're two failures deep with a customer waiting.
The orchestrator we built in the saga blueprint chapter handles this with... nothing. The HandleStepFailed method queues all compensations through the outbox and trusts the outbox to deliver them. If a compensation message is delivered but the receiving service returns an error, the message goes back to the queue and retries. Eventually, the service recovers and the compensation succeeds.
But "eventually" is doing a lot of work in that sentence.
// What the orchestrator sees during a compensation failure
public async Task HandleCompensationResult(
Guid correlationId, string stepName, bool success)
{
var saga = await _repository.Load(correlationId);
if (success)
{
saga.CompletedCompensations.Add(stepName);
if (saga.AllCompensationsComplete())
{
saga.CurrentState = "Failed";
saga.CompletedAt = DateTime.UtcNow;
}
await _repository.Save(saga);
return;
}
// Compensation failed — now what?
saga.CompensationRetryCount++;
saga.LastCompensationFailure = stepName;
if (saga.CompensationRetryCount > MaxCompensationRetries)
{
saga.CurrentState = "RequiresIntervention";
await _alertService.NotifyOperations(saga);
}
await _repository.Save(saga);
}When the emergency procedure fails, the correct response isn't a more complex procedure. It's a human.
That RequiresIntervention state is uncomfortable. It means the system is admitting it can't fix itself. But it's honest — and honesty is cheaper than an infinite retry loop that silently burns money or corrupts inventory counts. Aviation learned this decades ago: when the checklist is exhausted, the answer is crew judgment. In distributed systems, the equivalent is an operations team with a dashboard showing stuck sagas.
Failure mode 2: The timeout that lies
How long should the orchestrator wait for a response before declaring a step failed?
Set it too short and you'll compensate transactions that actually succeeded — the payment went through, but the response arrived after the timeout. Now you've refunded a successful payment and the customer got their order for free.
Set it too long and you'll have customers staring at spinning loaders for minutes while the system waits for a service that crashed three seconds in.
The fundamental problem is that a timeout tells you nothing about whether the operation succeeded. It tells you that you didn't get a response within your patience window. Those are different things.
public class SagaTimeoutPolicy
{
// Per-step timeout configuration
private readonly Dictionary<string, TimeSpan> _timeouts = new()
{
["ReserveInventory"] = TimeSpan.FromSeconds(10),
["ChargePayment"] = TimeSpan.FromSeconds(30),
["ConfirmOrder"] = TimeSpan.FromSeconds(5)
};
public async Task<StepResult> ExecuteWithTimeout(
string stepName,
Func<Task<StepResult>> action)
{
var timeout = _timeouts[stepName];
using var cts = new CancellationTokenSource(timeout);
try
{
return await action()
.WaitAsync(cts.Token);
}
catch (OperationCanceledException)
{
// Timeout — but did it succeed?
return StepResult.Unknown;
}
}
}Notice StepResult.Unknown. Not failed. Unknown. The saga now has three possible outcomes for each step: succeeded, failed, or we don't know. And Unknown requires different handling than Failed.
For a failed step, you compensate. For an unknown step, you query. You need a separate "status check" endpoint on each participating service: "Hey, Inventory service — did you reserve items for correlation ID X?" If yes, the step succeeded and the saga can continue. If no, it genuinely failed and you can compensate safely. If the status check itself times out... you're back to compound emergencies.
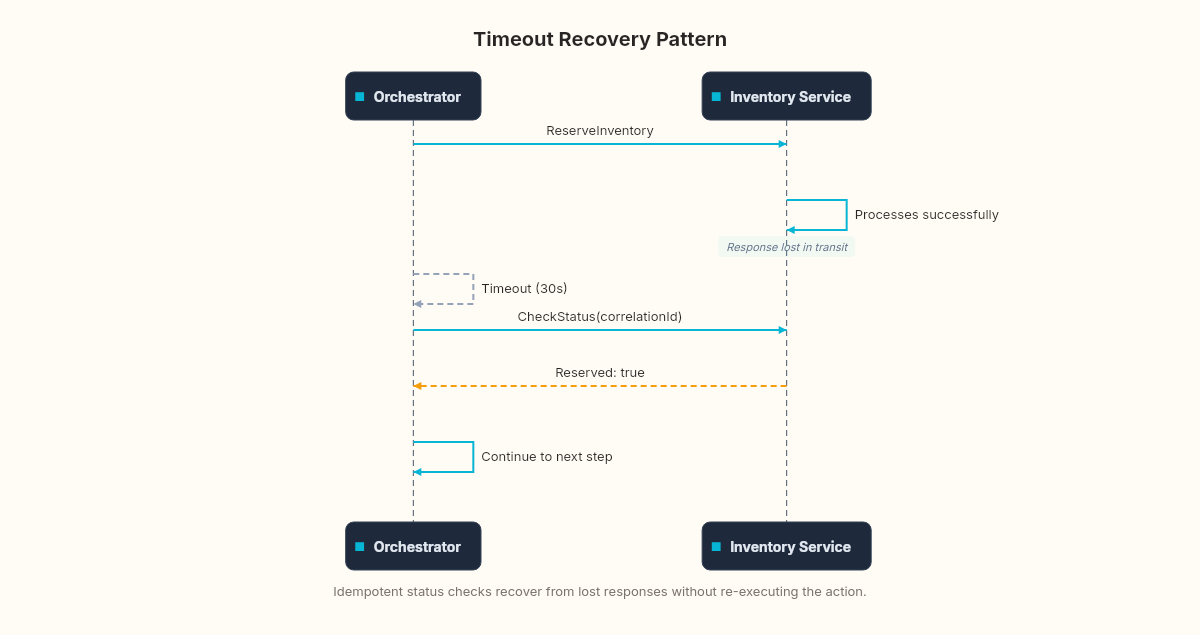
The pattern here is at-least-once delivery with idempotent status checks. The same pattern the outbox uses for message delivery. If you squint, the saga's timeout handling is another outbox problem: ensuring that you eventually get a definitive answer, even if it takes multiple attempts.
Failure mode 3: The partial success
This one is the worst. A step does something that partially succeeds.
Inventory reserves three of the five requested items because the last two are out of stock. Payment charges a partial amount. The shipping service creates a label but can't schedule a pickup.
Your step's contract says "success" or "failure." But reality says "it's complicated." And the compensating action for a partial success might be different from the compensating action for a full success.
public class ReserveInventoryResult
{
public bool Success { get; set; }
public int RequestedQuantity { get; set; }
public int ReservedQuantity { get; set; }
public List<string> UnavailableSkus { get; set; } = new();
}If the inventory service reserves three items and reports partial success, the saga has a decision to make. Is this acceptable? Can the order proceed with three items instead of five? That depends on the business rules — and those rules live in the orchestrator, not in the inventory service.
public async Task HandleInventoryResult(
Guid correlationId, ReserveInventoryResult result)
{
var saga = await _repository.Load(correlationId);
var context = JsonSerializer
.Deserialize<SagaContext>(saga.Context)!;
if (result.Success)
{
// Full reservation — proceed normally
await AdvanceToNextStep(saga, context);
return;
}
if (result.ReservedQuantity > 0
&& context.AllowPartialFulfillment)
{
// Partial — adjust the order and proceed
context.AdjustedItems = result.ReservedQuantity;
context.AdjustedTotal = RecalculateTotal(
context, result.ReservedQuantity);
saga.Context = JsonSerializer.Serialize(context);
await AdvanceToNextStep(saga, context);
return;
}
// Partial but customer wants all-or-nothing
// Compensate what was reserved
await CompensatePartial(saga, context, result);
}The SagaContext is no longer immutable. It changes as the saga progresses — adjusted quantities, recalculated totals, modified items. This makes debugging harder because the context at step 3 is different from the context at step 1. Experienced teams keep a version history in the context: what was the original request, what adjustments were made, and why.
Failure mode 4: The concurrent saga collision
Two customers order the last item at the same time. Both sagas reach the ReserveInventory step. One succeeds. The other gets "out of stock." The second saga compensates correctly.
Now a different scenario: the same customer clicks "Place Order" twice because the button didn't disable. Two saga instances start for the same order. Both reserve inventory. Both charge the card. Both confirm. The customer is charged twice with double the items reserved.
The orchestrator doesn't prevent this. It's a business-level concern that lives outside the saga.
public async Task<Guid> StartSaga(CreateOrderCommand command)
{
// Idempotency check: has this order already started a saga?
var existing = await _repository
.FindByOrderId(command.OrderId);
if (existing is not null)
{
// Return existing saga's correlation ID
// The client can poll this for status
return existing.CorrelationId;
}
// Create new saga with a unique constraint on OrderId
var saga = new SagaInstance
{
CorrelationId = Guid.NewGuid(),
OrderId = command.OrderId, // unique index
CurrentState = "NotStarted",
StartedAt = DateTime.UtcNow,
Context = JsonSerializer.Serialize(command)
};
await _repository.ExecuteInTransaction(async () =>
{
await _repository.Save(saga);
await _outbox.Send(CreateFirstStepCommand(saga));
});
return saga.CorrelationId;
}The OrderId unique index is the guard. If two concurrent requests try to create sagas for the same order, the second insert fails with a uniqueness violation. The application catches this and returns the existing saga's correlation ID.
This is the same idempotency pattern from the outbox edge cases chapter. The outbox used a MessageId to prevent duplicate delivery. The saga uses an OrderId to prevent duplicate orchestration. Same principle, different layer.
Failure mode 5: The saga that runs forever
No timeout. No failure. No response. The saga starts, sends ReserveInventory, and the inventory service... never responds. Not an error. Not a timeout. Just silence.
This happens when messages are lost (before you have an outbox), when services have bugs that silently drop messages, or when a consumer crashes after acknowledging the message but before processing it.
The defense is a saga deadline — an absolute time limit for the entire saga lifecycle, independent of individual step timeouts.
public class SagaDeadlineService : BackgroundService
{
protected override async Task ExecuteAsync(
CancellationToken stoppingToken)
{
while (!stoppingToken.IsCancellationRequested)
{
var expiredSagas = await _repository
.FindExpired(DateTime.UtcNow - MaxSagaLifetime);
foreach (var saga in expiredSagas)
{
if (saga.CurrentState is "Completed" or "Failed"
or "RequiresIntervention")
continue;
saga.CurrentState = "TimedOut";
saga.FailureReason = "Saga exceeded maximum lifetime";
// Compensate everything that completed
await _orchestrator.CompensateAll(saga);
}
await Task.Delay(TimeSpan.FromMinutes(1),
stoppingToken);
}
}
}A background service polls for sagas that have been active longer than the maximum allowed lifetime. For our order saga, that might be 30 minutes. Any saga still in progress after 30 minutes gets force-expired and fully compensated.
This is the aviation equivalent of the "bingo fuel" call — regardless of what else is happening, when you hit the fuel limit, you divert. No exceptions. The saga deadline is the bingo call for distributed operations.
The uncomfortable truth
Here's the counterpoint to everything we've built so far in this pattern.
A well-implemented saga handles the first failure gracefully. It handles the second failure (compensation failure) with retries and eventual escalation. But each additional layer of failure handling adds complexity that itself can fail. At some point, you're writing failure handlers for failure handlers, and the system is harder to reason about than the original problem it solved.
The choreographed approach from the theory chapter's stuck order had a real flaw — undefined transitions. But it also had a real advantage: simplicity. Three services, three event handlers, done. The saga orchestrator we've built over these chapters has more lines of code than the three services combined. It handles more failure modes, but it also has more surface area for bugs.
The honest answer is that most systems don't need all five of these failure modes handled in code. They need the first two (compensation retry and timeout) handled automatically, and the last three (partial success, concurrent collision, eternal saga) handled by operational procedures — a dashboard, an alert, and a human who can look at the data and make a judgment call.
In the stress-test chapter, we'll throw a thousand concurrent orders at this orchestrator with a dying payment service and measure exactly where the breaking points are. These edge cases become the test scenarios.
But as you're reading through these failure modes, ask yourself: which ones has your current system already encountered? And which ones did a human quietly fix before anyone built automation for them?
Sometimes the human fix is the right fix. The saga's job isn't to eliminate human judgment. It's to reduce how often you need it.