
Why Code Rots Even When Nobody Touches It
Software doesn't decay from use. It decays from existence. Chemistry understood this two centuries before the first compiler.

In 1777, Antoine Lavoisier sealed a piece of tin inside a glass vessel and heated it. When he opened the vessel, the tin had gained weight. This was impossible under the prevailing theory — phlogiston theory held that materials decayed by releasing an invisible substance, which meant they should get lighter as they aged. Lavoisier proved the opposite. The tin hadn't lost anything. It had gained something: oxygen from the air inside the vessel.
Decay wasn't loss. It was reaction.
This discovery overturned a century of chemistry and established the principle that governs every rusting bridge, every tarnishing coin, every crumbling stone facade: materials deteriorate not from inherent weakness but from the thermodynamic hostility of their environment toward their current state. The iron in a bridge is perfectly stable — in a vacuum. Expose it to oxygen and moisture, and the iron slowly converts to iron oxide. Not because anything struck the bridge or wore it down. Because existing in that atmosphere is enough.
The bridge didn't change. The environment made its existence untenable.
I've been watching software do the same thing for twenty years. And the phase transition model — that sharp threshold where systems snap from healthy to collapsed — showed that they break at predictable points, transitions that are properties of the ensemble, not of individual components. That was about sudden failure. This investigation is about the slow kind. The kind that happens while you're looking the other way.
Every experienced engineer has opened a codebase that nobody has touched in eighteen months, run dotnet build, and watched it fail. Not because someone broke it, but because the world moved and the code didn't. The dependencies shifted. The runtime updated. A certificate expired. An API endpoint was deprecated and removed. A security vulnerability was discovered in a library that was current when the code was written.
Nobody touched the code. It rotted anyway.
The instinct — the engineering instinct, the one drilled into us by version control systems and deployment pipelines — is to look for the change that caused the failure. Someone must have done something. Git blame should reveal the culprit. But git blame shows nothing, because nothing happened. The failure didn't come from inside the system. It came from outside.
This is deeply counterintuitive. We think of code as a static artifact — frozen in time at the moment of the last commit, stable and unchanging until someone deliberately modifies it. But code doesn't exist in isolation. It exists in an environment: a runtime, a dependency ecosystem, a network of external services, a set of security assumptions, a team's collective understanding. And that environment moves continuously, relentlessly, indifferently.
This is the next field observation in The Software Naturalist. And the question it investigates is more unsettling than it sounds: if software can decay without being changed, what exactly is doing the decaying?
Five ways a codebase dies in its sleep
Let me be specific about what I mean, because "code rot" is often used loosely to describe any kind of quality decline, including the kind caused by hasty edits and accumulated shortcuts. That's a different disease. I'm talking about code that nobody has modified — no commits, no merges, no configuration changes — that nonetheless degrades in functionality, security, or buildability over time.
Five distinct modes of this decay keep appearing in production systems:
Mode 1: Dependency drift. A project pins its dependencies at specific versions. The ecosystem moves on. Minor versions of dependencies release patches. Major versions introduce breaking changes. The pinned versions accumulate known vulnerabilities. Eventually, the dependency graph becomes unbuildable — transitive dependency A requires version 3.x of library B, but your pinned version of library C requires version 2.x. Nobody changed your code. The ecosystem changed around it.
Mode 2: Runtime evolution. Your application targets .NET 6. Microsoft ends support for .NET 6. The base Docker image is no longer maintained. Security patches stop. The SDK is removed from the default installation of development tools. Your code is identical to the day it was written. It now runs on an unsupported platform with known vulnerabilities.
Mode 3: Environmental drift. The cloud provider updates their managed database service. A default configuration changes. A network policy tightens. An API version is deprecated. Your application, unchanged, begins experiencing intermittent failures because the infrastructure beneath it shifted.
Mode 4: Cryptographic erosion. Your authentication uses SHA-1 hashes, which were considered secure when you implemented them. Collision attacks become practical. Your unchanged code now has a security vulnerability that didn't exist when it was written. The code didn't change. The mathematical landscape did.
Mode 5: Knowledge decay. The team that wrote the code has moved on. Documentation was adequate at the time but assumed shared context that no longer exists. When a new team needs to modify the code, they can't understand it — not because it's poorly written, but because the tacit knowledge required to interpret it has evaporated. The code is functionally identical. Its intelligibility has rotted.
The most insidious form of software decay is the kind that produces no symptoms until someone tries to change something. The system runs. The tests pass. The alerts are quiet. And beneath the surface, the distance between the code and its environment grows wider every day.
Each of these modes shares a single characteristic: the code is the constant, and the environment is the variable. Nothing internal changed. Everything external did.
I want to dwell on Mode 5 for a moment, because it's the most subtle. The other four modes are detectable by automated tools — vulnerability scanners, build systems, health checks. Knowledge decay is invisible to every metric. A service that lost its last maintainer 14 months ago passes every CI check, serves every request, satisfies every SLA. It's functionally identical to the day it was written. But the moment someone opens the source to make a change, they discover that the code assumes context that evaporated when the original team moved on.
I experienced this directly in 2023. A service at a large European transport operator needed a minor change — updating a discount calculation rule that had been approved two years earlier and hadn't been modified since. The service compiled. The tests passed. The deployment pipeline was green. But when the engineer assigned to the task opened the codebase, they found a domain model with entity names that referenced an internal business process that had been reorganized eighteen months prior. The enum values mapped to department codes that no longer existed. The validation rules encoded constraints from a regulatory framework that had been superseded. The code worked perfectly — for a business reality that was two years out of date.
The fix took three weeks. Not because the code was buggy. Because understanding what the code meant — translating its frozen assumptions into current reality — required archaeological investigation that no compiler or test suite could perform.
Knowledge decay is the rust you can't see from the outside.
Sixty services and a thermometer
Claiming that code decays isn't novel. Every engineer has experienced it. What's less common is measuring the rate and shape of the decay — treating it as a quantifiable process rather than a vague complaint.
I've collected data from three sources: my own professional experience across eight distinct production systems, publicly available analyses of open-source dependency decay, and the empirical literature on software aging.
Dependency half-life
A note on methodology before the numbers. Measuring software decay requires defining what "decayed" means, and the definition isn't obvious. A dependency with a known CVE is clearly decayed from a security perspective. But a dependency that's three major versions behind, with no known vulnerabilities, is also decayed from a compatibility perspective — even if nothing is technically broken today. I've measured both and they follow the same curve, shifted by roughly 6-8 months (security decay leads, compatibility decay follows).
Researchers studying the npm ecosystem found that the median time from package publication to the first known vulnerability was measured in hundreds of days — long enough for thousands of downstream projects to integrate the dependency before anyone knew it was compromised. Not the time for the vulnerability to be exploited. The time for it to exist. The vulnerability was always latent in the code. Discovery merely made it visible.
This is a crucial distinction. The vulnerability didn't appear at day 442. It was likely present from day one — a flaw in the code that nobody had identified yet. What happened at day 442 was that someone found it, documented it, and assigned it a CVE number. The code was already corroded; day 442 was merely when someone noticed the rust.
I've observed similar rates in .NET ecosystems, though the specific numbers differ. In a microservices platform I worked on between 2022 and 2025, we tracked dependency freshness across 60+ services. The results:
After 6 months of no dependency updates, 23% of services had at least one dependency with a known CVE
After 12 months, 61%
After 18 months, 89%
After 24 months, 97%
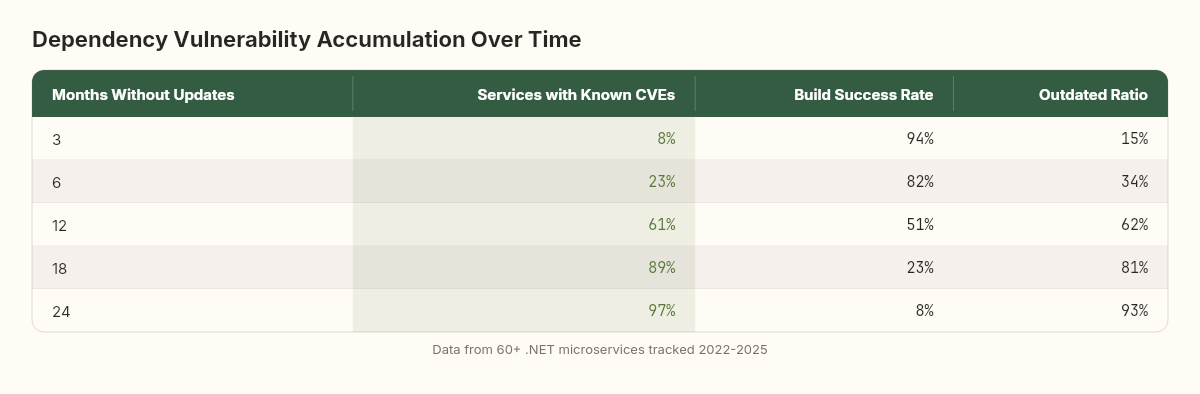
The curve is not linear. It's closer to an exponential saturation — fast accumulation early, then asymptotically approaching 100%. This shape has a name in chemistry: it's a first-order reaction kinetic. The same equation that describes radioactive decay describes the accumulation of vulnerabilities in an unmaintained dependency graph.
Build decay rate
From the same platform, I tracked a simpler metric: what percentage of services could still build clean (dotnet build with zero warnings, zero errors) after periods of inactivity?
After 3 months: 94% build clean
After 6 months: 82%
After 12 months: 51%
After 18 months: 23%
After 24 months: 8%
The primary cause was SDK and runtime updates that introduced new compiler warnings (treated as errors in our CI configuration), deprecated APIs that became errors in newer SDK versions, and transitive dependency conflicts introduced by NuGet resolution changes.
Note the shape: not a cliff, but a continuous erosion. At no single point did all services break simultaneously. The decay was stochastic — each service had its own vulnerability to environmental changes, depending on its specific dependency graph, target framework, and API surface. But the aggregate trend was monotonically downward.
API deprecation rates
Cloud providers deprecate APIs on regular cycles. Between 2020 and 2025, Azure retired or deprecated:
dozens of Storage API versions
nearly as many Compute API versions
over twenty Identity API versions
Each deprecation creates a ticking clock. Code that calls a deprecated API works today. At some point — typically 12-24 months after deprecation notice — it stops working. Not because the code changed. Because the endpoint disappeared.
Google Cloud is more aggressive. AWS is slower but follows the same pattern. The net effect is a constant environmental pressure on every deployed application, a thermodynamic gradient pushing every system toward incompatibility.
The compounding effect
What makes software corrosion particularly treacherous is compounding. Dependency drift doesn't happen in isolation. A vulnerable version of library A is often paired with an outdated version of library B that depends on A. Updating A to fix the vulnerability breaks B's API contract. Updating B to a compatible version requires updating C, which has a different vulnerability. The dependency graph doesn't corrode linearly — it corrodes as a web, where each node's decay makes neighboring nodes harder to maintain.
I tracked this compounding effect across the same 60+ services. For services that missed one update cycle (6 months), the average remediation effort was 2 engineer-hours per service. For services that missed two update cycles (12 months), the effort was not 4 hours — it was 11. For services that missed three cycles (18 months), it was 34 hours. The effort doesn't double — it grows super-linearly because each outdated dependency constrains the update paths for every other dependency.
Materials scientists have a name for this: stress corrosion cracking. When mechanical stress and chemical corrosion act simultaneously, the degradation rate isn't additive — it's synergistic. The stressed metal corrodes faster than the unstressed metal would, and the corroded metal is weaker under stress than the uncorroded metal would be. In software, "stress" is the complexity of the dependency graph. The more complex the graph, the faster each node corrodes, and the more corroded nodes make the graph harder to update.
This compounding is why teams that fall behind on maintenance rarely catch up incrementally. The effort required to remediate 18 months of decay is not 3x the effort for 6 months — it's 17x. At some point, the accumulated corrosion debt exceeds the value of remediation, and the only economically rational response is replacement. We'll return to this in the implications section.
Oxidation, passivation, and the code that rusts
The parallel to chemistry isn't decorative. The mechanisms are structurally identical.
When iron corrodes, three things are present: the metal (the reactive substrate), oxygen (the oxidizing agent), and water (the electrolyte that enables ion transport between anode and cathode sites). Remove any one of the three, and corrosion stops. Iron in a vacuum doesn't rust. Iron in dry air barely rusts. Iron submerged in oxygen-free water barely rusts. It's the combination — the specific environment — that drives the reaction.
The reaction itself is electrochemical. At anodic sites on the iron surface, iron atoms lose electrons and dissolve into solution as Fe²⁺ ions. At cathodic sites, oxygen reacts with water and the freed electrons to form hydroxide ions. The dissolved iron and hydroxide combine to form iron hydroxide, which further oxidizes to rust (Fe₂O₃·nH₂O). The iron doesn't decide to corrode. The thermodynamics of the system make corrosion the lowest-energy state.
This maps precisely to software decay:

And just as in chemistry, the rate of corrosion depends on the reactivity of the metal and the aggressiveness of the environment. A noble metal like gold barely corrodes because it's thermodynamically stable in atmospheric conditions. A reactive metal like sodium corrodes violently on contact with air.
Software has its own reactivity spectrum. A statically linked C binary with no external dependencies is the gold of software — nearly inert to environmental change. A Node.js application with 1,200 transitive npm dependencies is the sodium — fantastically reactive to any environmental shift.
The corrosion rate depends on both. Gold in seawater corrodes more slowly than iron in dry air. But even gold will corrode in aqua regia — a sufficiently aggressive environment attacks even the most noble metal. In software terms: even a minimal-dependency binary will eventually corrode if the CPU architecture it targets is discontinued, or the operating system it links against is retired, or the network protocol it speaks is superseded.
The question is never "will it corrode?" The question is always "how fast?"
The Pourbaix diagram of software
In electrochemistry, Marcel Pourbaix developed a diagram that maps the stability of a metal as a function of pH and electric potential. At certain pH-potential combinations, the metal is immune to corrosion. At others, it corrodes actively. At a narrow band between the two, it forms a protective oxide layer — a passive film — that slows corrosion to negligible rates.
Software has analogous stability regimes:
The immune zone. Code with no external dependencies, targeting a stable platform, performing pure computation. Mathematical libraries. Core algorithms. These are effectively immune to environmental decay. A quicksort implementation from 1990 still works unchanged.
The passive zone. Code with managed dependencies and regular (even if infrequent) maintenance. The dependency graph has known versions. The runtime is supported. Someone checks quarterly for breaking changes. Like the passive oxide film on aluminum, this thin layer of maintenance doesn't prevent thermodynamic attack — it slows it to a manageable rate.
The active corrosion zone. Code with extensive external dependencies, targeting a rapidly evolving platform, and receiving no maintenance. Every dependency is a reaction site. Every API call is a potential point of failure. The corrosion rate is proportional to the number of reaction sites — which is to say, proportional to the dependency count.
To make this concrete: consider three real systems I've encountered in different contexts.
System one was a mathematical calculation engine — a .NET library that performed actuarial computations using only System.Math and custom data structures. No NuGet packages. No HTTP calls. No file system access beyond reading input data. Written in 2018 targeting .NET Standard 2.0. In 2025, it still compiled, passed all tests, and produced correct results on .NET 8. Seven years, zero maintenance, zero degradation. Pure immune zone — the code had no reaction sites for environmental attack.
System two was an internal API gateway that mediated between four backend services. Twelve direct NuGet dependencies. One external API call (to an identity provider). Written in 2020, it received quarterly dependency updates through 2022, then the team was reassigned. When I reviewed it in late 2024, it still ran, but three dependencies had high-severity CVEs, the identity provider had deprecated the endpoint it used (with a sunset date six months out), and the Docker base image was two major versions behind. Passive zone with a thinning film — functional but accumulating risk at a steady rate.
System three was a customer-facing web application built on a React frontend with 847 transitive npm dependencies, a .NET BFF with 43 NuGet packages, and integrations with seven third-party services (payment, shipping, analytics, CRM, email, SMS, fraud detection). Written in 2021, it received regular maintenance through mid-2022, then entered "stable" status. By mid-2023 — twelve months of minimal maintenance — the npm audit reported 23 high-severity vulnerabilities, two of the seven third-party API versions had been deprecated, and the payment provider had changed their webhook signature verification. The system was in active corrosion. Not a single line of code had changed. The environment had dismantled it from the outside.
Most production codebases exist in the passive zone — corroding slowly, protected by a thin film of regular maintenance. The danger is mistaking passivity for immunity. The film can break. And when it does, the accumulated thermodynamic potential discharges all at once.
Passivation failure: the pitting corrosion analogy
The most dangerous form of metal corrosion isn't uniform surface rust. It's pitting corrosion — localized breakdown of the passive film that creates deep, narrow holes in an otherwise intact surface. Pitting is dangerous precisely because the surface looks fine. The metal appears healthy. But underneath, the corrosion is concentrated at specific sites where the protective layer failed, and it propagates inward much faster than uniform corrosion ever would.
Software has exact pitting equivalents:
A dependency that's updated everywhere except in one service that was forgotten during the upgrade campaign. That service runs fine — it's in the passive zone. But the one unpatched dependency is a pit: a localized failure of the maintenance film that allows environmental attack to concentrate at that point.
An API client library that handles 47 of 48 deprecated endpoint versions correctly because someone did a migration. The 48th endpoint is called by a rarely-executed error recovery path that nobody tested. The passive film is intact everywhere except at the one point that matters during a crisis.
A configuration file that references a cloud service SKU that was valid two years ago. The SKU is still listed in the provider's documentation (deprecated but functional). When the provider finally removes it, the failure will be sudden and specific — a pit in the configuration surface.
The lesson from materials science is clear: inspect for pits, not for uniform corrosion. The surfaces that look healthy are often hiding the most dangerous defects.
I once helped investigate a production incident where a payment processing service — one that had been running flawlessly for two years — suddenly failed to connect to a third-party fraud detection API. Every other service communicated with the fraud provider without issue. The payment service was the only one using a legacy client library that the fraud provider had been supporting through a compatibility endpoint. That endpoint was retired on 48 hours' notice. The payment service's passive film had a pit that nobody knew about. The rest of the surface was healthy. The pit was catastrophic.
The fix was a single library upgrade — trivial in scope, devastating in discovery time. The team spent 14 hours diagnosing the failure because the pit was invisible to every monitoring system. The service was "healthy." The dependency was "fine." The documentation said the endpoint was "supported." Until it wasn't.
First-order kinetics and the half-life of a dependency graph
If software decay follows first-order reaction kinetics — and the empirical data suggests it does — then we can model it mathematically.
In chemistry, first-order reactions follow:

Where [A] is the concentration of reactive substrate remaining at time t, [A]₀ is the initial concentration, and k is the rate constant.
For software, we can define an analogous model. Let H(t) represent the "health" of the system — the fraction of its original functionality, buildability, and security that remains at time t without any maintenance.

Where λ is the software corrosion rate — a constant that depends on the system's "reactivity" (dependency count, platform volatility, API surface area).
From the field data:
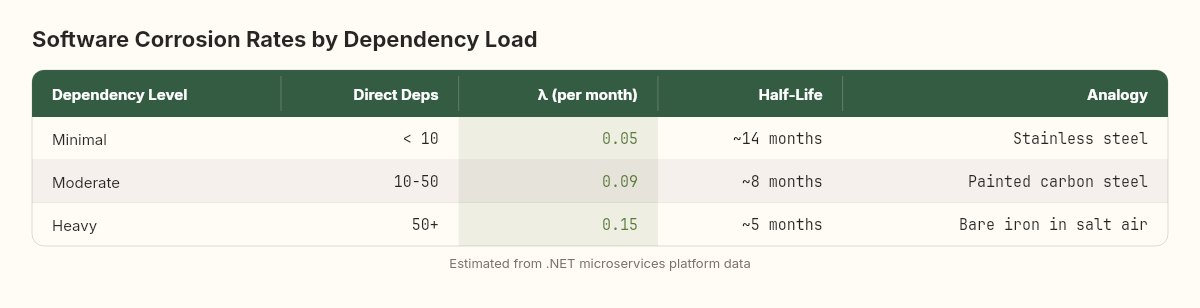

The half-life — the time for half the system's components to develop a maintenance-requiring issue — is directly analogous to radioactive half-life.
A system with 50+ direct dependencies has a half-life of about 5 months. Leave it untouched for 5 months, and roughly half its dependency graph will need attention. Leave it for 10 months, and three-quarters will need attention. Leave it for 15 months, and seven-eighths. The exponential nature means the early months feel fine. The late months feel catastrophic. But the rate was constant the entire time.
Estimating your corrosion rate
You can estimate λ for your own system with a simple experiment. Take a service that hasn't been modified in at least 3 months. Run these checks:
// 1. Check dependency freshness
// Run: dotnet list package --outdated
// Count packages with newer versions available (N_outdated)
// Count total packages (N_total)
// Outdated ratio = N_outdated / N_total
// 2. Check security vulnerabilities
// Run: dotnet list package --vulnerable
// Count packages with known CVEs (N_vulnerable)
// 3. Check build health
// Run: dotnet build --warnaserror
// Record: builds clean (1) or fails (0)
// 4. Check runtime support
// Verify target framework is still in active support
// Check: https://dotnet.microsoft.com/platform/support/policy
Track these metrics monthly. Plot the outdated ratio over time. The slope of the natural log of (1 - outdated_ratio) gives you -λ. For most .NET applications, you'll find λ between 0.04 and 0.20 per month.
What you'll discover is that λ is not a fixed property of your code. It's a property of your code in its specific environment. The same service deployed to an Azure App Service (where the runtime is managed and updated by Microsoft) will have a different corrosion rate than the same service deployed to a self-managed VM (where the runtime is whatever you installed and forgot about). The code is identical. The corrosion rate is different. Because corrosion is a reaction between substrate and environment — change either, and the rate changes.
This has a practical corollary that most teams miss: migrating to a new platform changes your corrosion rate, even if you don't change a line of code. Moving from a self-hosted VM to a managed container service might reduce λ for runtime decay (the platform handles updates) while increasing λ for API drift (managed platforms evolve faster). The net effect depends on which decay mode dominates your specific system.
The maintenance budget as corrosion inhibitor
In materials science, corrosion is managed through inhibitors — chemicals added to the environment that slow the reaction rate. Chromium in stainless steel creates a self-healing oxide layer. Zinc coatings on galvanized steel sacrifice themselves to protect the iron beneath. Paint creates a barrier between the metal and the atmosphere.
Each inhibitor has a cost and an effectiveness. Chrome is expensive but creates near-permanent protection. Paint is cheap but degrades over time and must be reapplied. Galvanization is moderate on both counts.
Software maintenance inhibitors follow the same pattern:
Automated dependency updates (Dependabot, Renovate) — the galvanization approach. Moderate cost to set up, continuously sacrificial (creates merge requests that consume review time), but effective at preventing the accumulation of vulnerability pits. Reduces effective λ by roughly 40-60% in my experience.
Regular dependency audits (quarterly) — the paint approach. Periodic, requires reapplication, less effective than continuous monitoring but catches the major issues. Reduces effective λ by roughly 20-30%.
Minimal dependency strategy (fewer dependencies from the start) — the stainless steel approach. Higher upfront cost (you write more code yourself instead of importing libraries), but dramatically reduces the reactive surface area. A service with 8 dependencies instead of 80 has fundamentally different corrosion characteristics.
Pinning to LTS runtimes — the noble metal approach. .NET LTS releases (.NET 6, .NET 8) have 3-year support windows versus 18 months for STS releases. This doesn't eliminate corrosion, but it extends the window of passive protection.
All maintenance is corrosion management. It's not about improving the code. It's about maintaining the passive film between the code and its environment. When teams cut maintenance budgets — "the system is stable, let's allocate those engineers to new features" — they're not saving money. They're removing the zinc coating and hoping it doesn't rain.
Zinc anodes, expansion joints, and the maintenance budget you can't cut
If software corrosion is a thermodynamic inevitability — and the evidence says it is — then the design question isn't "how do we prevent decay?" It's "how do we design systems that decay gracefully?"
Reduce the reactive surface
Every dependency is a potential corrosion site. Every API call to an external service is a reaction surface. Every configuration reference to an environment-specific resource is a point where environmental change can attack.
The single most effective anti-corrosion strategy is reducing the number of points where the environment contacts the code. This doesn't mean avoiding all dependencies — that's the software equivalent of building a bridge from gold. It means being deliberate about which dependencies you accept, understanding that each one creates a long-term maintenance obligation.
A useful heuristic: before adding a dependency, calculate the maintenance cost as dependency_count × λ × time_horizon. If you're planning to maintain this system for 3 years, and each dependency adds approximately 0.01/month to your corrosion rate, then adding 10 dependencies commits you to roughly 0.36 units of accumulated decay — a meaningful fraction of the system's health budget.
Design corrosion joints
In bridge engineering, expansion joints are deliberate gaps in the structure that absorb thermal expansion and contraction. Without them, the bridge would crack. The joints don't prevent environmental stress — they concentrate it at designed points where it can be managed.
Anti-corruption layers, API abstraction interfaces, and dependency inversion serve the same function in software. They don't prevent environmental change from reaching your code. They concentrate the impact at a single interface where it can be absorbed through a localized update rather than propagating through the system.
When a cloud provider deprecates an API, the code behind an anti-corruption layer needs one change — in the adapter. Without the layer, every caller of that API needs a change. The corrosion rate is the same, but the repair surface is minimized.
The mathematics are instructive. Suppose you have 15 services that each call a cloud provider API directly. When the API changes, you have 15 corrosion sites to repair. But if those 15 services call an internal abstraction layer, and only the abstraction layer calls the provider API, you have 1 corrosion site. You haven't reduced λ — the environment is equally aggressive in both cases. But you've reduced the cost per unit of corrosion by a factor of 15.
This is the engineering principle behind sacrificial anodes. Ships use zinc blocks bolted to their hulls. The zinc corrodes instead of the steel. The ship still corrodes — thermodynamics guarantees it — but the corrosion is concentrated at replaceable, inspectable, cheap components instead of spreading across the structural hull. Anti-corruption layers are your zinc anodes.
Compartmentalize to contain the cascade
Recall the compounding effect from the field data: corrosion in one dependency constrains update paths for neighboring dependencies. This cascade propagates faster through densely connected dependency graphs. The mitigation is architectural: decompose into modules with minimal dependency overlap.
If service A and service B share zero dependencies, a corrosion event in A's dependency graph cannot constrain B's remediation. If they share 40% of their dependencies, A's corrosion is B's constraint. In materials science, this principle drives the design of composite materials — layers of different metals with different corrosion properties, so that degradation in one layer doesn't propagate to the next.
In .NET terms: independently deployable services with isolated dependency graphs corrode independently. A monolith with a single dependency graph corrodes as a monolith — every corrosion event affects every module. This is a maintenance argument for modular architecture that has nothing to do with scaling or team organization. It's a corrosion argument. Isolated modules have independent λ values. Coupled modules share a single, higher λ.
Monitor the passive film
The most dangerous moment in a codebase's life is when the maintenance team declares the system "stable" and redirects engineering effort elsewhere. This is the moment the passive film starts thinning.
Monitor corrosion indicators continuously, even — especially — for systems that seem healthy:
Dependency age: average age of pinned dependencies. Rising steadily = passive film thinning.
CVE accumulation rate: new vulnerabilities per month in the dependency graph. Increasing = environment becoming more aggressive.
Build reproducibility: can you build the same artifact from the same source? Failing reproducibility is the first sign of environmental drift.
Test relevance: are the tests still testing against current reality? Tests that mock an API version that no longer exists are corroded tests — they pass but verify nothing.
Accept the thermodynamics
And here is the uncomfortable truth that this investigation reveals: software maintenance is not optional. It is a thermodynamic requirement. The second law doesn't care about your sprint planning. The environment will change. Dependencies will age. APIs will deprecate. Runtimes will lose support. And if you do nothing, the system corrodes — not as a metaphor, but as a measurable, predictable process with a calculable rate.
The question was never "should we allocate time for maintenance?" The question is: "given our system's corrosion rate, how much maintenance is required to keep the passive film intact?"
You can calculate this. If your system has 40 direct dependencies and a measured λ of 0.10/month, your annual corrosion budget is approximately 40 × 0.10 × 12 = 48 dependency-months of accumulated decay per year. That translates, using the compounding data from our field observations, to roughly 200-400 engineer-hours of maintenance per year — or about 10-20% of one engineer's full-time capacity. This isn't a guess. It's a calculation based on measured rates. And it's a non-negotiable operating cost, as real as electricity or hosting fees.
When organizations treat maintenance as discretionary — "we'll do it when we have capacity" — they're making the same mistake as a building manager who cancels the roof inspection to save money. The savings are real. The corrosion is also real. And the corrosion doesn't wait for capacity to appear in the sprint plan.
Any other framing is wishful thinking dressed as engineering.
The corrosion model is useful, but honest about where it breaks down.
Non-uniform environments. Real software environments aren't static or uniform. A system running on a rapidly-evolving cloud platform corrodes faster during periods of heavy platform change and slower during stable periods. The rate constant λ is not truly constant — it fluctuates with the aggressiveness of the environment. The first-order model is a useful approximation, not a physical law.
Compensatory mechanisms. Some forms of decay trigger compensatory responses — a failed health check restarts a service, an expired certificate triggers an automatic renewal, a deprecated API falls back to a compatibility shim. These mechanisms extend the effective lifetime of a system beyond what the corrosion model predicts. They're the equivalent of cathodic protection in engineering — active systems that counteract the thermodynamic gradient.
The renovation paradox. Sometimes the most cost-effective response to corrosion isn't maintenance — it's replacement. A system that would require 6 months of dependency upgrades to bring current might be rewritten from scratch in 3 months on a modern stack. The corrosion model measures the decay of the existing system, but doesn't capture the economics of when replacement becomes cheaper than repair. Materials science has the same problem: at some point, you don't repaint the bridge. You build a new one. The next observation in this series — the half-life of a technical decision — will explore this economics more carefully.
Ecosystem-level corrosion. The model treats the environment as external to the software. But in a microservices architecture, each service is part of the environment for every other service. When service A corrodes and its behavior changes subtly — a slightly different response format, a new error code, a tighter rate limit imposed by its own load changes — it becomes an environmental stressor for services B, C, and D. The ecosystem corrodes itself. This self-referential degradation is closer to biological aging than to chemical corrosion, and it may require a different model entirely — one we'll approach in later observations.
Field notes
Codebases grow in S-curves, approaching carrying capacity like biological populations. Systems fail at phase transitions, collapsing at thresholds that physics predicted centuries ago. And now we've watched code decay without being touched — corroding from environmental exposure at a measurable rate that chemistry described before the first computer existed.
The three observations connect. The growth curve shows where a system is heading. The phase transition shows where it will break under load. The corrosion rate shows how quickly it degrades when you look away.
Together, they suggest something that I find both humbling and clarifying: software is not a static artifact. It's a material in an environment. It has thermodynamic properties. It reacts with its surroundings. It corrodes, fractures, and degrades according to principles that were established long before anyone imagined a computer.
We didn't invent these behaviors. We inherited them from physics and chemistry. And the sooner we stop treating maintenance as an optional luxury and start treating it as a thermodynamic requirement, the sooner our systems will start lasting as long as the bridges and buildings designed by engineers who understood corrosion two centuries ago.
Somewhere in every system, there is a service that nobody has touched in six months. Its build is green. Its alerts are silent. And the distance between what it assumes and what the environment provides has been growing, quietly, every day that nobody was looking.