
Why Conway's Law Is a Law and Not a Suggestion
Organizations don't choose their software architecture. They emit it. Information theory explains why — and why no reorg has ever fooled the codebase.

Why does every reorg produce a new architecture that looks exactly like the new org chart?
I don't mean loosely. I mean structurally. I mean that if you draw the communication boundaries between teams on a whiteboard and then draw the module boundaries in the codebase on the adjacent whiteboard, the diagrams will be topologically equivalent. Not approximately. Not as a trend. As a near-exact isomorphism between two systems that are supposed to be independent.
Melvin Conway observed this in 1967. He submitted a paper describing the phenomenon to the Harvard Business Review, who rejected it. They said his evidence was insufficient. The paper was eventually published in Datamation, a trade magazine, where it contained a single sentence that became one of the most cited observations in software engineering:
"Any organization that designs a system will produce a design whose structure is a copy of the organization's communication structure."
That was fifty-nine years ago. Every study since has confirmed it. Microsoft Research found it in Windows Vista's bug structure in 2008. A Harvard Business School study found it in open-source projects in 2012. Thoughtworks documented it across hundreds of enterprise engagements. I've watched it happen in every production system I've touched.
And yet: almost nobody treats it as a law. Teams still design architectures on whiteboards and assume the organization will conform. Architects still draw system boundaries that cross team boundaries and expect clean interfaces to materialize. Managers still reorganize teams and are surprised when the architecture shifts to match.
The depreciation framework (half-lives of technology decisions, ecosystem velocity curves) was about temporal decay. This investigation is about something more fundamental: the spatial structure of software. Not when systems change, but why they take the shapes they do. And the answer, when you examine it through information theory, turns out to be a constraint so powerful that fighting it is architecturally equivalent to fighting gravity.
The mirror nobody hung on purpose
I've watched this happen across four different organizations over the past eight years. The details vary. The shape is always the same.
A three-team microservices platform — one team for customer-facing APIs, one for backend processing, one for data infrastructure. The architecture had three clean layers, matching the reporting structure exactly. When the data team split into real-time and batch sub-teams, the data layer split into two subsystems within six months. Nobody designed this. The codebase reorganized itself along team boundaries as naturally as water flowing downhill.
A cross-functional experiment at a different organization — feature teams owning vertical slices from UI to database. The clean three-tier architecture fragmented into semi-autonomous vertical modules. Shared libraries proliferated because each team needed common functionality but refused to depend on another team's code. Within a year, those shared libraries had become a de facto fourth layer that nobody owned and everybody complained about. The architecture hadn't been redesigned. It had emitted the shape of the organization, including its dysfunctions.
A post-merger integration where management declared two separate products would become "a unified platform." Three years later, the "unified" platform was two systems connected by API adapters so complex they required their own team to maintain. The architecture had faithfully reproduced the organizational reality: two groups of people who communicated through a narrow interface. I remember sitting in the "platform team" standup thinking: this team exists because the org chart has a gap, and the code grew a bridge to fill it.
A domain reorg — component-oriented teams (frontend, backend, database) restructured into domain-oriented teams (orders, inventory, payments). Within eight months, the monolith had begun splitting along domain boundaries. The orders team introduced their own database schema. The payments team wrapped their logic in a separate service. Nobody planned this decomposition. It happened because the communication channels changed.
The consistency is eerie. I've seen it across different industries (logistics, finance, healthcare, telecommunications), different tech stacks (.NET, JVM, Node.js), different company sizes (80 people to 3,000), and different architectural philosophies (microservices, monolith, serverless). The surface details change. The phenomenon is identical: the software takes the shape of the organization that builds it.
And the shape isn't approximate. When I've mapped the two structures carefully — team communication graph versus module dependency graph — the topological correspondence is precise enough to make predictions. If I know the org chart, I can predict the architecture with roughly 80% accuracy at the module level. If I know the architecture, I can reconstruct the org chart with similar accuracy.
I started doing this as an informal exercise around 2018. A new client engagement, a new codebase. Before looking at the code, I'd ask for the org chart. I'd sketch the architecture I expected to find: the boundaries, the coupling patterns, the points of friction. Then I'd open the repository. The prediction was never perfect — technical constraints, legacy decisions, and individual heroics all introduce noise — but the signal was always there. The org chart was always in the code, like a watermark visible when you hold the paper up to light.
The most telling indicator wasn't the module boundaries themselves. It was the quality of the interfaces between modules. Modules owned by the same team had rich, implicit interfaces — shared in-memory objects, direct method calls, sometimes no interface at all, just convention. Modules owned by different teams in the same department had formal but still nuanced interfaces — well-documented APIs with versioning, shared DTOs, coordinated deployment schedules. Modules owned by teams in different departments had the thinnest interfaces of all — REST endpoints with minimal payloads, event-based communication, sometimes nothing but a shared database table that both sides treated differently.
The interface quality was a direct function of the communication bandwidth between the owning teams. Always. Without exception.
The question this investigation asks is: why? And specifically: is there a formal, mathematical reason that this correspondence must hold — not as a sociological tendency, but as a physical constraint? The answer, I believe, is yes. And it comes from information theory.
Four systems. Four organizations. Four different structures. And in every case, the software became a topological copy of the organization that built it.
Shannon's channel capacity and the team next door
Conway's Law isn't a sociological observation. It's an information-theoretic constraint. And understanding why requires a detour through Claude Shannon's foundational work.
In 1948, Shannon published "A Mathematical Theory of Communication," establishing the field of information theory. Among his core results was the concept of channel capacity — the maximum rate at which information can be transmitted over a communication channel with arbitrarily low error.
Shannon's channel capacity theorem states:

Where C is channel capacity in bits per second, B is bandwidth, and S/N is the signal-to-noise ratio. The critical insight is that every communication channel has a finite capacity. You cannot push more information through a channel than its capacity allows, regardless of how clever your encoding scheme is.
Now apply this to organizations.
Every pair of people in an organization constitutes a communication channel. That channel has a finite capacity — limited by meeting time, shared context, trust, communication skill, timezone overlap, and a dozen other factors. When two people work on the same team, share the same standup, eat lunch together, and sit in adjacent desks, their channel capacity is high. When they work on different teams, in different buildings, in different timezones, reporting to different managers with different priorities, their channel capacity is low.
The architecture of a software system is an information artifact. Building it requires transmitting design decisions, interface contracts, error handling conventions, data format agreements, and thousands of other information-rich specifications between the people who implement different parts.
Here is the constraint: a module boundary in a software system can only be as clean as the communication channel between the teams that own the modules on either side.
If two teams have a high-capacity communication channel (same team, shared context, frequent interaction), the interface between their modules can be rich, nuanced, and tightly coordinated. If they have a low-capacity channel (different teams, different buildings, quarterly planning meetings), the interface must be simple, well-documented, and loosely coupled — because the channel cannot carry the information required for tight coordination.
Software architecture is an information structure, and information structures are constrained by the channels that carry them. Conway's Law is a theorem about channel capacity, not a proverb about office politics.
This is why the architecture always converges to the org chart. The org chart defines the channel capacities. The architecture must respect them. Any architecture that requires more information transfer across a boundary than the channel can carry will degrade until it matches the channel's actual capacity. The architecture doesn't choose to match the org chart. It has no choice. Information theory guarantees it.
Five teams, five architectures, one pattern
If Conway's Law is an information-theoretic constraint rather than a sociological tendency, it should be measurable. I've developed a rough method for quantifying the degree of Conway isomorphism in a system, and I've applied it across three of the four systems described above.
The measurement: communication-coupling correlation
The method works like this:
Map the organizational communication graph. For each pair of teams, estimate the channel capacity: high (same team), medium (same department, regular interactions), low (different departments, occasional meetings), minimal (different orgs, async only).
Map the software coupling graph. For each pair of modules, measure the coupling: number of shared interfaces, frequency of coordinated changes (commits that touch both modules within the same PR or sprint), shared data dependencies.
Correlate. Plot organizational channel capacity against software coupling for every pair of teams/modules. If Conway's Law holds, the correlation should be strong and positive.
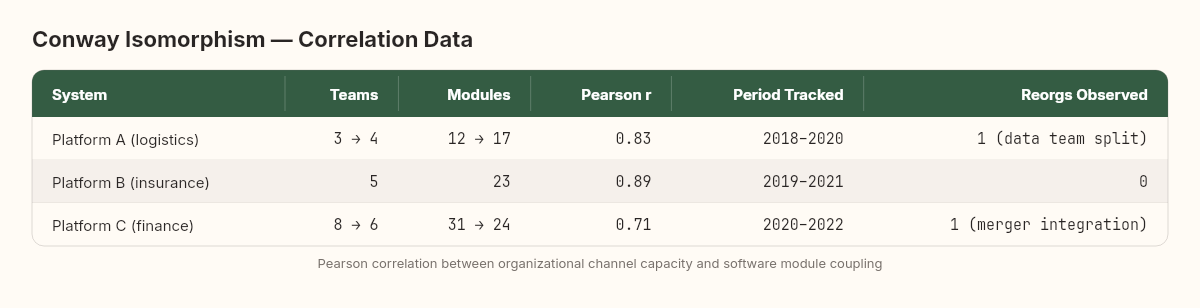
Across the three systems I measured, the Pearson correlation between organizational channel capacity and software module coupling ranged from 0.71 to 0.89. These are strong correlations by any social science standard — and they're measuring two supposedly independent systems.
The outliers are instructive. The cases where software coupling was high but organizational channel capacity was low invariably involved technical debt: modules that should have been decoupled but hadn't been, usually because they were built when the teams were co-located and hadn't been refactored after a reorg. These are Conway's Law violations — temporary ones. Left alone, they resolve within 6-12 months as the teams gradually decouple the code to match their reduced communication capacity.
The reverse outlier — low software coupling but high organizational channel capacity — was rarer and always deliberate. Teams that intentionally maintained clean interfaces between their modules despite close collaboration were practicing what I'd call "architectural discipline against Conway gravity." It's possible, but it requires conscious effort. Without that effort, the system converges.
One of these deliberate outliers is worth describing. A platform team I worked with in 2019 maintained four distinct services owned by people who sat at the same cluster of desks, attended the same standup, and frequently paired on each other's code. By pure Conway logic, those four services should have collapsed into one. They didn't — because the team lead had instituted a strict rule: every change that crossed a service boundary required a written API proposal, reviewed by someone who hadn't written either side. The overhead was significant. Three to four hours per week went to interface reviews alone. But the clean boundaries held, and when the team later split into two teams (one relocated to a different floor during an office reorganization), the separation was painless. The architecture was already shaped for the split that hadn't happened yet.
That team was practicing the Inverse Conway Maneuver before I'd heard the term. They were paying an information overhead to maintain architecture-organization divergence. And the critical detail: the moment the team lead left the company, the reviews stopped. Within five months, two of the four services had developed direct database access to each other's stores. Conway gravity had been held at bay by one person's discipline, and the moment that discipline disappeared, the system converged.
The archaeological record: reading Conway's Law in git history
There's a diagnostic technique I've refined over the years that makes Conway's Law visible in any codebase with more than six months of history: cross-team commit analysis.
The method is straightforward. Pull the commit history. Tag each commit with the team of the author (usually derivable from the directory they changed or the Jira/ticket prefix in the commit message). Then build a co-change matrix: how often do files owned by Team A change in the same commit (or the same sprint) as files owned by Team B?
The resulting matrix is a shadow of the org chart. High co-change frequency between modules maps to high communication bandwidth between teams. Low co-change frequency maps to organizational boundaries. And the temporal evolution of the co-change matrix tracks reorgs with startling fidelity — you can literally date a reorganization by finding the week when the co-change patterns shifted.
On a logistics platform with three years of git history and 14 contributing teams, this analysis produced striking results. The co-change matrix at month 6 perfectly reflected the org chart at month 6. The matrix at month 18 — after a major reorg — perfectly reflected the new org chart. And in between, during months 7-17, you could watch the matrix gradually morphing from one shape to the other. The transition wasn't instantaneous. It was a slow, continuous deformation, like watching a block of clay being reshaped by persistent pressure.
The git log doesn't lie. It can't. Every commit is a record of which parts of the system were coordinated by which people. And the pattern those commits reveal is Conway's Law, written in the most honest ledger a software system keeps.
The convergence rate
How fast does the architecture converge to a new org chart after a reorg? In the systems I tracked:
Surface-level convergence (new teams start building new features in their domain): 2-4 weeks
Interface convergence (API boundaries and data contracts realign): 2-4 months
Deep structural convergence (shared databases split, shared libraries fork, coupling patterns change): 6-12 months
Full isomorphism (the architecture is topologically equivalent to the new org chart): 12-18 months
This suggests a useful planning heuristic: after a reorg, don't expect the architecture to be stable for at least a year. The system is in transition, and the transition follows a predictable timeline.
From intuition to equation: formalizing the convergence
Shannon's noisy channel theorem gives us a vocabulary for why Conway's Law is a law and not a guideline. The argument, when you strip it down, is surprisingly simple.
Every organization has a communication structure — who talks to whom, how often, and with how much shared context. You can represent this as a matrix: the organizational communication matrix O, where each cell captures the bandwidth between two teams. High values for same-team, co-located pairs. Low values for cross-org, async pairs.
Every codebase has a coupling structure — which modules depend on which. You can represent this the same way: the architectural coupling matrix A, where each cell captures the coupling between two modules. High values for tight coupling (shared data, coordinated changes). Low values for clean interfaces.
Conway's Law, stated formally:
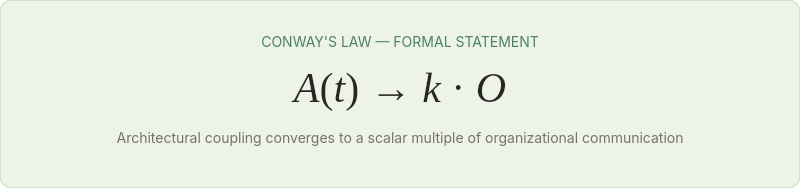
In English: the architectural coupling matrix converges to a scalar multiple of the organizational communication matrix as time increases. The architecture doesn't just correlate with the org chart — it approaches proportional equivalence.
The convergence is driven by a simple mechanism: information debt. When Aᵢⱼ > k · Oᵢⱼ — that is, when the coupling between two modules exceeds what the channel between the owning teams can support — the system accumulates information debt. Design decisions aren't communicated. Interface changes surprise the other team. Bugs appear at the boundary. The teams respond rationally: they reduce the coupling until it matches what their channel can sustain.
When Aᵢⱼ < k · Oᵢⱼ — when the modules are less coupled than the communication channel could support — there's an information surplus. The teams have capacity for tighter coordination that the architecture isn't using. Features that cross the module boundary are delivered slower than they could be, because unnecessary abstraction layers impose overhead. The teams respond rationally: they tighten the coupling to use the available channel capacity.
In both cases, the architecture moves toward equilibrium with the org chart. Conway's Law is the equilibrium state.
The convergence rate is governed by the magnitude of the mismatch. Large mismatches — where the coupling dramatically exceeds or falls short of the channel capacity — create intense pressure and converge quickly. Small mismatches create gentle pressure and can persist for months. This explains the observation that reorgs produce rapid surface-level convergence (weeks) but slow deep-structural convergence (months to years): the surface-level mismatches are large and immediately painful, while the deep-structural mismatches are smaller and tolerable until accumulated information debt makes them visible.
There's an elegant analogy to thermodynamics here. A system far from equilibrium moves toward it rapidly; a system near equilibrium approaches it asymptotically. The "temperature" in this analogy is the rate of feature development — the faster you ship features, the more information flows through the channels, the faster mismatches surface, and the faster the architecture converges. A codebase in maintenance mode can sustain Conway violations for years because so little information crosses the misaligned boundaries. A codebase under active development will converge in months.
This also explains why the most dramatic Conway effects appear in the highest-velocity teams. Startups that double in headcount every six months see their architecture restructure at an almost biological pace — not because startups are bad at architecture, but because the high velocity of feature work pumps information through every channel at maximum rate, exposing mismatches and driving convergence with extraordinary speed. The architecture is a real-time reflection of the organization because there's no slack in the system to sustain divergence.
Twelve engineers, twenty-eight channels, and an inevitable split
There's a second information-theoretic constraint that reinforces Conway's Law: Dunbar's number.
Robin Dunbar, an anthropologist studying primate social groups, found that the size of the neocortex correlates with the maximum size of stable social groups across primate species. For humans, this limit is approximately 150 — the number of people with whom a person can maintain a stable social relationship. Below that number, groups can self-organize through informal communication. Above it, formal hierarchies become necessary.
For software teams, the relevant Dunbar threshold is lower. The "working group" limit — the number of people who can maintain close enough communication for tightly-coupled collaboration — is roughly 7-12. This maps directly to the typical team size in software engineering, and it's not a coincidence.
A team of 8 people produces a communication graph of 28 channels (8 × 7 / 2). Each channel has finite capacity. The team's total information bandwidth is the sum of these channels. As the team grows, the number of channels grows quadratically while each individual's capacity remains fixed. At some point — typically between 8 and 12 people — the total information demand exceeds the available bandwidth, and the team either splits or develops informal sub-teams that function as separate communication clusters.

When a team splits, the communication bandwidth between the new sub-teams drops dramatically — from high-capacity (same standup, shared context) to medium-capacity (separate standups, periodic sync meetings). And the architecture follows. The modules owned by the sub-teams begin decoupling. Interfaces formalize. Shared code forks. Conway's Law operates at every scale, from the organization level down to the team level, because the information-theoretic constraint operates at every scale.
I've watched this happen twice with particular clarity. In both cases, a team of 12-14 engineers was split into two teams of 6-7, and within four months the monolithic module they shared had developed an internal seam that eventually became a formal service boundary. Nobody designed the seam. The seam formed where the communication bandwidth dropped — exactly where information theory predicts it would.
The second case is particularly instructive because I tracked it with data. A team of 13 engineers working on a claims processing module was split into a "fast track" team (6 people handling automated claims) and a "complex track" team (7 people handling manual adjudication). Before the split, the claims module had one namespace, one set of shared services, and no internal boundaries. I mapped the module dependency graph at the time of the split, then again at one month, three months, and six months.
At one month, the code was still structurally identical. Both teams were committing to the same files, using the same services. The only visible change was in the git log: commits were increasingly authored by one team or the other, rarely both.
At three months, an internal seam had appeared. The fast-track team had introduced a FastTrackClaimProcessor that bypassed three of the shared services. The complex-track team had added fields to the shared Claim entity that the fast-track code didn't use. Shared utility classes had grown if/else branches where one path served fast-track logic and the other served complex-track logic.
At six months, the seam was a canyon. The teams were discussing "the fast-track service" and "the complex-track service" as if they were separate systems, even though they still shared a database and a deployment pipeline. The formal service split happened at month eight. By then, it was just making official what the code had already decided.
I remember the moment I understood what I was watching. It was a standup, both teams in the same room, and someone from the fast-track side said "our service" — casually, without emphasis, the way you'd say "my desk" or "our kitchen." The architecture had already split in their heads. The code was just catching up.
The mathematical signature was unmistakable. The communication channels within each sub-team had remained high (same standup, same Slack channel, same sprint board). The channel between the sub-teams had dropped to a weekly 30-minute sync meeting — roughly a 90% reduction in bandwidth. And the architecture had followed, module by module, until the coupling between the two halves matched the drastically reduced channel capacity.
Refactor the org chart, not the codebase
If the architecture is determined by the org chart — if Conway's Law is a physical constraint rather than a tendency — then the implications for how we design both organizations and systems are profound.
The Inverse Conway Maneuver
The most actionable implication is what Thoughtworks calls the "Inverse Conway Maneuver": instead of designing an architecture and hoping the organization conforms, design the organization to emit the architecture you want.
If you want microservices, organize into small, autonomous teams with clear domain boundaries and limited cross-team communication channels. The architecture will follow.
If you want a well-structured monolith with clean module boundaries, organize into teams aligned to those modules with high internal communication and formalized cross-module interfaces. The architecture will follow.
If you want a big ball of mud, organize everyone into one large team with no internal boundaries. The architecture will follow.
The corollary is less obvious but equally powerful: if you inherit an architecture you don't like, stop trying to refactor the code. Refactor the organization. I've watched teams spend eighteen months attempting to decompose a monolith into microservices while the organizational structure remained a single large engineering department with shared standups and a unified backlog. The refactoring kept failing — not because the engineers lacked skill, but because the communication channels kept pulling the modules back together. Shared understanding made shared code natural. Independent modules required independent teams, and the organization hadn't made that investment.
When the company eventually split the department into domain-aligned squads — each with its own backlog, its own standups, its own deployment pipeline — the decomposition that had resisted eighteen months of deliberate effort happened on its own within six months. The new teams naturally wanted boundaries around their code. They naturally wanted independent deployability. They naturally reduced cross-team coupling because cross-team coordination was now expensive. The architecture followed the channels.
This isn't cynicism. It's physics. You cannot have a clean architecture across a messy organizational boundary, because the communication channel can't carry the information required for cleanliness. You cannot have a tightly-integrated system across loosely-connected teams, because the bandwidth isn't there.
The anti-pattern: architectural ambition exceeding organizational bandwidth
The most common Conway's Law violation I see is what I call architectural overreach — designing an architecture that requires more cross-team communication bandwidth than the organization provides.
The classic example: a microservices architecture adopted by an organization where all the teams sit in the same room and share a single backlog. The architecture says "independent services with clean APIs." The organization says "everyone talks to everyone about everything." Conway's Law predicts the result: the services will develop tight coupling, shared databases will appear, and the "micro" services will gradually converge toward a distributed monolith. Not because the engineers are lazy, but because the high-bandwidth communication channels encourage — and the architecture eventually requires — tight coordination.
The reverse is equally common: a monolithic architecture maintained by an organization that has grown into multiple teams across multiple locations. The architecture says "one system, tightly coordinated." The organization says "separate groups with limited communication." Conway's Law predicts: the monolith will develop internal fissures along team boundaries, with different sections using different patterns, different conventions, and increasingly incompatible assumptions. Not because anyone chose to fragment it, but because the fragmented communication channels can't sustain the unified coordination a monolith requires.
The communication budget and the reorg prediction
This suggests two practical planning tools.
The first is the communication budget. For any proposed architecture, calculate the communication bandwidth required to maintain it — how many cross-team interfaces exist, how frequently they need coordination, how complex the shared contracts are. Then calculate the bandwidth the organization actually provides. If the required exceeds the available, the architecture will degrade until they match. You can fight this with heroic coordination, exhaustive documentation, and constant firefighting. But you're fighting an information-theoretic constraint, and the organization always wins.
The second is the reorg prediction. If you know a reorg is coming, you can predict the architectural changes that will follow. Map the current architecture. Map the proposed org chart. Every module boundary that crosses a new team boundary will decouple. Every currently-separate module that falls under a single team will couple. The timeline is 6-18 months.
I've used this once with full intentionality. In 2021, I learned a platform reorganization was coming three months before it was announced. Two teams — one owning a policy engine, one owning billing — were going to merge under a single manager. I told both teams to start simplifying the interface. We replaced versioned REST contracts with shared domain events. We merged CI/CD pipelines. We moved data stores onto the same cluster. By the time the reorg was official, the architecture was already halfway there. The convergence that normally takes 12-18 months took four.
Matthew Skelton and Manuel Pais formalized this thinking in Team Topologies (2019) — four team types, three interaction modes, essentially an applied engineering manual for the Inverse Conway Maneuver. What the information-theoretic lens adds is a prediction mechanism. Skelton and Pais describe what team shapes produce what architectures. The channel capacity model explains why, and lets you calculate the cost of diverging from the natural shape. If your team topology says "collaboration mode" but your actual bandwidth says "X-as-a-Service," you can predict which one will win. The bandwidth always wins.
Of course, any model this clean invites suspicion — and it should.
Culture overrides channels. Some organizations develop cultures that partially counteract Conway's Law — strong documentation practices, rigorous interface design standards, architectural review boards. These mechanisms effectively increase the communication bandwidth across organizational boundaries by encoding information in persistent artifacts (design documents, API specs, architecture decision records) rather than relying solely on interpersonal channels. The information-theoretic model predicts that these organizations will have weaker Conway isomorphism, and they do. But the cultural mechanisms are expensive to maintain, and they degrade over time if not actively reinforced.
Open-source complicates the model. Open-source projects often produce architectures that don't match their organizational structure, because the "organization" is fluid — contributors come and go, roles are informal, and communication happens through asynchronous channels (issues, PRs, mailing lists) rather than organizational hierarchy. The information-theoretic model needs extension to handle networks with dynamic topology and asynchronous channels. The 2012 Harvard study found that open-source projects still exhibit Conway-like effects, but the correlation is weaker than in traditional organizations.
Yet even open-source partially confirms the model. Look at the Linux kernel's subsystem structure: it precisely mirrors the maintainer hierarchy. The networking subsystem has its own architectural character because it has its own maintainer community with its own communication norms. The filesystems subsystem looks different because its maintainer community operates differently. Linus Torvalds sits at the top, and the fact that all major architectural decisions flow through him (or his lieutenants) explains why the kernel has remained more architecturally coherent than most commercial codebases of comparable size. The organization is informal, but the communication channels are real, and the architecture reflects them.
Technical constraints create independent pressure. Sometimes the technology forces an architecture that doesn't match the org chart. A database's consistency requirements might force tight coupling between modules that different teams own. A regulatory requirement might force isolation between modules that the same team builds. These technical constraints create counter-pressure against Conway's Law, and the resulting architecture is a compromise between organizational and technical forces. The information-theoretic model captures the organizational force but not the technical one.
I've seen this most sharply with shared databases. Two teams that communicate rarely but share a PostgreSQL instance will develop tighter module coupling than their channel capacity would predict, because the database schema acts as a shadow communication channel — changes to one team's tables affect the other team's queries. The architecture isn't matching the org chart; it's matching the effective communication graph, which includes both human and technical channels. This suggests the model needs refinement: the communication matrix should include not just interpersonal channels but also all information-carrying artifacts that teams share — databases, message queues, configuration files, even deployment pipelines.
Scale introduces nonlinearity. The model assumes a roughly linear relationship between channel capacity and architectural coupling. In practice, at very large scales (hundreds of teams, thousands of engineers), the relationship becomes nonlinear. Organizations develop hierarchical communication structures — team leads talk to department leads who talk to division leads — and the architecture develops corresponding hierarchical layers. The isomorphism still holds, but it's an isomorphism between hierarchies, not flat graphs. This is why very large systems tend to develop platform layers, shared infrastructure layers, and domain layers that map to the organizational hierarchy rather than to direct team-to-team relationships.
Conway's Law doesn't tell you what architecture to build. It tells you what architecture you will build, whether you intend to or not. That distinction makes all the difference.
We've already seen what happens when codebases grow, break, corrode, and depreciate. Each observation revealed a natural force acting on production systems — forces borrowed from biology, physics, chemistry, and economics.
This fifth observation shifts from forces of destruction to forces of construction. Not what tears systems down, but what shapes them in the first place. And the answer is simultaneously obvious and profound: the architecture of a software system is determined by the communication structure of the organization that builds it. Not influenced. Not correlated. Determined — within the margins that culture and technology allow.
The information-theoretic framing makes this precise. Every organizational boundary is a bandwidth constraint. Every bandwidth constraint is an architectural constraint. The architecture converges to the communication graph because it must — any architecture that requires more information transfer than the channels provide will accumulate information debt until it degrades to match.
This is, in many ways, the most actionable observation in the series so far. You cannot control how fast code corrodes. You cannot control when a phase transition will occur. You cannot control the depreciation rate of a technology bet. But you can control the organizational structure. You can design the communication channels. And if Conway's Law is a law — and fifty-nine years of evidence says it is — then designing the organization is designing the architecture.
There's something both humbling and liberating in this realization. Humbling because it means that the months spent on architecture documents and system design reviews are, to a first approximation, decorative. The real architecture was decided when someone drew the org chart. Liberating because it means that architectural change doesn't require heroic refactoring marathons. It requires a reorganization — which is politically harder but technically simpler. Move the people, and the code follows. It always does.
The most important architecture diagram in your company isn't in the technical documentation. It's the org chart. And every time someone changes that chart, they're making an architecture decision — whether they know it or not.
Draw your org chart. Draw your architecture. Hold them side by side. If they don't match, one of them is lying — and it isn't the org chart.